Решить линейные уравнения с учетом переменных и неопределенностей: scipy-optimize?
Я хотел бы минимизировать набор уравнений, где переменные известны с их неопределенностью. По сути, я хотел бы проверить гипотезу о том, что данные измеряемые переменные соответствуют ограничениям формулы, заданным уравнениями. Это похоже на то, что я должен быть в состоянии сделать со scipy-optimize. Например, у меня есть три уравнения:
8 = 0.5 * x1 + 1.0 * x2 + 1.5 * x3 + 2.0 * x4
4 = 0.0 * x1 + 0.0 * x2 + 1.0 * x3 + 1.0 * x4
1 = 1.0 * x1 + 1.0 * x2 + 0.0 * x3 + 0.0 * x4
И четыре измеренных неизвестных с их неопределенностью в 1 сигму:
x1 = 0.246 ± 0.007
x2 = 0.749 ± 0.010
x3 = 1.738 ± 0.009
x4 = 2.248 ± 0.007
Нужны любые указатели в правильном направлении.
1 ответ
Это мой подход. Если предположить, x1-x4 приблизительно нормально распределены вокруг каждого среднего значения (неопределенность 1-сигма), проблема превращается в одну из минимизации суммы квадратов ошибок с 3 линейными функциями ограничения. Поэтому мы можем атаковать его, используя scipy.optimize.fmin_slsqp()
In [19]:
def eq_f1(x):
return (x*np.array([0.5, 1.0, 1.5, 2.0])).sum()-8
def eq_f2(x):
return (x*np.array([0.0, 0.0, 1.0, 1.0])).sum()-4
def eq_f3(x):
return (x*np.array([1.0, 1.0, 0.0, 0.0])).sum()-1
def error_f(x):
error=(x-np.array([0.246, 0.749, 1.738, 2.248]))/np.array([0.007, 0.010, 0.009, 0.007])
return (error*error).sum()
In [20]:
so.fmin_slsqp(error_f, np.array([0.246, 0.749, 1.738, 2.248]), eqcons=[eq_f1, eq_f2, eq_f3])
Optimization terminated successfully. (Exit mode 0)
Current function value: 2.17576389592
Iterations: 4
Function evaluations: 32
Gradient evaluations: 4
Out[20]:
array([ 0.25056582, 0.74943418, 1.74943418, 2.25056582])
Как сказано, у проблемы нет решения. Это потому, что если входы x1, x2, x3 и x4 являются гауссовскими, то выходы:
y1 = 0.5 * x1 + 1.0 * x2 + 1.5 * x3 + 2.0 * x4 - 8.0
y2 = 0.0 * x1 + 0.0 * x2 + 1.0 * x3 + 1.0 * x4 - 4.0
y3 = 1.0 * x1 + 1.0 * x2 + 0.0 * x3 + 0.0 * x4 - 1.0
также гауссовские. Предполагая, что x1, x2, x3 и x4 являются независимыми случайными величинами, это легко увидеть с помощью OpenTURNS:
import openturns as ot
x1 = ot.Normal(0.246, 0.007)
x2 = ot.Normal(0.749, 0.010)
x3 = ot.Normal(1.738, 0.009)
x4 = ot.Normal(2.248, 0.007)
y1 = 0.5 * x1 + 1.0 * x2 + 1.5 * x3 + 2.0 * x4 - 8.0
y2 = 0.0 * x1 + 0.0 * x2 + 1.0 * x3 + 1.0 * x4 - 4.0
y3 = 1.0 * x1 + 1.0 * x2 + 0.0 * x3 + 0.0 * x4 - 1.0
Следующий скрипт создает график:
graph1 = y1.drawPDF()
graph1.setLegends(["y1"])
graph2 = y2.drawPDF()
graph2.setLegends(["y2"])
graph3 = y3.drawPDF()
graph3.setLegends(["y3"])
graph1.add(graph2)
graph1.add(graph3)
graph1.setColors(["dodgerblue3",
"darkorange1",
"forestgreen"])
graph1.setXTitle("Y")
Предыдущий сценарий дает следующий результат.
Учитывая расположение 0,0 в этом распределении, я бы сказал, что решение уравнений математически невозможно, но физически согласуется с данными.
На самом деле, я предполагаю, что гауссовские распределения, которые вы дали для x1, ..., x4, оцениваются на основе данных. Поэтому я бы предпочел переформулировать проблему следующим образом:
Учитывая выборку наблюдаемых значений x1, x2, x3, x4, каково значение e1, e2, e3, которое таково, что:
y1 = 0.5 * x1 + 1.0 * x2 + 1.5 * x3 + 2.0 * x4 - 8 + e1 = 0
y2 = 0.0 * x1 + 0.0 * x2 + 1.0 * x3 + 1.0 * x4 - 4 + e2 = 0
y3 = 1.0 * x1 + 1.0 * x2 + 0.0 * x3 + 0.0 * x4 - 1 + e3 = 0
Это превращает проблему в проблему инверсии, которую можно решить путем калибровки e1, e2, e3. Более того, учитывая конечный размер выборки x1, ..., x4, мы могли бы захотеть получить распределение e1, e2, e3. Это можно сделать путем начальной загрузки пар ввода / вывода (x, y): распределение e1, e2, e3 затем отражает изменчивость этих параметров в зависимости от имеющейся выборки.
