Несколько входов с MRJob
Я пытаюсь научиться использовать Python API Yelp для MapReduce, MRJob. Их простой пример счетчика слов имеет смысл, но мне любопытно, как можно было бы обрабатывать приложение, включающее несколько входов. Например, вместо того, чтобы просто считать слова в документе, умножая вектор на матрицу. Я пришел с этим решением, которое работает, но чувствует себя глупо:
class MatrixVectMultiplyTast(MRJob):
def multiply(self,key,line):
line = map(float,line.split(" "))
v,col = line[-1],line[:-1]
for i in xrange(len(col)):
yield i,col[i]*v
def sum(self,i,occurrences):
yield i,sum(occurrences)
def steps(self):
return [self.mr (self.multiply,self.sum),]
if __name__=="__main__":
MatrixVectMultiplyTast.run()
Этот код запускается ./matrix.py < input.txt и причина того, что это работает, состоит в том, что матрица хранится в input.txt по столбцам с соответствующим значением вектора в конце строки.
Итак, следующая матрица и вектор:

представлены как input.txt как:
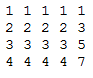
Короче говоря, как бы я мог более естественно хранить матрицу и вектор в отдельных файлах и передавать их в MRJob?
4 ответа
Если вам нужно обработать ваши необработанные данные с использованием другого (или того же набора данных row_i, row_j), вы можете:
1) Создайте корзину S3 для хранения копии ваших данных. Передайте местоположение этой копии вашему классу задач, например self.options.bucket и self.options.my_datafile_copy_location в приведенном ниже коде. Предостережение: К сожалению, кажется, что весь файл должен быть "загружен" на компьютеры задач перед обработкой. Если подключение прерывается или занимает слишком много времени для загрузки, это задание может завершиться ошибкой. Вот код Python/MRJob, чтобы сделать это.
Поместите это в вашу функцию отображения:
d1 = line1.split('\t', 1)
v1, col1 = d1[0], d1[1]
conn = boto.connect_s3(aws_access_key_id=<AWS_ACCESS_KEY_ID>, aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>)
bucket = conn.get_bucket(self.options.bucket) # bucket = conn.get_bucket(MY_UNIQUE_BUCKET_NAME_AS_STRING)
data_copy = bucket.get_key(self.options.my_datafile_copy_location).get_contents_as_string().rstrip()
### CAVEAT: Needs to get the whole file before processing the rest.
for line2 in data_copy.split('\n'):
d2 = line2.split('\t', 1)
v2, col2 = d2[0], d2[1]
## Now, insert code to do any operations between v1 and v2 (or c1 and c2) here:
yield <your output key, value pairs>
conn.close()
2) Создайте домен SimpleDB и храните там все свои данные. Читайте здесь на boto и SimpleDB: http://code.google.com/p/boto/wiki/SimpleDbIntro
Ваш код Mapper будет выглядеть так:
dline = dline.strip()
d0 = dline.split('\t', 1)
v1, c1 = d0[0], d0[1]
sdb = boto.connect_sdb(aws_access_key_id=<AWS_ACCESS_KEY>, aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>)
domain = sdb.get_domain(MY_DOMAIN_STRING_NAME)
for item in domain:
v2, c2 = item.name, item['column']
## Now, insert code to do any operations between v1 and v2 (or c1 and c2) here:
yield <your output key, value pairs>
sdb.close()
Этот второй вариант может работать лучше, если у вас очень большие объемы данных, поскольку он может выполнять запросы для каждой строки данных, а не для всего объема сразу. Помните, что значения SimpleDB могут иметь длину не более 1024 символов, поэтому вам может потребоваться сжать / распаковать каким-либо методом, если ваши значения данных длиннее этого.
Вот как я использую несколько входов и в зависимости от имени файла делаю подходящие изменения на этапе отображения.
