Реструктурировать список смежности от нескольких наблюдений на респондента / эго до одного
Фрейм данных HeyRecess ниже приводится одно наблюдение на респондента, по клике и по школе. Вот оно (и вот ссылка только для чтения на данные, если вы хотите их прочитать):
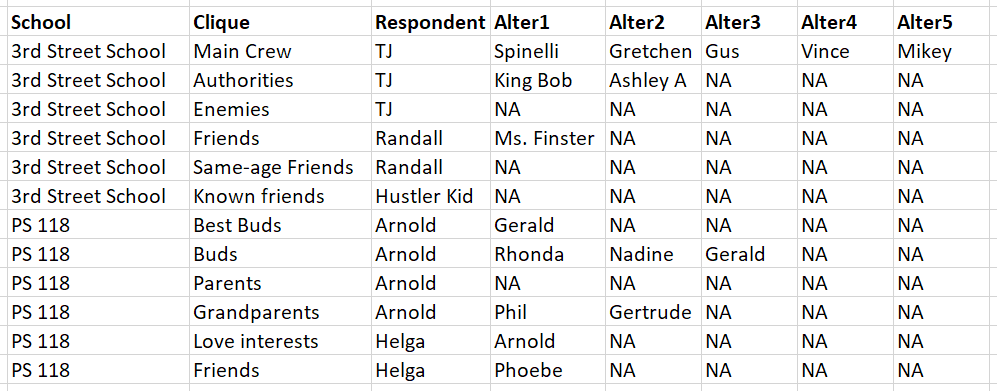
Я хочу преобразовать это в фрейм данных WANT в каждой респонденте по одной строке указывается список всех людей, к которым они подключены в этой строке, независимо от клики, к которой относится каждое изменение (обратите внимание, что изменение имени переменной является преднамеренным):

WANT также должна включать переменную, подсчитывающую количество раз, когда каждый из HeyRecess появляется как альтернатива для уникального Respondent имена в WANT, Например, "Джеральд" в двух разных строках для Respondent "Арнольд", так что переменная nforA связаны с Respondent = "Арнольд" равен 2, а "Джеральд" не указан несколько раз в WANT,
Я могу решить эту проблему с distinct() от dplyr пакет, чтобы получить список уникальных Respondent значения по школе в качестве фрейма данных под названием IDsзатем используйте if_else условия на AlterN переменные в HeyRecess респондентом, чтобы получить ряды изменений в Respondent - вызывая этот фрейм данных alters, Затем я rbind() IDs а также alters фреймы данных.
Это ужасно, и я думаю, что есть лучший способ. У вас есть примеры или рекомендации?
(FWIW У меня не было Никелодеона в детстве - извините, если у Хельги больше друзей.)