Дизайн базы данных Facebook?
Мне всегда было интересно, как Facebook разработал дружеское <-> отношение пользователя.
Я полагаю, что таблица пользователя выглядит примерно так:
user_email PK
user_id PK
password
Я рисую таблицу с данными пользователя (пол, возраст и т. Д., Связанные с электронной почтой пользователя, я бы предположил).
Как он связывает всех друзей с этим пользователем?
Что-то вроде этого?
user_id
friend_id_1
friend_id_2
friend_id_3
friend_id_N
Возможно нет. Потому что количество пользователей неизвестно и будет расширяться.
13 ответов
Сохраните таблицу друзей, которая содержит идентификатор пользователя, а затем идентификатор друга (мы назовем его FriendID). Оба столбца будут внешними ключами обратно в таблицу Users.
Несколько полезный пример:
Table Name: User
Columns:
UserID PK
EmailAddress
Password
Gender
DOB
Location
TableName: Friends
Columns:
UserID PK FK
FriendID PK FK
(This table features a composite primary key made up of the two foreign
keys, both pointing back to the user table. One ID will point to the
logged in user, the other ID will point to the individual friend
of that user)
Пример использования:
Table User
--------------
UserID EmailAddress Password Gender DOB Location
------------------------------------------------------
1 bob@bob.com bobbie M 1/1/2009 New York City
2 jon@jon.com jonathan M 2/2/2008 Los Angeles
3 joe@joe.com joseph M 1/2/2007 Pittsburgh
Table Friends
---------------
UserID FriendID
----------------
1 2
1 3
2 3
Это покажет, что Боб дружит как с Джоном, так и с Джо, и что Джон также дружит с Джо. В этом примере мы будем предполагать, что дружба всегда двухсторонняя, поэтому вам не потребуется строка в таблице, такая как (2,1) или (3,2), потому что они уже представлены в другом направлении. Для примеров, где дружба или другие отношения явно не являются двусторонними, вам также необходимо иметь эти строки, чтобы указать двусторонние отношения.
TL;DR:
Они используют стековую архитектуру с кэшированными графами для всего, что находится выше дна MySQL их стека.
Длинный ответ:
Я сам провел некоторые исследования по этому вопросу, потому что мне было любопытно, как они обрабатывают огромное количество данных и быстро их ищут. Я видел людей, жалующихся на то, что пользовательские скрипты в социальных сетях становятся медленнее, когда растет пользовательская база. После того, как я провел сравнительный анализ всего лишь с 10 тысячами пользователей и 2,5 миллионами соединений с друзьями - даже не пытаясь беспокоиться о групповых разрешениях, лайках и постах на стене - быстро оказалось, что этот подход ошибочен. Поэтому я потратил некоторое время на поиск в Интернете, как это сделать лучше, и наткнулся на эту официальную статью в Facebook:
Я действительно рекомендую вам посмотреть презентацию по первой ссылке выше, прежде чем продолжить чтение. Это, вероятно, лучшее объяснение того, как FB работает за кулисами, которое вы можете найти.
Видео и статья рассказывают о нескольких вещах:
- Они используют MySQL в самом низу своего стека
- Над базой данных SQL находится слой TAO, который содержит как минимум два уровня кэширования и использует графики для описания соединений.
