Как бы вы сделали функцию сводной таблицы в Mathematica?
Сводные таблицы в Excel (или кросс-таблицы) весьма полезны. Кто-нибудь уже задумывался о том, как реализовать подобную функцию в Mathematica?
6 ответов
Я не знаком с использованием сводных таблиц, но, взяв пример на странице, указанной выше, я предлагаю следующее:
Needs["Calendar`"]
key = # -> #2[[1]] & ~MapIndexed~
{"Region", "Gender", "Style", "Ship Date", "Units", "Price", "Cost"};
choices = {
{"North", "South", "East", "West"},
{"Boy", "Girl"},
{"Tee", "Golf", "Fancy"},
IntegerString[#, 10, 2] <> "/2011" & /@ Range@12,
Range@15,
Range[8.00, 15.00, 0.01],
Range[6.00, 14.00, 0.01]
};
data = RandomChoice[#, 150] & /@ choices // Transpose;
Это создает data это выглядит так:
{"East", "Girl", "Golf", "03/2011", 6, 12.29`, 6.18`},
{"West", "Boy", "Fancy", "08/2011", 6, 13.01`, 12.39`},
{"North", "Girl", "Golf", "05/2011", 1, 14.87`, 12.89`},
{"East", "Girl", "Golf", "09/2011", 3, 13.99`, 6.25`},
{"North", "Girl", "Golf", "09/2011", 13, 12.66`, 8.57`},
{"East", "Boy", "Fancy", "10/2011", 2, 14.46`, 6.85`},
{"South", "Boy", "Golf", "11/2011", 13, 12.45`, 11.23`}
...
Затем:
h1 = Union@data[[All, "Region" /. key]];
h2 = Union@data[[All, "Ship Date" /. key]];
Reap[
Sow[#[[{"Units", "Ship Date"} /. key]], #[["Region" /. key]]] & ~Scan~ data,
h1,
Reap[Sow @@@ #2, h2, Total @ #2 &][[2]] &
][[2]];
TableForm[Join @@ %, TableHeadings -> {h1, h2}]
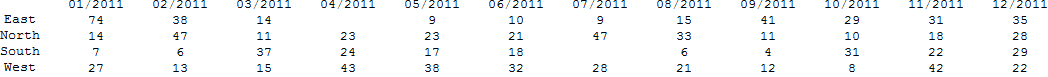
Это грубый пример, но он дает представление о том, как это можно сделать. Если у вас есть более конкретные требования, я постараюсь их решить.
Вот обновление в манере ответа Шёрда.
Manipulate блок в основном скопирован, но я считаю, что мой pivotTableData более эффективен, и я попытался правильно локализовать символы, поскольку теперь он представлен в виде удобного для использования кода, а не грубого примера.
Я начинаю с тех же данных примера, но я встраиваю заголовки полей, так как считаю, что это более типично для нормального использования.
data = ImportString[#, "TSV"][[1]] & /@ Flatten[Import["http://lib.stat.cmu.edu/datasets/CPS_85_Wages"][[28 ;; -7]]];
data = Transpose[{
data[[All, 1]],
data[[All, 2]] /. {1 -> "South", 0 -> "Elsewhere"},
data[[All, 3]] /. {1 -> "Female", 0 -> "Male"},
data[[All, 4]],
data[[All, 5]] /. {1 -> "Union Member", 0 -> "No member"},
data[[All, 6]],
data[[All, 7]],
data[[All, 8]] /. {1 -> "Other", 2 -> "Hispanic", 3 -> "White"},
data[[All, 9]] /. {1 -> "Management", 2 -> "Sales", 3 -> "Clerical", 4 -> "Service", 5 -> "Professional", 6 -> "Other"},
data[[All, 10]] /. {0 -> "Other", 1 -> "Manufacturing", 2 -> "Construction"},
data[[All, 11]] /. {1 -> "Married", 0 -> "Unmarried"}
}];
PrependTo[data,
{"Education", "South", "Sex", "Experience", "Union", "Wage", "Age", "Race", "Occupation", "Sector", "Marriatal status"}
];
мой pivotTableData самодостаточен
