Разница между размером резидентного набора (RSS) и общей выделенной памятью Java (NMT) для JVM, работающей в контейнере Docker
Сценарий:
У меня есть JVM, работающая в контейнере докера. Я провел некоторый анализ памяти, используя два инструмента: 1) top 2) Отслеживание собственной памяти Java. Цифры выглядят сбивающими с толку, и я пытаюсь найти то, что вызывает различия.
Вопрос:
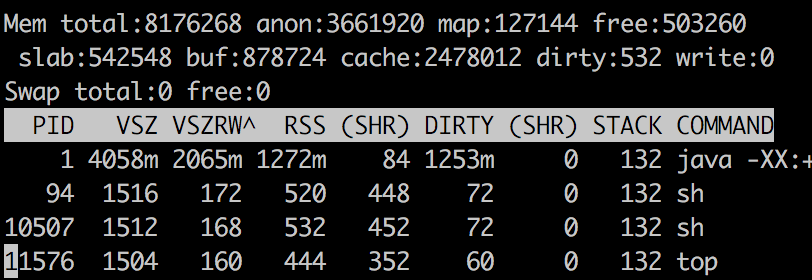
RSS сообщается как 1272 МБ для процесса Java, а общий объем памяти Java - 790,55 МБ. Как я могу объяснить, куда ушла оставшаяся память 1272 - 790,55 = 481,44 МБ?
Почему я хочу оставить этот вопрос открытым даже после просмотра этого вопроса на SO:
Я видел ответ, и объяснение имеет смысл. Однако после получения выходных данных Java NMT и pmap -x я все еще не могу конкретно