- Я не мог найти что-нибудь о том, какое программное обеспечение / БД они фактически используют для своих кэшированных графов
Давайте посмотрим на это, дружеские связи вверху слева:
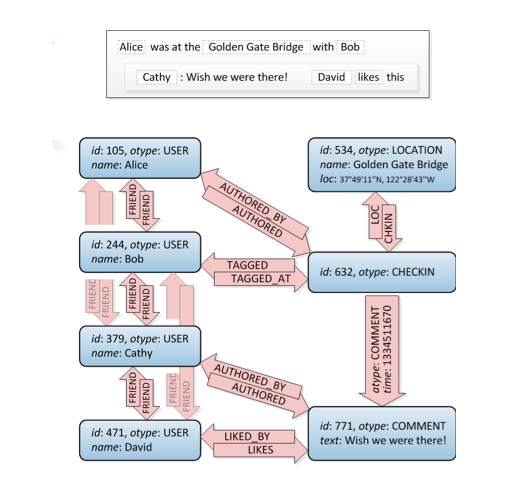
Ну, это график.:) Он не говорит вам, как построить его в SQL, есть несколько способов сделать это, но у этого сайта есть много разных подходов. Внимание: учтите, что реляционная БД - это то, чем она является: считается, что она хранит нормализованные данные, а не структуру графа. Так что он не будет работать так же хорошо, как специализированная графовая база данных.
Также учтите, что вам нужно выполнять более сложные запросы, чем просто друзья друзей, например, когда вы хотите отфильтровать все местоположения вокруг заданной координаты, которые нравятся вам и вашим друзьям друзей. График является идеальным решением здесь.
Я не могу рассказать вам, как построить его так, чтобы он работал хорошо, но он явно требует проб и ошибок и сравнительного анализа.
Вот мой неутешительный тест для просто находок друзей друзей:
Схема БД:
CREATE TABLE IF NOT EXISTS `friends` (
`id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`friend_id` int(11) NOT NULL
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
Запрос друзей друзей:
(
select friend_id
from friends
where user_id = 1
) union (
select distinct ff.friend_id
from
friends f
join friends ff on ff.user_id = f.friend_id
where f.user_id = 1
)
Я действительно рекомендую вам создать несколько примеров данных с минимум 10 тысячами пользовательских записей, каждая из которых имеет как минимум 250 соединений с друзьями, а затем выполнить этот запрос. На моем компьютере (i7 4770k, SSD, 16 ГБ ОЗУ) результат составил ~0, 18 секунды для этого запроса. Может быть, это можно оптимизировать, я не гений БД (предложения приветствуются). Однако, если это линейное масштабирование, у вас уже 1,8 секунды для всего 100 тыс. Пользователей, 18 секунд для 1 миллиона пользователей.
Это может звучать нормально для пользователей ~100 тыс., Но учтите, что вы только что выбрали друзей друзей и не сделали более сложный запрос типа " показать мне только сообщения от друзей друзей + выполнить проверку разрешений, если мне разрешено или НЕ разрешено" чтобы увидеть некоторые из них + выполнить подзапрос, чтобы проверить, понравился ли мне какой-либо из них ". Вы хотите, чтобы БД проверила, понравился ли вам пост или нет, или вам придется делать это в коде. Также учтите, что это не единственный запрос, который вы выполняете, и что у вас есть более чем активный пользователь одновременно на более или менее популярном сайте.
Я думаю, что мой ответ отвечает на вопрос, как Facebook очень хорошо спроектировал отношения с друзьями, но мне жаль, что я не могу рассказать вам, как реализовать их так, чтобы они работали быстро. Внедрить социальную сеть легко, но убедиться, что она работает хорошо, явно нет - ИМХО.
Я начал экспериментировать с OrientDB, чтобы выполнять граф-запросы и сопоставлять свои ребра с базовой базой данных SQL. Если я когда-нибудь это сделаю, я напишу статью об этом.
Взгляните на следующую схему базы данных, разработанную Анатолием Любарским в обратном порядке:

Лучше всего, что они создали структуру графа. Узлы - это пользователи, а "дружба" - это ребра.
Держите одну таблицу пользователей, сохраняйте другую таблицу ребер. Затем вы можете сохранить данные о границах, таких как "день, когда они стали друзьями" и "одобренный статус" и т. Д.
Скорее всего, это отношение многих ко многим:
FriendList (таблица)
user_id -> users.user_id
friend_id -> users.user_id
friendVisibilityLevel
РЕДАКТИРОВАТЬ
Таблица пользователя, вероятно, не имеет user_email в качестве PK, хотя, возможно, в качестве уникального ключа.
