Распаковка цифры COMP-3 с использованием Java
У меня есть файл с некоторыми полями в кодировке COMP-3. Может кто-нибудь, пожалуйста, скажите мне, как я могу проверить этот код в приведенной ниже теме?
Как распаковать цифры COMP-3, используя Java?
Код, который я пробовал
BufferedReader br = новый BufferedReader(новый FileReader(FILENAME))) {
String sCurrentLine;
int i=0;
String bf =null;
while ((sCurrentLine = br.readLine()) != null) {
i++;
System.out.println("FROM BYTES ");
System.out.println(unpackData(sCurrentLine.getBytes(), 5));
for (int j = 0; j < sCurrentLine.length(); j++) {
char c = sCurrentLine.charAt(j);
bf =bf + (int)c;
}
Выше код не дает правильный результат. Я попытался преобразовать один столбец, но он не возвращает правильный результат. Мой входной столбец 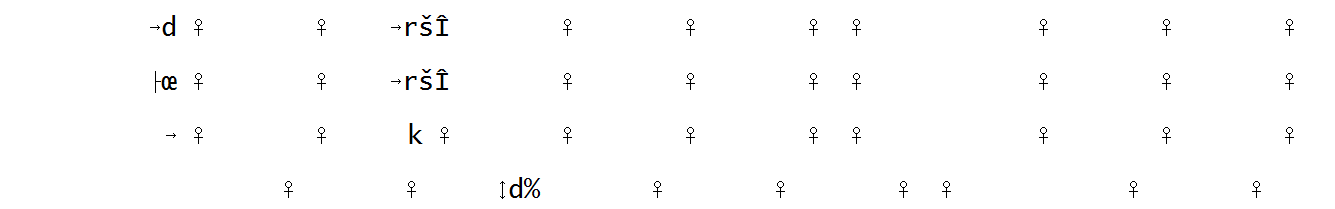
входной файл выглядит так
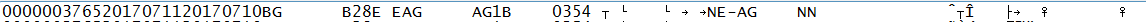
Я опробовал JRecord, передавая cbl copybook и файл данных, он генерирует Java-код, который дает не тот же результат. 
требуемый выход
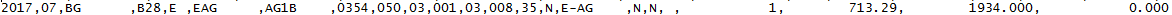
cbl copy book выглядит как изображение ниже

4 ответа
Если вы сравните тетрадь с данными; вы увидите, что это не соответствует.
В частности, Class-Order-edg определяется как рис. 9(3), но похоже, что он является двоичным в файле.
Bils-count-edg выглядит смещенным на 6 байтов. Это согласуется с полями Class-order-edg -> Country-no-edg, которые изменяются на comp-3/comp. Тетрадь, кажется, устарела.
Принятый ответ может быть в Как распаковать цифры COMP-3, используя Java? работать при работе с Ascii на основе Cobol. Он не будет работать при чтении файлов мэйнфреймов Ebcdic с помощью FileReader.
Вы отметили, что вопрос помечен как Mainframe - Ebcdic.
Обрабатывать правильно,
- Сделайте бинарный перевод с мэйнфрейма (или запустите на мэйнфрейме). Не делайте преобразование ascii, это повредит поля comp-3.
- Считайте файл как поток и обработайте его как байты.
Ответ в распаковке данных COMP-3 на Java (Embedded in Pentaho) будет работать; Есть и другие ответы на стеке потока, которые также будут работать.
Попытка обработки данных Comp-3 как символа подвержена ошибкам
JRecord
Если у вас есть тетрадь Cobol, библиотека JRecord позволит вам прочитать файл, используя тетрадь Cobol. Он содержит документ ReadMe_NewUsers.html, в котором рассматриваются основы.
RecordEditor
Опция меню Generate >>> Java~JRecord для кода cobol RecordEditor будет генерировать Java ~ JRecord из тетради Cobol (и, необязательно, файла данных). 
В этом ответе есть подробности о генерации кода. Как определить уровень поля в тетради с помощью JRecord в Java? или посмотрите здесь
Также в RecordEditor Recouts Layouts >>> Load Cobol Copybook загрузит тетрадь Cobol; Вы можете использовать Layout просмотреть файл.
Лучший способ манипулировать упакованным десятичным числом - использовать API IBM Data Access Accelerator. Он использует специфичную для IBM оптимизацию JVM, называемую упакованными объектами, которая представляет собой технологию для эффективной работы с собственными данными. В SO есть хороший Java-код для обработки упакованных десятичных данных, но разумным выбором является Data Access Accelerator. Это уносит код RYO.
