Qlearning - определение состояний и наград
Мне нужна помощь в решении проблемы, которая использует алгоритм Q-обучения.
Описание проблемы:
У меня есть симулятор ракеты, где ракета выбирает случайные пути, а также иногда падает. Ракета имеет 3 разных двигателя, которые могут быть включены или выключены. В зависимости от того, какой двигатель (ы) активирован, ракета летит в разные стороны.
Доступны функции для включения / выключения двигателей.

Задание:
Создайте контроллер Q-Learning, который будет постоянно вращаться лицом вверх.
Датчик, который считывает угол наклона ракеты, доступен в качестве входных данных.
Мое решение:
У меня есть следующие состояния:
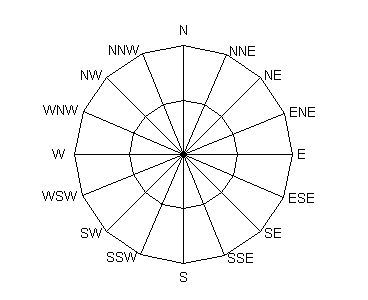
У меня также есть следующие действия:
- все двигатели выключены
- левый двигатель включен
- правый двигатель включен
- средний двигатель включен
- влево и вправо на
- слева и посередине
- правый и средний
И следующие награды:
Угол = 0, награда = 100 Все остальные углы, награда = 0
Вопрос:
Теперь вопрос: хороший ли это выбор наград и штатов? Могу ли я улучшить свое решение? Лучше иметь больше наград за другие углы?
заранее спасибо
2 ответа
16 состояний х 7 действий - очень маленькая проблема.
Награды за другие углы помогут вам учиться быстрее, но могут создать странное поведение позже в зависимости от вашей динамики.
Если у вас нет импульса, вы можете уменьшить количество состояний, что ускорит обучение и уменьшит использование памяти (которое уже крошечно). Чтобы найти оптимальное количество состояний, попробуйте уменьшить число состояний при анализе метрики, такой как награда / временные шаги в нескольких играх или средняя ошибка (нормализованная по начальному углу) в нескольких играх. Некоторые государственные представительства могут работать намного лучше, чем другие. Если нет, выберите тот, который сходится быстрее всего. Это должно быть относительно дешево с вашей маленькой Q-таблицей.
Если вы хотите быстро учиться, вы можете также попробовать Q-лямбду или другой модифицированный алгоритм обучения с подкреплением, чтобы использовать обучение во временной разнице.
Изменить: В зависимости от вашей динамики эта проблема может не подходить в качестве процесса принятия решения Маркова. Например, вам может потребоваться включить текущую скорость вращения.
Попробуйте поставить меньшие награды за состояния рядом с желаемым состоянием. Это заставит вашего агента учиться идти быстрее.