пользователи (таблица)
user_id PK
user_email
password
Посмотрите на эти статьи, описывающие, как создаются LinkedIn и Digg:
- http://hurvitz.org/blog/2008/06/linkedin-architecture
- http://highscalability.com/scaling-digg-and-other-web-applications
Также могут быть полезны "Большие данные: точки зрения от команды данных Facebook":
Также есть статья, в которой говорится о нереляционных базах данных и о том, как они используются некоторыми компаниями:
http://www.readwriteweb.com/archives/is_the_relational_database_doomed.php
Вы увидите, что эти компании имеют дело с хранилищами данных, многораздельными базами данных, кэшированием данных и другими концепциями более высокого уровня, чем большинство из нас никогда не сталкиваются на ежедневной основе. Или, по крайней мере, может быть, мы не знаем, что мы делаем.
В первых двух статьях есть много ссылок, которые помогут вам лучше понять.
ОБНОВЛЕНИЕ 20/20/2014
Мурат Демирбас написал резюме на
- TAO: распределенное хранилище данных Facebook для социального графа (ATC'13)
- F4: система хранения больших двоичных объектов Facebook (OSDI'14)
http://muratbuffalo.blogspot.com/2014/10/facebooks-software-architecture.html
НТН
Невозможно получить данные из RDBMS для данных друзей пользователя для данных, которые пересекают более полумиллиарда в постоянное время, поэтому Facebook реализовал это, используя хеш-базу данных (без SQL), и они открыли базу данных под названием Cassandra.
Таким образом, каждый пользователь имеет свой собственный ключ и данные друзей в очереди; чтобы узнать, как работает Кассандра, посмотрите на это:
В этой недавней публикации в июне 2013 года подробно объясняется переход от баз данных отношений к объектам с ассоциациями для некоторых типов данных.
https://www.facebook.com/notes/facebook-engineering/tao-the-power-of-the-graph/10151525983993920
Более длинная статья доступна по адресу https://www.usenix.org/conference/atc13/tao-facebook's-distributed-data-store-social-graph
Тип графической базы данных: http://components.neo4j.org/neo4j-examples/1.2-SNAPSHOT/social-network.html
Это не относится к реляционным базам данных.
Google для графических баз данных.
Вы ищете внешние ключи. По сути, вы не можете иметь массив в базе данных, если у него нет собственной таблицы.
Пример схемы:
Таблица пользователей
userID PK
другие данные
Стол друзей
userID - FK для таблицы пользователей, представляющая пользователя, у которого есть друг.
friendID - FK to Таблица пользователей, представляющая идентификатор пользователя друга
Помните, что таблицы базы данных предназначены для роста по вертикали (больше строк), а не по горизонтали (больше столбцов)
Вероятно, есть таблица, в которой хранится отношение друга <->, скажем, "frnd_list", имеющее поля "user_id", "frnd_id".
Всякий раз, когда пользователь добавляет другого пользователя в друзья, создаются две новые строки.
Например, предположим, что мой идентификатор 'deep9c', и я добавляю пользователя с идентификатором 'akash3b' в качестве моего друга, затем в таблице "frnd_list" создаются две новые строки со значениями ('deep9c','akash3b') и ('akash3b) ",'deep9c').
Теперь, при отображении списка друзей для конкретного пользователя, простой sql сделает это: "выберите frnd_id из списка frnd_list где user_id=" где - идентификатор пользователя, вошедшего в систему (хранится как атрибут сеанса).
Что касается производительности таблицы "многие ко многим", если у вас есть 2 32-разрядных числа, связывающих идентификаторы пользователей, базовое хранилище данных для 200 000 000 пользователей, в среднем 200 друзей на человека, составляет чуть менее 300 ГБ.
Очевидно, что вам потребуется разделение и индексация, и вы не собираетесь хранить это в памяти для всех пользователей.