pivotTableData[data_, field1_, field2_, dependent_, op_] :=
Module[{key, sow, h1, h2, ff},
(key@# = #2[[1]]) & ~MapIndexed~ data[[1]];
sow = #[[key /@ {dependent, field2}]] ~Sow~ #[[key@field1]] &;
{h1, h2} = Union@data[[2 ;;, key@#]] & /@ {field1, field2};
ff = # /. {{} -> Missing@"NotAvailable", _ :> op @@ #} &;
{
{h1, h2},
Join @@ Reap[sow ~Scan~ Rest@data, h1, ff /@ Reap[Sow @@@ #2, h2][[2]] &][[2]]
}
]
pivotTable опирается только на pivotTableData:
pivotTable[data_?MatrixQ] :=
DynamicModule[{raw, t, header = data[[1]], opList =
{Mean -> "Mean of \[Rule]",
Total -> "Sum of \[Rule]",
Length -> "Count of \[Rule]",
StandardDeviation -> "SD of \[Rule]",
Min -> "Min of \[Rule]",
Max -> "Max of \[Rule]"}},
Manipulate[
raw = pivotTableData[data, f1, f2, f3, op];
t = ConstantArray["", Length /@ raw[[1]] + 2];
t[[1, 1]] = Control[{op, opList}];
t[[1, 3]] = Control[{f2, header}];
t[[2, 1]] = Control[{f1, header}];
t[[1, 2]] = Control[{f3, header}];
{{t[[3 ;; -1, 1]], t[[2, 3 ;; -1]]}, t[[3 ;; -1, 3 ;; -1]]} = raw;
TableView[N@t, Dividers -> All],
Initialization :> {op = Mean, f1 = data[[1,1]], f2 = data[[1,2]], f3 = data[[1,3]]}
]
]
Использовать просто:
pivotTable[data]
Быстрая и грязная визуализация сводной таблицы:
Я начну с более интересного набора реальных данных:
data = ImportString[#, "TSV"][[1]] & /@
Flatten[Import["http://lib.stat.cmu.edu/datasets/CPS_85_Wages"][[28 ;; -7]]
];
Немного пост-обработки:
data =
{
data[[All, 1]],
data[[All, 2]] /. {1 -> "South", 0 -> "Elsewhere"},
data[[All, 3]] /. {1 -> "Female", 0 -> "Male"},
data[[All, 4]],
data[[All, 5]] /. {1 -> "Union Member", 0 -> "No member"},
data[[All, 6]],
data[[All, 7]],
data[[All, 8]] /. {1 -> "Other", 2 -> "Hispanic", 3 -> "White"},
data[[All, 9]] /. {1 -> "Management", 2 -> "Sales", 3 -> "Clerical",
4 -> "Service", 5 -> "Professional", 6 -> "Other"},
data[[All, 10]] /. {0 -> "Other", 1 -> "Manufacturing", 2 -> "Construction"},
data[[All, 11]] /. {1 -> "Married", 0 -> "Unmarried"}
}\[Transpose];
header = {"Education", "South", "Sex", "Experience", "Union", "Wage",
"Age", "Race", "Occupation", "Sector", "Marriatal status"};
MapIndexed[(headerNumber[#1] = #2[[1]]) &, header];
levelNames = Union /@ Transpose[data];
levelLength = Length /@ levelNames;
Теперь о реальных вещах. Также используется функция SelectEquivalents определено в разделе Что находится в вашей сумке для инструментов Mathematica?
pivotTableData[levelName1_, levelName2_, dependent_, op_] :=
Table[
SelectEquivalents[data,
FinalFunction -> (If[Length[#] == 0, Missing["NotAvailable"], op[# // Flatten]] &),
TagPattern ->
_?(#[[headerNumber[levelName1]]] == levelMember1 &&
#[[headerNumber[levelName2]]] == levelMember2 &),
TransformElement -> (#[[headerNumber[dependent]]] &)
],
{levelMember1, levelNames[[headerNumber[levelName1]]]},
{levelMember2, levelNames[[headerNumber[levelName2]]]}