Во-первых, мы должны сгенерировать образец из дистрибутива (я предполагаю, что у вас есть этот образец, но пока он не опубликован):
distribution = ot.ComposedDistribution([x1, x2, x3, x4])
sampleSize = 10
xobs = distribution.getSample(sampleSize)
Затем мы определяем модель:
formulas = [
"y1 := 0.5 * x1 + 1.0 * x2 + 1.5 * x3 + 2.0 * x4 + e1 - 8.0",
"y2 := 0.0 * x1 + 0.0 * x2 + 1.0 * x3 + 1.0 * x4 + e2 - 4.0",
"y3 := 1.0 * x1 + 1.0 * x2 + 0.0 * x3 + 0.0 * x4 + e3 - 1.0"
]
program = ";".join(formulas)
g = ot.SymbolicFunction(["x1", "x2", "x3", "x4", "e1", "e2", "e3"],
["y1", "y2", "y3"],
program)
И установите наблюдаемые выходы, которые представляют собой образец нулей:
yobs = ot.Sample(sampleSize, 3)
Мы начинаем с начальных значений, равных нулю, и определяем функцию для калибровки:
e1Initial = 0.0
e2Initial = 0.0
e3Initial = 0.0
thetaPrior = ot.Point([e1Initial,e2Initial,e3Initial])
calibratedIndices = [4, 5, 6]
mycf = ot.ParametricFunction(g, calibratedIndices, thetaPrior)
Затем мы можем откалибровать модель:
algo = ot.NonLinearLeastSquaresCalibration(mycf, xobs, yobs, thetaPrior)
algo.run()
calibrationResult = algo.getResult()
print(calibrationResult.getParameterMAP())
Это печатает:
[0.0265988,0.0153057,0.00495758]
Это означает, что ошибки e1, e2, e3 довольно малы. Мы можем вычислить доверительный интервал:
thetaPosterior = calibrationResult.getParameterPosterior()
print(thetaPosterior.computeBilateralConfidenceIntervalWithMarginalProbability(0.95)[0])
Это печатает:
[0.0110046, 0.0404756]
[0.00921992, 0.0210059]
[-0.00601084, 0.0156665]
Третий параметр e3 может быть нулевым, но ни e1, ни e2. Наконец, мы можем получить распределение ошибок:
thetaPosterior = calibrationResult.getParameterPosterior()
и нарисуйте это:
graph1 = thetaPosterior.getMarginal(0).drawPDF()
graph2 = thetaPosterior.getMarginal(1).drawPDF()
graph3 = thetaPosterior.getMarginal(2).drawPDF()
graph1.add(graph2)
graph1.add(graph3)
graph1.setColors(["dodgerblue3",
"darkorange1",
"forestgreen"])
graph1
Это производит:
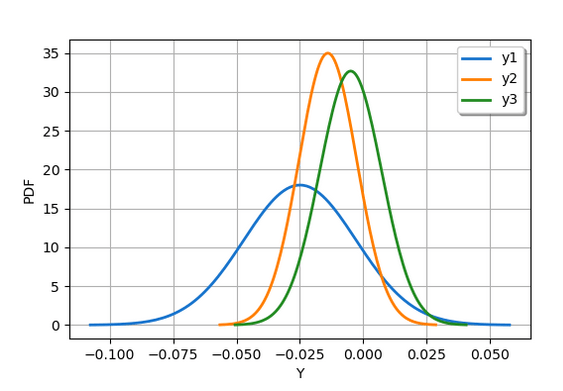
Это показывает, что e3 может быть равно нулю, учитывая изменчивость наблюдаемых входных данных x1, ..., x4. Но e1 и e2 не могут быть равны нулю. Вывод для этого образца состоит в том, что третье уравнение приближенно решается наблюдаемыми значениями x1, ..., x4, но не двумя первыми уравнениями.
Мне кажется, что у меня очень похожая проблема. Я относительно новичок в py и использовал его в основном для сортировки и сокращения данных с помощью pandas.
У меня есть набор линейных уравнений, по которым я хочу найти наиболее подходящие параметры. Однако в наборе данных есть известные неопределенности, которые необходимо учитывать в скобках).
x1*99(1)+x2*45(1)=52(0.2)
x1*1(0.5)+x2*16(1)=15(0.1)
Кроме того, есть ограничения:
x1>=0
x2>=0
x1+x2=1
Мой подход заключался бы в том, чтобы рассматривать уравнения как ограничения и вычислять сумму остатков, как показано в приведенном выше примере.
Решить эту проблему без неопределенностей - не проблема. Я прошу получить подсказку, как учесть неопределенности при нахождении наиболее подходящих параметров.