Правильный способ реализации смещений в нейронных сетях
Я могу сделать нейронную сеть, мне просто нужно уточнить реализацию смещения. Какой способ лучше: реализовать матрицы смещения B1, B2, .. Bn для каждого слоя в своей отдельной, отдельной матрице из матрицы весов, или, включите смещения в матрице весов, добавив 1 к выходу предыдущего слоя (вход для этого слоя). В изображениях я спрашиваю, есть ли эта реализация:
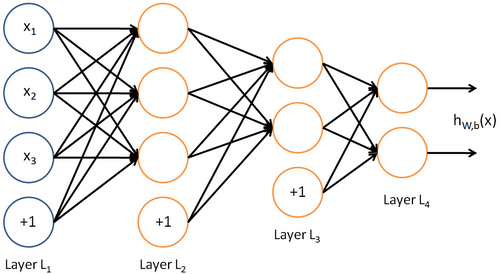
Или эта реализация:
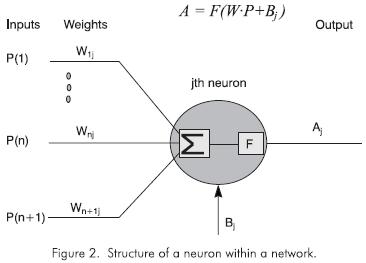
Это лучшее. Спасибо
3 ответа
Я думаю, что лучший способ состоит в том, чтобы иметь две отдельные матрицы, одну для весов и одну для смещения. Зачем?:
Я не верю, что вычислительная нагрузка увеличивается
W*xа такжеW*x + bдолжен быть эквивалентен работе на GPU. Математически и в вычислительном отношении они эквивалентны.Большая модульность. Допустим, вы хотите инициализировать весовые коэффициенты и смещение, используя разные инициализаторы (единицы, нули, glorot...). Имея две отдельные матрицы, это просто.
Легче читать и поддерживать.
включить смещения в матрицу весов, добавив 1 к выходу предыдущего слоя (вход для этого слоя)
Похоже, это то, что реализовано здесь: Машинное обучение с Python: обучение и тестирование нейронной сети с набором данных MNIST в параграфе "Сети с несколькими скрытыми слоями".
Я не знаю, если это лучший способ сделать это, хотя. (Может быть, не связано, но все же: в приведенном примере кода он работал с сигмоидом, но потерпел неудачу, когда я заменил его на ReLU).
На мой взгляд, я думаю, что реализация матриц смещения отдельно для каждого слоя - это путь. Это создаст много гиперпараметров, которые ваша модель должна будет изучить, но это даст вашей модели больше свободы для сближения.
Для получения дополнительной информации прочитайте это.