]
DynamicModule[
{opList =
{Mean ->"Mean of \[Rule]", Total ->"Sum of \[Rule]", Length ->"Count of \[Rule]",
StandardDeviation -> "SD of \[Rule]", Min -> "Min of \[Rule]",
Max -> "Max of \[Rule]"
}, t},
Manipulate[
t=Table["",{levelLength[[headerNumber[h1]]]+2},{levelLength[[headerNumber[h2]]]+2}];
t[[3 ;; -1, 1]] = levelNames[[headerNumber[h1]]];
t[[2, 3 ;; -1]] = levelNames[[headerNumber[h2]]];
t[[1, 1]] = Control[{op, opList}];
t[[1, 3]] = Control[{h2, header}];
t[[2, 1]] = Control[{h1, header}];
t[[1, 2]] = Control[{h3, header}];
t[[3 ;; -1, 3 ;; -1]] = pivotTableData[h1, h2, h3, op] // N;
TableView[t, Dividers -> All],
Initialization :> {op = Mean, h1 = "Sector", h2 = "Union", h3 = "Wage"}
]
]
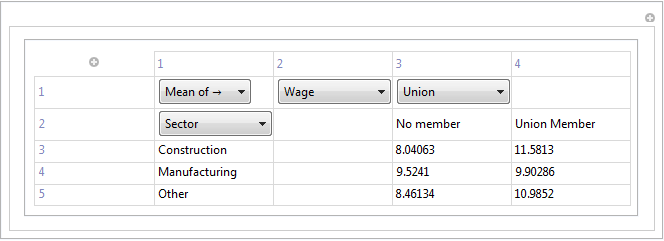
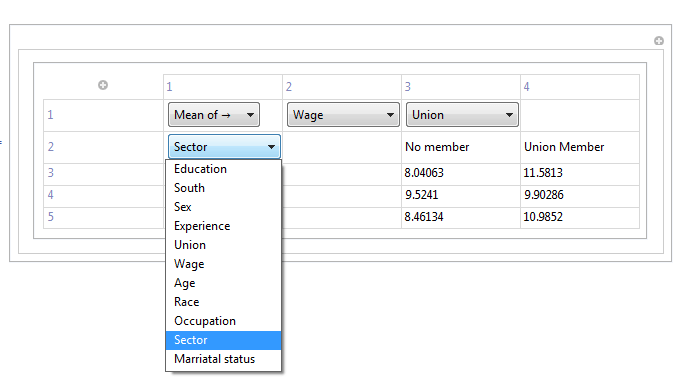
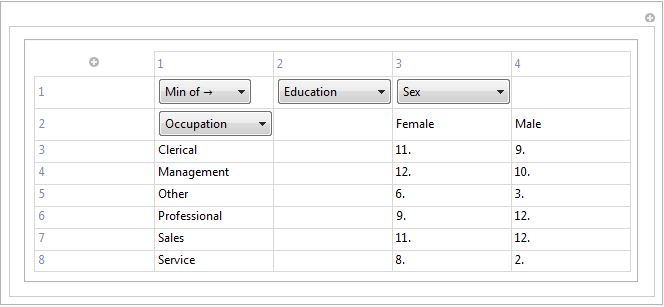
Там еще немного работы, чтобы сделать. DynamicModule должна быть превращена в полностью автономную функцию с более упорядоченным заголовком, но этого должно быть достаточно для первого впечатления.
@ Ответ Mr.Wizard действительно надежный и продолжительный, поскольку он основан на методе ReapSow, подходящем для некоторых карт, сокращающих количество рабочих мест в Mathematica. В связи с тем, что само ММА развивается, рассмотрим и новый вариант.
GroupBy (введенный в Mathematica v.10.0) обеспечивает обобщение операции сокращения карты.
Итак, выше data Задание может быть реализовано следующим образом (частично излишним для удобства чтения):
headings = Union @ data[[All, #]] & /@ {1, 4}
{{"Восток", "Север", "Юг", "Запад"}, {"01/2011", "02/2011", "03/2011", "04/2011", "05/2011", "06/2011", "07/2011", "08/2011", "09/2011", "10/2011", "11/2011", "12/2011"}}
Мы можем использовать Outer, чтобы настроить прямоугольный шаблон для TableForm:
template = Outer[List, Apply[Sequence][headings]];
Основная работа с GroupBy и Total в качестве третьего аргумента:
pattern = Append[Normal @
GroupBy[data, (#[[{1, 4}]] &) -> (#[[-1]] &), Total],
_ -> Null];
Наконец, вставьте шаблон в шаблон (и примените заголовки TableForm для красоты):
TableForm[Replace[template, pattern, {2}], TableHeadings -> headings]
Это выводит некоторые:
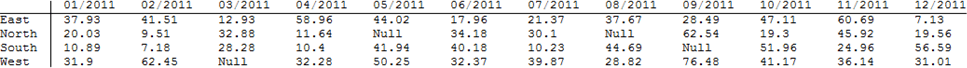
Примечание: мы сделали итоговый последний столбец в data, (Конечно, возможны и другие агрегации.)
Используйте http://www.wolfram.com/products/applications/excel_link/, таким образом, вы получите лучшее из обоих миров. Этот продукт создает безупречную связь между Excel и mma, 2-way.
Вот что я придумала. Он использует функцию SelectEquivalents, определенную в разделе Что находится в вашей сумке с инструментами Mathematica?, Функция1 и функция2 должны иметь различные возможности группировки критериев1 и критериев2. FilterFunction здесь для того, чтобы определить произвольную формулу фильтра для данных на основе имен заголовков.
