Как синхронизировать доступ к базе данных в службе WCF?
Раньше я пользовался услугами WCF, и теперь у меня новый проект. Я все еще на стадии проектирования, и я подумал, как лучше всего справиться со следующим сценарием.
У меня будет несколько клиентов, одновременно подключающихся к моей службе WCF, использующих различные методы (рабочие контракты) в службе:
О. Некоторые из запущенных методов являются просто чистыми методами "чтения" (например, GetListOfCustomers).
B. Некоторые из запущенных методов являются сложными методами "чтения" (например, GetAllProductsByCustomerId). Подобные методы требуют получения клиента от БД, проверки чего-либо на нем, а затем получения всех продуктов, купленных им. (имеется в виду, что в этом методе есть 2 вызова базы данных).
C. Некоторые из них являются методами "Write" (например, "RemoveCustomer" или "SetProductOutOfStock").
У меня вопрос - как мне синхронизировать все эти вызовы, чтобы у меня не было проблем с параллелизмом?
Я не хочу, чтобы весь сервис обрабатывал вызовы последовательно, потому что это повредит производительности на стороне клиента (для некоторых вызовов может потребоваться 3-4 секунды для обработки). Так какое у меня решение?
Использовать один экземпляр для всех клиентов с несколькими потоками, а затем использовать объект блокировки? Не приведет ли это просто к тому, что он станет серийным?
Или мне нужен другой объект блокировки для "чтения" и другой объект блокировки для "записи"?
Или мне нужна блокировка для функций "запись" и некоторые другие функции для "чтения"?
Это мой первый вопрос о Stackru. Спасибо всем, кто может помочь!
Обновление: я собираюсь использовать 'Linq-To-SQL' в качестве ORM.
4 ответа
Вам не следует беспокоиться ни о проблемах согласованности данных, ни о параллелизме при выполнении запросов к базе данных. Если я правильно понял вашу ситуацию, все, что вам нужно, это убедиться, что вы используете транзакции последовательно, выполняя серию запросов к базе данных, которые вы хотите быть "атомарными". Я попытаюсь объяснить это на примере:
- Получить всех клиентов из базы данных.
- Для каждого клиента выполните запрос, обновив некоторые связанные данные.
В этом сценарии вы не хотите, чтобы вы попали в ситуацию, когда данные изменяются другим запросом после запроса от 1 возвращает и до всех запросов от 2 закончены. Например, если один из клиентов будет удален за это время, нет смысла обновлять связанные данные - это может даже привести к некоторым ошибкам.
Так что вам нужно просто поставить что-то вроде BEGIN TRANSACTION до 1 а также COMMIT после 2, Посмотрите точный синтаксис для используемого вами диалекта SQL.
Это гарантирует, что данные, с которыми вы работаете, не изменятся. Фактически, он будет заблокирован вашей транзакцией; и все другие запросы, которые могут работать с теми же данными, ожидают завершения вашей транзакции. Базы данных выполняют такую блокировку интеллектуально, всегда пытаясь заблокировать как можно меньше данных.
Вы разрабатываете для Интернета, и, следовательно, вам нужно принять параллелизм, выхода нет. Взятие блокировок и все это не очень хороший способ работы в сети, по моему мнению. Параллельный доступ произойдет, и вам нужно подумать о том, как бороться с ошибками параллелизма, а не предотвращать проблемы параллелизма. Любой механизм управления параллелизмом, созданный по сети, имеет ограниченное применение и сложен для правильной сборки.
У меня вопрос - как мне синхронизировать все эти вызовы, чтобы у меня не было проблем с параллелизмом?
Зачем вам нужно что-то синхронизировать? СУБД справляется с синхронизацией достаточно хорошо. Конечно, если вы знаете, что у вас будет много записей, которые приведут к снижению производительности чтения из-за блокировок, вам придется планировать это на архитектурном уровне, но это не имеет ничего общего с WCF. В этом случае, как писал Хью, CQRS может быть подходящим выбором, хотя трудно сказать без спецификации.
Я не хочу, чтобы весь сервис обрабатывал вызовы последовательно, потому что это повредит производительности на стороне клиента (для некоторых вызовов может потребоваться 3-4 секунды для обработки). Так какое у меня решение?