отобразить, какие адреса Java-памяти на самом деле являются резидентными и физически сопоставлены. Мне нужно какое-то конкретное объяснение (с подробными шагами), чтобы найти причины этого различия между RSS и Java.
Верхний вывод
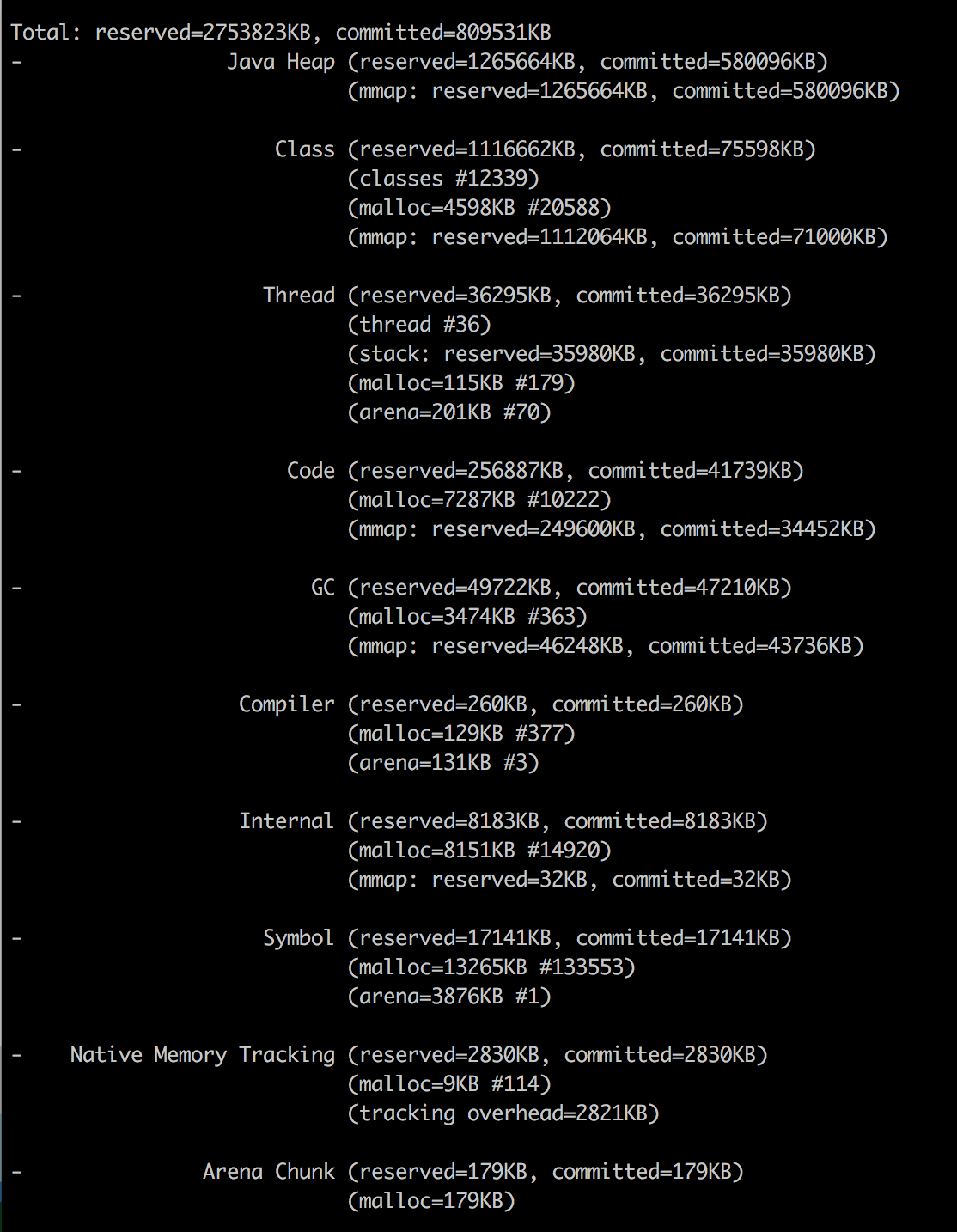
Java NMT
Статистика памяти Docker
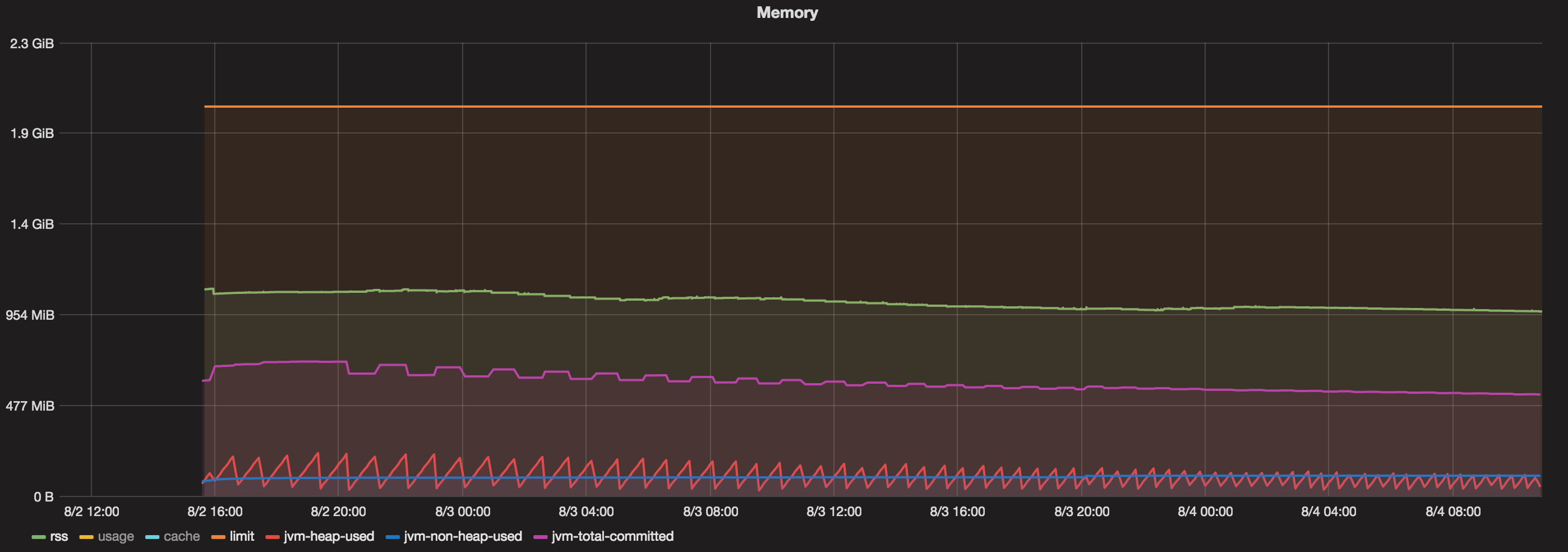
диаграммы
У меня есть докер-контейнер, работающий более 48 часов. Теперь, когда я вижу график, который содержит:
- Общий объем памяти, выделенный для док-контейнера = 2 ГБ
- Java Max Heap = 1 ГБ
- Всего зафиксировано (JVM) = всегда менее 800 МБ
- Используемая куча (JVM) = всегда менее 200 МБ
- Non Heap Used (JVM) = всегда менее 100 МБ.
- RSS = около 1,1 ГБ.
Итак, что же потребляет память между 1,1 ГБ (RSS) и 800 МБ (общая выделенная память Java)?