Используя пример данных Mr. Wizard, здесь приведены некоторые примеры использования этой функции.
criteria={"Region", "Gender", "Style", "Ship Date", "Units", "Price", "Cost"};
criteria1 = "Region";
criteria2 = "Ship Date";
consideredData = "Units";
PivotTable[data,criteria,criteria1,criteria2,consideredData]
Аккуратный пример
function2 = If[ToExpression@StringTake[#, 2] <= 6, "First Semester", "Second Semester"] &;
PivotTable[data,criteria,criteria1,criteria2,consideredData,FilterFunction->("Gender"=="Girl"&&"Units"*"Price"<=100&),Function2->function2]
Вот определение функции
keysToIndex[keys_] :=
Module[{keyIndex},
(keyIndex[#1] = #2[[1]])&~MapIndexed~keys;
keyIndex
];
InverseFlatten[l_,dimensions_]:= Fold[Partition[#, #2] &, l, Most[Reverse[dimensions]]];
Options[PivotTable]={Function1->Identity,Function2->Identity,FilterFunction->(True &),AggregationFunction->Total,FormatOutput->True};
PivotTable[data_,criteria_,criteria1_,criteria2_,consideredData_,OptionsPattern[]]:=
Module[{criteriaIndex, criteria1Index, criteria2Index, consideredDataIndex, criteria1Function, criteria2Function, filterFunctionTranslated, filteredResult, keys1, keys1Index, keys2, keys2Index, resultTable, function1, function2, filterFunction, aggregationFunction, formatOutput,p,sharp},
function1 = OptionValue@Function1;
function2 = OptionValue@Function2;
filterFunction = OptionValue@FilterFunction;
aggregationFunction = OptionValue@AggregationFunction;
formatOutput=OptionValue@FormatOutput;
criteriaIndex=keysToIndex[criteria];
criteria1Index=criteriaIndex@criteria1;
criteria2Index=criteriaIndex@criteria2;
consideredDataIndex=criteriaIndex@consideredData;
criteria1Function=Composition[function1,#[[criteria1Index]]&];
criteria2Function=Composition[function2,#[[criteria2Index]]&];
filterFunctionTranslated = filterFunction/.(# -> p[sharp, criteriaIndex@#]& /@ criteria /. sharp -> #)/.p->Part;
filteredResult=
SelectEquivalents[
data
,
TagElement->({criteria1Function@#,criteria2Function@#,filterFunctionTranslated@#}&)
,
TransformElement->(#[[consideredDataIndex]]&)
,
TagPattern->_?(#[[3]]&)
,
TransformResults->(Append[Most@#1,aggregationFunction@#2]&)
];
If[formatOutput,
keys1=filteredResult[[All,1]]//Union//Sort;
keys2=filteredResult[[All,2]]//Union//Sort;
resultTable=
SelectEquivalents[
filteredResult
,
TagElement->(#[[{1,2}]]&)
,
TransformElement->(#[[3]]&)
,
TagPattern->Flatten[Outer[List, keys1, keys2], 1]
,
FinalFunction-> (InverseFlatten[Flatten[#/.{}->Missing[]],{Length@keys1,Length@keys2}]&)
];
TableForm[resultTable,TableHeadings->{keys1,keys2}]
,
filteredResult
]
];
Я немного последний в игре. Вот еще одно автономное решение с объектоподобной формой.
Используя случайные данные, созданные @Mr.Wizard:
key = # -> #2[[1]] & ~MapIndexed~
{"Region", "Gender", "Style", "Ship Date", "Units", "Price", "Cost"};
choices = {
{"North", "South", "East", "West"},
{"Boy", "Girl"},
{"Tee", "Golf", "Fancy"},
IntegerString[#, 10, 2] <> "/2011" & /@ Range@12,
Range@15,
Range[8.00, 15.00, 0.01],
Range[6.00, 14.00, 0.01]
};
data = RandomChoice[#, 5000] & /@ choices // Transpose;
Используя MapIndexed а также SparseArray в качестве ключевых функций, вот код:
Options[createPivotTable]={"RowColValueHeads"-> {1,2,3},"Function"-> Total};
createPivotTable[data_,opts:OptionsPattern[{createPivotTable}]]:=Module[{r,c,v,aggDataIndex,rowRule,colRule,pivot},
{r,c,v}=OptionValue["RowColValueHeads"];
pivot["Row"]= Union@data[[All,r]];
pivot["Col"]= Union@data[[All,c]];
rowRule= Dispatch[#->#2[[1]]&~MapIndexed~pivot["Row"]];
colRule= Dispatch[#->#2[[1]]&~MapIndexed~pivot["Col"]];
aggDataIndex={#[[1,r]]/.rowRule,#[[1,c]]/.colRule}->OptionValue["Function"]@#[[All,v]]&/@GatherBy[data,#[[{r,c}]]&];
pivot["Data"]=Normal@SparseArray@aggDataIndex;
pivot["Properties"]={"Data","Row","Col"};
pivot["Table"]=TableForm[pivot["Data"], TableHeadings -> {pivot["Row"], pivot["Col"]}];
Format[pivot]:="PivotObject";
pivot
]
Это вы можете использовать как:
pivot=createPivotTable[data,"RowColValueHeads"-> ({"Ship Date","Region","Units"}/.key)];
pivot["Table"]
pivot["Data"]
pivot["Row"]
pivot["Col"]
Получить:
Я считаю, что скорость выше, чем у @Ms.Wizard, но мне нужно сделать лучший тест, и сейчас у меня нет времени.