Как выполнить тест Post Hoc, Тьюки в упаковке Agricola?
Я сделал это с
library(lsmeans)
а также
library(multcomp)
lm(Chlorophyll ~ Treatment + Stage + Treatment:Stage, "")
но мне интересно, как выполнить специальный тест после TW ANOVA в R. agricolae пакет?
structure( list(Treatment = structure(c(3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L), .Label = c("Control", "Nitrogen", "Salt"
), class = "factor"), Stage = structure(c(1L, 1L, 1L, 2L, 2L,
2L, 3L, 3L, 3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 1L, 1L, 1L,
2L, 2L, 2L, 3L, 3L, 3L), .Label = c("Green", "Pink", "Red"), class = "factor"),
Chlorophyll = c(0.2, 0.3, 0.4, 0.5, 0.3, 0.2, 0.5, 0.6, 0.7,
0.4, 0.6, 0.9, 0.2, 0.3, 0.5, 0.4, 0.2, 0.3, 0.5, 0.6, 0.8,
0.5, 0.4, 0.6, 0.2, 0.3, 0.1)), .Names = c("Treatment", "Stage",
"Chlorophyll"), class = "data.frame", row.names = c(NA, -27L)
)
Как мы можем построить графики для каждой ступени после чисел / букв группы?

1 ответ
Я предполагаю, что вы хотите сгруппировать данные в соответствии с Treatment, Stage и взаимодействия Treatment*Stage,
Перед выполнением парного ANOVA полезно рассчитать количество сравнений:
Treatmentа такжеStageу каждого есть 3 уровня, поэтому у нас естьchoose(length(levels(df$Treatment)), 2) = 3а такжеchoose(length(levels(df$Stage)), 2)сравнения соответственно; для термина взаимодействия мы должны рассмотреть все возможные комбинации междуTreatmentа такжеStagecombn_interact <- apply( expand.grid(levels(df$Treatment), levels(df$Stage)), 1, paste, collapse = ":"); combn_interact; #[1] "Control:Green" "Nitrogen:Green" "Salt:Green" "Control:Pink" #[5] "Nitrogen:Pink" "Salt:Pink" "Control:Red" "Nitrogen:Red" #[9] "Salt:Red"в результате чего в общей сложности
choose(length(combn_interact), 2) = 36сравнения. Таким образом, член взаимодействия приводит к большому количеству парных сравнений.Мы выполняем несколько парных анализов ANOVA
model <- aov(Chlorophyll ~ Treatment + Stage + Treatment*Stage, data = df);Сейчас мы проводим специальный тест для учета множественных гипотез, используя