2 ответа
У вас есть подсказка в разделе " Анализ использования памяти Java в Docker-контейнере " от Михаила Крестьянинова:
R esident S et S ize - это объем физической памяти, выделенной в настоящее время и используемой процессом (без выкачанных страниц). Он включает в себя код, данные и общие библиотеки (которые учитываются в каждом процессе, который их использует)
Почему информация статистики Docker отличается от данных PS?
Ответ на первый вопрос очень прост - в Docker есть ошибка (или функция - зависит от вашего настроения): он включает файловые кэши в общую информацию об использовании памяти. Таким образом, мы можем просто избежать этого показателя и использовать
psинформация о RSS.Хорошо, хорошо - но почему RSS выше, чем Xmx?
Теоретически, в случае Java-приложения
RSS = Heap size + MetaSpace + OffHeap size
где OffHeap состоит из стеков потоков, прямых буферов, сопоставленных файлов (библиотек и jar-файлов) и ив-кода JVM
Начиная с JDK 1.8.40 у нас есть Native Memory Tracker!
Как видите, я уже добавил
-XX:NativeMemoryTracking=summaryсвойство JVM, поэтому мы можем просто вызвать его из командной строки:
docker exec my-app jcmd 1 VM.native_memory summary
(Это то, что сделал ОП)
Не беспокойтесь о разделе "Неизвестно" - кажется, что NMT является незрелым инструментом и не может работать с CMS GC (этот раздел исчезает, когда вы используете другой GC).
Имейте в виду, что NMT отображает "зафиксированную" память, а не "резидентную" (которую вы получаете через команду ps). Другими словами, страница памяти может быть зафиксирована без учета резидента (до тех пор, пока к ней не будет получен прямой доступ).
Это означает, что результаты NMT для областей без кучи (куча всегда предварительно инициализирована) могут быть больше, чем значения RSS.
(вот почему " почему JVM сообщает больше выделенной памяти, чем размер резидентного набора процесса linux? ")
В результате, несмотря на то, что мы установили ограничение кучи jvm равным 256 м, наше приложение потребляет 367 МБ. "Другой" 164M в основном используется для хранения метаданных класса, скомпилированного кода, потоков и данных GC.
Первые три точки часто являются константами для приложения, поэтому единственное, что увеличивается с размером кучи, - это данные GC.
Эта зависимость является линейной, но "kКоэффициент (y = kx + b) намного меньше 1.
В более общем смысле за этим следует проблема 15020, которая сообщает о подобной проблеме, начиная с докера 1.7.
Я запускаю простое приложение Scala (JVM), которое загружает много данных в память и из нее.
Я установил JVM на кучу 8G (-Xmx8G). У меня есть машина с памятью 132G, и она не может обрабатывать более 7-8 контейнеров, потому что они значительно превышают предел 8G, который я установил для JVM.
(docker stat ранее сообщалось, что вводит в заблуждение, поскольку, по-видимому, оно включает файловые кэши в общую информацию об использовании памяти)
docker statпоказывает, что каждый контейнер использует намного больше памяти, чем предполагается использовать JVM. Например:
CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O
dave-1 3.55% 10.61 GB/135.3 GB 7.85% 7.132 MB/959.9 MB
perf-1 3.63% 16.51 GB/135.3 GB 12.21% 30.71 MB/5.115 GB
Похоже, что JVM запрашивает у ОС память, выделенную внутри контейнера, и JVM освобождает память во время работы своего GC, но контейнер не освобождает память обратно в основную ОС. Итак... утечка памяти.
Отказ от ответственности: я не эксперт
Недавно у меня был производственный инцидент, когда под большой нагрузкой у модулей произошел большой скачок в RSS, и Kubernetes убил модули. Исключения ошибки OOM не было, но Linux самым хардкорным образом остановил процесс.
Был большой разрыв между RSS и общим зарезервированным пространством JVM. Куча памяти, родная память, потоки, все выглядело нормально, однако RSS был большим.
Выяснилось, что это связано с тем, как работает malloc внутри. В памяти есть большие пробелы, из которых malloc берет куски памяти. Если на вашей машине много ядер, malloc пытается приспособиться и предоставить каждому ядру собственное пространство, из которого можно взять свободную память, чтобы избежать конкуренции за ресурсы. Настройкаexport MALLOC_ARENA_MAX=2решил проблему. Подробнее об этой ситуации можно узнать здесь:
- Растущее использование резидентной памяти (RSS) Java Process
- https://devcenter.heroku.com/articles/tuning-glibc-memory-behavior
- https://www.gnu.org/software/libc/manual/html_node/Malloc-Tunable-Parameters.html
- https://github.com/jeffgriffith/native-jvm-leaks
PS Не знаю, почему произошел скачок в RSS-памяти. Поды построены на Spring Boot + Kafka.