Значение термина "зашифрованный файл COMP-3" мне не ясно, но я думаю, что вы говорите, что у вас есть файл, который был перенесен из системы на основе zOS (EBCDIC) в систему на основе ASCII, и вы хотите быть возможность обрабатывать значения, содержащиеся в COMP-3 (упакованные десятичные поля). Если это правильно, у меня есть некоторый код и исследования, которые соответствуют вашим потребностям.
Я предполагаю, что файл был преобразован из EBCDIC в ASCII, когда он был перенесен из zOS.
Распространенным заблуждением является то, что если данные COMP-3 (упакованные десятичные числа) преобразуются из EBCDIC в ASCII, то они "повреждены". Это не относится к делу. То, что вы получаете, это значения в диапазоне от x'00' - x'0F'. Независимо от того, находитесь ли вы в системе на основе EBCDIC или ASCII, шестнадцатеричные значения в этом диапазоне одинаковы.
Если данные просматриваются за пределами шестнадцатеричного редактора [в любой системе], они выглядят поврежденными. В зависимости от кодовой страницы упакованное десятичное число 01234567890 может отображаться как ⌁杅ྉ. Однако, используя шестнадцатеричный редактор, вы можете увидеть, что значение на самом деле равно x'01 23 45 67 89 0F'. Два числа хранятся в одном байте (одна цифра в каждом полубайте, причем последним полубайтом в последнем байте является знак). Когда каждый байт конвертируется из шестнадцатеричного числа, возвращаются фактические числа. Например, используя Lua, если переменная iChar содержит x'23', функция oDec = string.format("%X", iChar) возвращает текстовое значение "23", которое можно преобразовать в число. Итерируя по всей строке x'01 23 45 67 89 0F ', возвращается фактическое число (01234567890). Номер может быть "перепакован" путем изменения процесса.
Пример кода для распаковки упакованного десятичного поля показан ниже:
--[[ Lua 5.2.3 ]]
--[[ Author: David Alley
Written: August 9, 2017 ]]
--[[ Begin Function ]]
function xdec_unpack (iHex, lField, lNumber)
--[[
This function reads packed decimal data (converted from EBCDIC to ASCII) as input
and returns unpacked ASCII decimal numbers.
--]]
if iHex == nil or iHex == ""
then
return iHex
end
local aChar = {}
local aUnpack = {}
local iChar = ''
for i = 1, lField do
aChar[i] = string.byte(iHex, i)
end
for i, iChar in ipairs(aChar) do
local oDec = string.format("%X", iChar)
if string.len(oDec) == 1
then
table.insert(aUnpack, "0" .. oDec) --[[ Handles binary zeros ]]
else
table.insert(aUnpack, oDec)
end
end
if string.len(table.concat(aUnpack)) - 1 ~= lNumber
then
aUnpack[1] = string.sub(aUnpack[1],2,2)
end
return table.concat(aUnpack)
end
--[[ End Function xdec_unpack ]]
--[[ The code below was written for Linux and reads an entire file. It assumes that there is only one field, and that
field is in packed decimal format. Packed decimal format means that the file was transferred from a z/OS (EBCDIC) system
and the data was converted to ASCII.
It is necessary to supply the field length because when Lua encounters binary zeros (common in packed decimal),
they are treated as an "end of record" indicator. The packed length value is supplied by the variable lField and the
unpacked length value is supplied by the variable lNumber.
Since there is only one field, that field by default, is at the end of each record (the field is the record). Therefore,
any "new line" values (0x0a for Linux) must be included when reading records. This is handled by adding 1 to the variable
lField when reading records. Therefore, this code must be modified if there are multiple fields, and/or the packed decimal
field is not the last field in the record.
The sign is dropped from the unpacked value that is returned from the function xdec_unpack by removing the last byte from the
variable Output1 before writing the records. Therefore, this code must be modified if it is necessary to process negative
numbers. ]]
local lField = 7 --[[ This variable is the length of the packed decimal field before unpacking and is required by the
xdec_unpack function. ]]
local lNumber = 12 --[[ This variable is the length of the unpacked decimal field not including the sign. It is required by the
xdec_unpack function. Its purpose is to determine if a high order zero (left zero) is to be removed. This
occurs in situations where the packed decimal field contains an even number of digits. For example,
0123456789. ]]
local sFile = io.open("/home/david/Documents/Lua/Input/Input2.txt", "r")
local oFile = io.open("/home/david/Documents/Lua/Input/Output1.txt", "w")
while true do
sFile:seek("cur")
local sLine = sFile:read(lField + 1)
if sLine == nil then break end
local Output1 = xdec_unpack(sLine, lField, lNumber) --[[ Call function to unpack ]]
Output1 = string.sub(Output1,1, #Output1 - 1) --[[ Remove sign ]]
oFile:write(Output1, "\n")
end
sFile:close()
oFile:close()