PostHocTestотDescToolsбиблиотека. Существуют различные методы для исправления p-значений, здесь мы используем тест честного существенного различия Tukeylibrary(DescTools); PostHocTest(model, method = "hsd") # Posthoc multiple comparisons of means : Tukey HSD # 95% family-wise confidence level # #$Treatment # diff lwr.ci upr.ci pval #Nitrogen-Control -0.02222222 -0.1939346 0.1494902 0.9418 #Salt-Control -0.03333333 -0.2050457 0.1383791 0.8744 #Salt-Nitrogen -0.01111111 -0.1828235 0.1606013 0.9851 # #$Stage # diff lwr.ci upr.ci pval #Pink-Green -0.13333333 -0.3050457 0.03837906 0.1455 #Red-Green -0.15555556 -0.3272679 0.01615684 0.0797 . #Red-Pink -0.02222222 -0.1939346 0.14949017 0.9418 # #$`Treatment:Stage` # diff lwr.ci upr.ci pval #Nitrogen:Green-Control:Green 0.000000e+00 -0.40832017 0.40832017 1.0000 #Salt:Green-Control:Green -3.333333e-01 -0.74165350 0.07498684 0.1643 #Control:Pink-Control:Green -1.333333e-01 -0.54165350 0.27498684 0.9586 #Nitrogen:Pink-Control:Green -3.000000e-01 -0.70832017 0.10832017 0.2624 #Salt:Pink-Control:Green -3.000000e-01 -0.70832017 0.10832017 0.2624 #Control:Red-Control:Green -4.333333e-01 -0.84165350 -0.02501316 0.0327 * #Nitrogen:Red-Control:Green -3.333333e-01 -0.74165350 0.07498684 0.1643 #Salt:Red-Control:Green -3.333333e-02 -0.44165350 0.37498684 1.0000 #Salt:Green-Nitrogen:Green -3.333333e-01 -0.74165350 0.07498684 0.1643 #Control:Pink-Nitrogen:Green -1.333333e-01 -0.54165350 0.27498684 0.9586 #Nitrogen:Pink-Nitrogen:Green -3.000000e-01 -0.70832017 0.10832017 0.2624 #Salt:Pink-Nitrogen:Green -3.000000e-01 -0.70832017 0.10832017 0.2624 #Control:Red-Nitrogen:Green -4.333333e-01 -0.84165350 -0.02501316 0.0327 * #Nitrogen:Red-Nitrogen:Green -3.333333e-01 -0.74165350 0.07498684 0.1643 #Salt:Red-Nitrogen:Green -3.333333e-02 -0.44165350 0.37498684 1.0000 #Control:Pink-Salt:Green 2.000000e-01 -0.20832017 0.60832017 0.7303 #Nitrogen:Pink-Salt:Green 3.333333e-02 -0.37498684 0.44165350 1.0000 #Salt:Pink-Salt:Green 3.333333e-02 -0.37498684 0.44165350 1.0000 #Control:Red-Salt:Green -1.000000e-01 -0.50832017 0.30832017 0.9927 #Nitrogen:Red-Salt:Green 3.885781e-16 -0.40832017 0.40832017 1.0000 #Salt:Red-Salt:Green 3.000000e-01 -0.10832017 0.70832017 0.2624 #Nitrogen:Pink-Control:Pink -1.666667e-01 -0.57498684 0.24165350 0.8718 #Salt:Pink-Control:Pink -1.666667e-01 -0.57498684 0.24165350 0.8718 #Control:Red-Control:Pink -3.000000e-01 -0.70832017 0.10832017 0.2624 #Nitrogen:Red-Control:Pink -2.000000e-01 -0.60832017 0.20832017 0.7303 #Salt:Red-Control:Pink 1.000000e-01 -0.30832017 0.50832017 0.9927 #Salt:Pink-Nitrogen:Pink -5.551115e-17 -0.40832017 0.40832017 1.0000 #Control:Red-Nitrogen:Pink -1.333333e-01 -0.54165350 0.27498684 0.9586 #Nitrogen:Red-Nitrogen:Pink -3.333333e-02 -0.44165350 0.37498684 1.0000 #Salt:Red-Nitrogen:Pink 2.666667e-01 -0.14165350 0.67498684 0.3967 #Control:Red-Salt:Pink -1.333333e-01 -0.54165350 0.27498684 0.9586 #Nitrogen:Red-Salt:Pink -3.333333e-02 -0.44165350 0.37498684 1.0000 #Salt:Red-Salt:Pink 2.666667e-01 -0.14165350 0.67498684 0.3967 #Nitrogen:Red-Control:Red 1.000000e-01 -0.30832017 0.50832017 0.9927 #Salt:Red-Control:Red 4.000000e-01 -0.00832017 0.80832017 0.0574 . #Salt:Red-Nitrogen:Red 3.000000e-01 -0.10832017 0.70832017 0.2624 # #--- #Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Построение распределений значений в каждой группе требует извлечения наблюдений для каждой соответствующей группы наших 3
Treatment3Stageи 36Treatment*Stageсравнения. Например, для 3TreatmentСравнения, вы можете сделатьdf %>% ggplot(aes(x = Treatment, y = Chlorophyll)) + geom_boxplot() + geom_jitter(width = 0.2)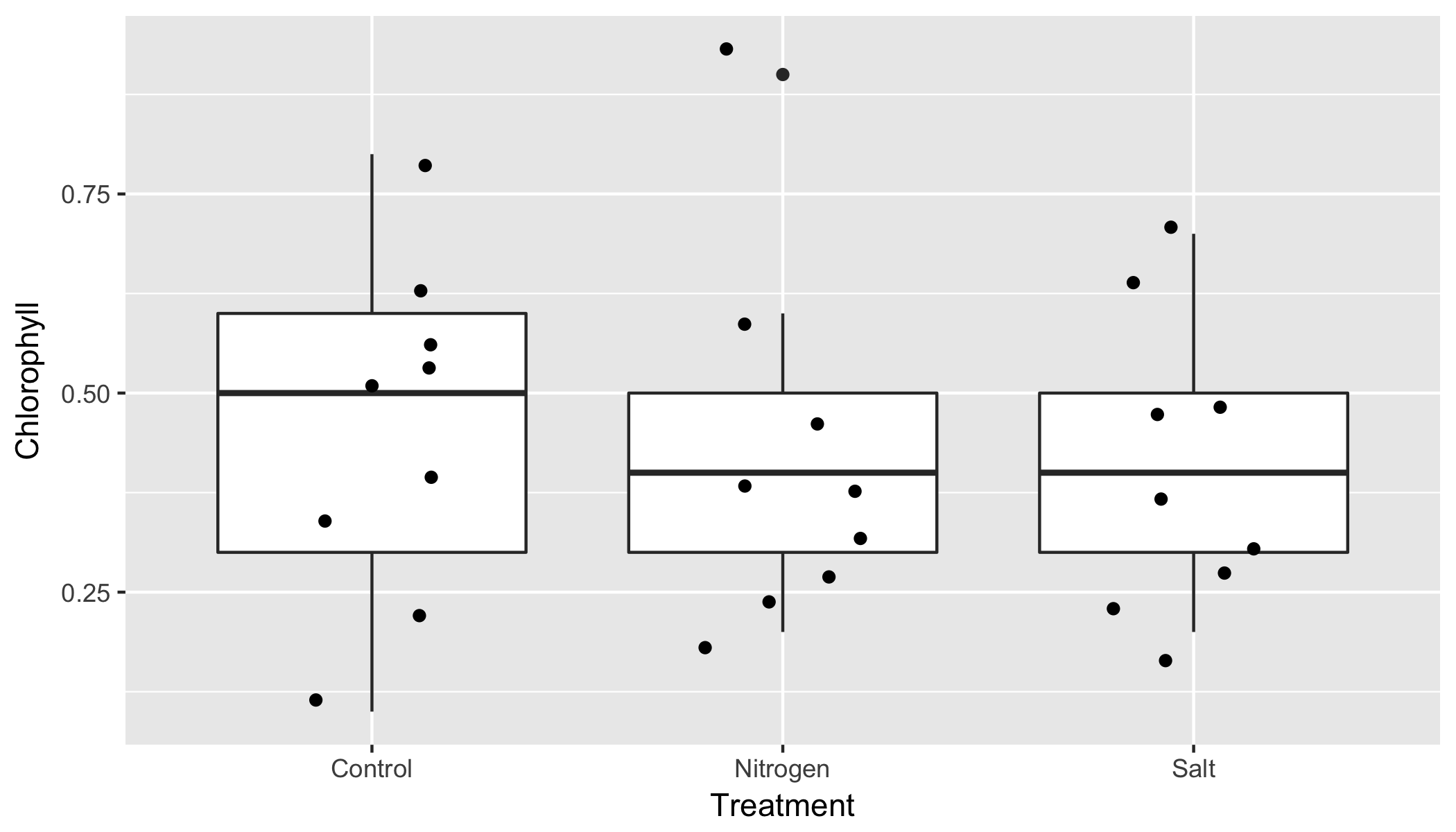
В соответствии с результатами апостериорного теста, нет статистически значимых изменений среднего значения между любым из трех распределений.
Другие сюжеты так же просты, и я оставлю это на ваше усмотрение.
Пример данных
df <- structure( list(Treatment = structure(c(3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L), .Label = c("Control", "Nitrogen", "Salt"
), class = "factor"), Stage = structure(c(1L, 1L, 1L, 2L, 2L,
2L, 3L, 3L, 3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 1L, 1L, 1L,
2L, 2L, 2L, 3L, 3L, 3L), .Label = c("Green", "Pink", "Red"), class = "factor"),
Chlorophyll = c(0.2, 0.3, 0.4, 0.5, 0.3, 0.2, 0.5, 0.6, 0.7,
0.4, 0.6, 0.9, 0.2, 0.3, 0.5, 0.4, 0.2, 0.3, 0.5, 0.6, 0.8,
0.5, 0.4, 0.6, 0.2, 0.3, 0.1)), .Names = c("Treatment", "Stage",
"Chlorophyll"), class = "data.frame", row.names = c(NA, -27L)
)