Gremlin - как объединить вершины, чтобы объединить их свойства без явного перечисления свойств?
Предыстория: я пытаюсь реализовать БД с временной версией, используя этот подход, используя gremlin (tinkerpop v3).
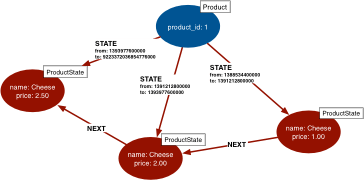
Я хочу получить последний узел состояния (красным) для данного узла идентификации (синим цветом) (связанный краем "состояния", который содержит диапазон меток времени), но я хочу вернуть один агрегированный объект, который содержит идентификатор (cid) из узла идентификации и всех свойств из узла состояния, но я не хочу перечислять их явно. (8640000000000000 - это мой способ указывать отсутствие даты "до" - то есть край является текущим - немного отличается от показанного изображения).
Я получил это далеко:
:> g.V().hasLabel('product').
as('cid').
outE('state').
has('to', 8640000000000000).
inV().
as('name').
as('price').
select('cid', 'name','price').
by('cid').
by('name').
by('price')
=>{cid=1, name="Cheese", price=2.50}
=>{cid=2, name="Ham", price=5.00}
но, как вы можете видеть, я должен перечислить свойства узла 'state' - в приведенном выше примере свойства name и price продукта. Но это будет применяться к любому объекту домена, поэтому я не хочу постоянно перечислять свойства. Я мог бы выполнить запрос до этого, чтобы получить свойства, но я не думаю, что мне нужно было бы запускать 2 запроса и иметь накладные расходы 2 циклов. Я смотрел на "совокупность", "объединение", "сворачивание" и т. Д., Но, похоже, ничего не делает.
Есть идеи?
===================
Изменить: Основываясь на ответе Даниэля (который не совсем то, что я хочу, банкомат) я собираюсь использовать его пример графика. В 'modernGraph' люди-создают-> софт. Если я бегу:
> g.V().hasLabel('person').valueMap()
==>[name:[marko], age:[29]]
==>[name:[vadas], age:[27]]
==>[name:[josh], age:[32]]
==>[name:[peter], age:[35]]
тогда результаты представляют собой список сущностей со свойствами. Я хочу, исходя из предположения, что человек может создать только одну часть программного обеспечения (хотя, будем надеяться, мы увидим, как это можно открыть позже для списков созданных программ), чтобы включить свойство "языка" созданного программного обеспечения в возвращаемая сущность для получения:
> <run some query here>
==>[name:[marko], age:[29], lang:[java]]
==>[name:[vadas], age:[27], lang:[java]]
==>[name:[josh], age:[32], lang:[java]]
==>[name:[peter], age:[35], lang:[java]]
На данный момент лучшим предложением на данный момент является следующее:
> g.V().hasLabel('person').union(identity(), out("created")).valueMap().unfold().group().by {it.getKey()}.by {it.getValue()}
==>[name:[marko, lop, lop, lop, vadas, josh, ripple, peter], lang:[java, java, java, java], age:[29, 27, 32, 35]]
Надеюсь, это понятнее. Если нет, пожалуйста, дайте мне знать.
3 ответа
Поскольку вы не предоставили мне примерный график, я буду использовать игрушечный график TinkerPop, чтобы показать, как это делается.
Предположим, вы хотите объединить marko а также lop:
gremlin> g = TinkerFactory.createModern().traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V(1).valueMap()
==>[name:[marko],age:[29]]
gremlin> g.V(1).out("created").valueMap()
==>[name:[lop],lang:[java]]
Обратите внимание, что есть два name свойства и в теории вы не сможете предсказать, какие name превращает это в ваш объединенный результат; однако это не кажется проблемой в вашем графике.
Получите свойства для обеих вершин:
gremlin> g.V(1).union(identity(), out("created")).valueMap()
==>[name:[marko],age:[29]]
==>[name:[lop],lang:[java]]
Слить их:
gremlin> g.V(1).union(identity(), out("created")).valueMap().
unfold().group().by(select(keys)).by(select(values))
==>[name:[lop],lang:[java],age:[29]]
ОБНОВИТЬ
Спасибо за добавленный пример вывода. Это значительно облегчает поиск решения (хотя я думаю, что ваш вывод содержит ошибки; vadas ничего не создал).
gremlin> g.V().hasLabel("person").
filter(outE("created")).map(
union(valueMap(),
outE("created").limit(1).inV().valueMap("lang")).
unfold().group().by {it.getKey()}.by {it.getValue()})
==>[name:[marko], lang:[java], age:[29]]
==>[name:[josh], lang:[java], age:[32]]
==>[name:[peter], lang:[java], age:[35]]
Объединение свойств ребер и вершин с использованием gremlin java DSL:
g.V().has('User', 'id', userDbId).outE(Edges.TWEETS)
.union(__.identity().valueMap(), __.inV().valueMap())
.unfold().group().by(__.select(Column.keys)).by(__.select(Column.values))
.map(v -> converter.toTweet((Map) v.get())).toList();
Спасибо за ответ отDaniel Kuppitzиyouhansэто дало мне основное представление о решении проблемы. Но позже я узнал, что решение не работает для нескольких строк. Требуется иметьlocalшаг для обработки нескольких строк. Модифицированный запрос гремлина будет выглядеть так:
g.V()
.local(
__.union(__.valueMap(), __.outE().inV().valueMap())
.unfold().group().by(__.select(Column.keys)).by(__.select(Column.values))
)
Это ограничит область действия объединения и группировки одной строкой.
Если вы можете работать с пользовательским DSL, создайте собственный DSL с java, как этот.
public default GraphTraversal<S, LinkedHashMap> unpackMaps(){
GraphTraversal<S, LinkedHashMap> it = map(x -> {
LinkedHashMap mapSource = (LinkedHashMap) x.get();
LinkedHashMap mapDest = new LinkedHashMap();
mapSource.keySet().stream().forEach(key->{
Object obj = mapSource.get(key);
if (obj instanceof LinkedHashMap) {
LinkedHashMap childMap = (LinkedHashMap) obj;
childMap.keySet().iterator().forEachRemaining( key_child ->
mapDest.put(key_child,childMap.get(key_child)
));
} else
mapDest.put(key,obj);
});
return mapDest;
});
return it;
}
и использовать его свободно, как
g.V().as("s")
.valueMap().as("value_map_0")
.select("s").outE("INFO1").inV().valueMap().as("value_map_1")
.select("s").outE("INFO2").inV().valueMap().as("value_map_2")
.select("s").outE("INFO3").inV().valueMap().as("value_map_3")
.select("s").local(__.outE("INFO1").count()).as("value_1")
.select("s").outE("INFO1").inV().value("name").as("value_2")
.project("val_map1","val_map2","val_map3","val1","val2")
.by(__.select("value_map_1"))
.by(__.select("value_map_2"))
.by(__.select("value_1"))
.by(__.select("value_2"))
.unpackMaps()
результаты в строки с
map1_val1, map1_val2,.... ,map2_va1, map2_val2....,value1, value2
Это может обрабатывать смесь значений и карт значений естественным способом гремлина.