Бегущая программа:
from mrjob.hadoop import *
#Define all arguments
os.environ['HADOOP_HOME'] = '/opt/cloudera/parcels/CDH/lib/hadoop/'
print "HADOOP HOME is now set to : %s" % (str(os.environ.get('HADOOP_HOME')))
job_running_time = datetime.datetime.now().strftime('%Y-%m-%d_%H_%M_%S')
hadoop_bin = '/usr/bin/hadoop'
mode = 'hadoop'
hs = HadoopFilesystem([hadoop_bin])
input_file_names = ["hdfs:///app/input_file1/","hdfs:///app/input_file2/"]
aargs = ['-r',mode,'--jobconf','mapred.job.name=JobName','--jobconf','mapred.reduce.tasks=3','--no-output','--hadoop-bin',hadoop_bin]
aargs.extend(input_file_names)
aargs.extend(['-o',output_dir])
print aargs
status_file = True
mr_job = MRJob(args=aargs)
with mr_job.make_runner() as runner:
runner.run()
os.environ['HADOOP_HOME'] = ''
print "HADOOP HOME is now set to : %s" % (str(os.environ.get('HADOOP_HOME')))
Класс MRJob:
class MR_Job(MRJob):
DEFAULT_OUTPUT_PROTOCOL = 'repr_value'
def mapper(self, _, line):
"""
This function reads lines from file.
"""
try:
#Need to clean email.
input_file_name = get_jobconf_value('map.input.file').split('/')[-2]
"""
Mapper code
"""
except Exception, e:
print e
def reducer(self, email_id,visitor_id__date_time):
try:
"""
Reducer Code
"""
except:
pass
if __name__ == '__main__':
MRV_Email.run()
Фактический ответ на ваш вопрос заключается в том, что mrjob еще не поддерживает шаблон потокового соединения hadoop, который должен прочитать переменную среды map_input_file (которая предоставляет свойство map.input.file), чтобы определить, с каким типом файла вы имеете дело. на его пути и / или имени.
Возможно, вам все же удастся это осуществить, если вы сможете легко определить, просто прочитав сами данные, к какому типу они относятся, как показано в этой статье:
Однако это не всегда возможно...
В противном случае myjob выглядит фантастически, и я хотел бы, чтобы они могли добавить поддержку для этого в будущем. До тех пор это для меня довольно много.
В MrJob Fundumentals говорится:
Вы можете передать несколько входных файлов, смешанных со стандартным вводом (с помощью символа -):
$ python my_job.py input1.txt input2.txt - < input3.txt
Насколько я понимаю, вы не будете использовать MrJob, если не захотите использовать кластер Hadoop или сервисы Hadoop от Amazon, даже если в этом примере используется работа с локальными файлами.
MrJob в принципе использует потоковую передачу Hadoop для отправки задания.
Это означает, что все входные данные, указанные в виде файлов или папок из Hadoop, передаются в преобразователь, а последующие результаты - в редуктор. Весь маппер получает фрагмент ввода и считает все входные данные схематически одинаковыми, так что он равномерно анализирует и обрабатывает ключ, значение для каждого фрагмента данных.
Исходя из этого понимания, входы схематически совпадают с картографом. Единственный способ включить два разных схематических данных - это чередовать их в одном и том же файле таким образом, чтобы картограф мог понять, что является векторными данными, а какие - матричными данными.
You are actually doing it already.
Вы можете просто улучшить это, имея некоторый спецификатор, если строка является матричными или векторными данными. Как только вы видите векторные данные, к ним применяются предыдущие матричные данные.
matrix, 1, 2, ...
matrix, 2, 4, ...
vector, 3, 4, ...
matrix, 1, 2, ...
.....
Но процесс, который вы упомянули, работает хорошо. Вы должны иметь все данные схемы в одном файле.
Это все еще имеет проблемы, хотя. Карта K,V Reduce лучше работает, когда полная схема присутствует в одной строке и содержит полный блок обработки.
Насколько я понимаю, вы уже делаете это правильно, но я думаю, что Map-Reduce не является подходящим механизмом для такого рода данных. Я надеюсь, что кто-то прояснит это даже дальше, чем я мог.