Затем используйте экземпляр PerCall и один или несколько параллелей, если можете. Посмотрите здесь подробности о комбинациях экземпляров и параллелизма.
Использовать один экземпляр для всех клиентов с несколькими потоками, а затем использовать объект блокировки? Разве это не приведет к тому, что вы станете серийным?
Один экземпляр создаст проблемы с параллелизмом, см. Статью, на которую я ссылался выше. Это в основном полезно, если вам нужен сервис Singleton.
ОБНОВИТЬ
В ответ на ваш комментарий: боюсь, я до сих пор не понимаю, откуда у вас проблемы с параллелизмом. Если вы беспокоитесь о службе WCF, просто избегайте использования одного экземпляра: наиболее масштабируемым вариантом является PerCall/Multiple.
Если вы спрашиваете себя, нужно ли вам рассматривать CQRS, не стесняйтесь читать статью Уди Даана, на которую я ссылался в другом комментарии. Имейте в виду, однако, что CQRS занимает некоторое время, чтобы уловить и добавляет сложности вашему проекту, который вам может понадобиться, а может и не понадобиться.
Я бы посоветовал не чрезмерно усложнять вашу архитектуру, для меня это звучит так, как будто правильной конфигурации инстансинга / параллелизма для ваших сервисов будет достаточно. Если вы не уверены, напишите несколько прототипов, имитирующих ожидаемую нагрузку для вашей системы. Лучше безопасно, чем потом сожалеть, особенно если это будет долгоживущее приложение.
Я предлагаю вам прочитать кое-что о CQRS, который является архитектурным паттерном, который каким-то образом решает проблемы, с которыми вы сталкиваетесь.
В качестве примера решения для вашей ситуации на следующей диаграмме показана архитектура CQRS, которая может удовлетворить ваши требования.
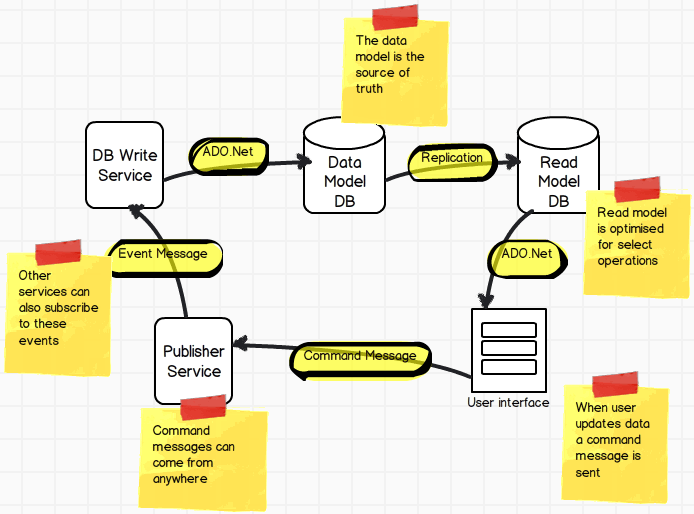
Если вам нужны дальнейшие объяснения, я был бы рад предоставить.
ОБНОВИТЬ
Основным принципом является то, что вы разделяете чтение и запись базы данных в разные базы данных.
Затем вы используете репликацию, чтобы обеспечить актуальность базы данных для чтения.
Вы также можете достичь вышеупомянутой архитектуры, объединив обе базы данных в одну и обе службы в одну. Тем не менее, ваш первоначальный вопрос был о конфликте баз данных, основанном на том факте, что у вас конфликтующие схемы использования баз данных
Вот почему я предложил CQRS в качестве решения - сторона записи базы данных отделена от стороны чтения. Сторона чтения может быть оптимизирована для выбора (даже может быть нормализована для скорости доступа).
Это означает, что вы не столкнетесь с такими же проблемами конкуренции, как если бы вы выполняли операции чтения и записи через один и тот же интерфейс - это ваш текущий подход.
Кроме того, вам не нужно выставлять свои операции чтения через службу - простой ADO подойдет, а конечная точка службы просто представит задержку.
Вы все еще можете использовать linq2sql, когда читаете из модели чтения, а также когда служба записи db обновляет модель данных.