Что конкретно помечает строку кэша x86 как грязную - любая запись или требуется явное изменение?
Этот вопрос специально нацелен на современные когерентные архитектуры x86-64 - я ценю, что ответ может отличаться на других процессорах.
Если я записываю в память, протокол MESI требует, чтобы строка кэша сначала читалась в кэш, а затем изменялась в кэше (значение записывается в строку кэша, которая затем помечается как грязная). В более старых микроархитектурах записи это могло бы привести к сбросу строки кэша, при обратной записи очистка строки кэша может быть отложена на некоторое время, и некоторое объединение записи может происходить в обоих механизмах (более вероятно при обратной записи), И я знаю, как это взаимодействует с другими ядрами, обращающимися к одной и той же строке кэша данных - отслеживание кэша и т. Д.
Мой вопрос: если хранилище точно соответствует значению, уже находящемуся в кэше, если не перевернут ни одного бита, заметит ли это какая-либо микроархитектура Intel и НЕ пометит строку как грязную, и, таким образом, возможно, сохранит ее как помеченную как эксклюзив, а какие накладные расходы памяти обратной записи, которые в какой-то момент последуют?
Поскольку я векторизовал больше своих циклов, мои составные примитивы векторизованных операций явно не проверяют изменение значений, и делать это в CPU/ALU кажется расточительным, но мне было интересно, может ли базовая схема кэша сделать это без явного кодирования (например, магазин микрооперации или сама логика кеша). Поскольку пропускная способность разделяемой памяти между несколькими ядрами становится все более узким местом для ресурсов, это может показаться все более полезной оптимизацией (например, повторное обнуление одного и того же буфера памяти - мы не перечитываем значения из ОЗУ, если они уже в кеше, но принудительная перезапись тех же значений кажется расточительной). Кэширование обратной записи само по себе является подтверждением такого рода проблем.
Могу ли я вежливо попросить воздержаться от ответов "в теории" или "это действительно не имеет значения" - я знаю, как работает модель памяти, что я ищу, так это неопровержимые факты о том, как записать одно и то же значение (в отличие от того, чтобы избегать хранилище) повлияет на конкуренцию за шину памяти на том, что вы можете с уверенностью предположить, что это машина, на которой выполняются множественные рабочие нагрузки, почти всегда связанные пропускной способностью памяти. С другой стороны, объяснение точных причин, почему чипы не делают этого (я пессимистично предполагаю, что они этого не делают), было бы поучительно...
Обновление: некоторые ответы в соответствии с ожидаемыми линиями здесь https://softwareengineering.stackexchange.com/questions/302705/are-there-cpus-that-perform-this-possible-l1-cache-write-optimization но все еще очень много спекуляция "это должно быть сложно, потому что это не сделано" и высказывание, что выполнение этого в основном ядре ЦП будет дорогостоящим (но я все еще задаюсь вопросом, почему это не может быть частью самой логики кеша).
2 ответа
В настоящее время ни одна реализация x86 (или любая другая ISA, насколько я знаю) не поддерживает оптимизацию хранилищ без вывода сообщений.
Было проведено научное исследование по этому вопросу, и даже есть патент на "устранение распространения аннулирования хранилища без вывода сообщений в протоколах когерентности кэша совместно используемой памяти". (Погуглите кеш "тихого магазина", если вас интересует больше.)
Для x86 это будет мешать MONITOR/MWAIT; Некоторые пользователи могут захотеть, чтобы поток мониторинга проснулся в хранилище без вывода сообщений (можно было бы избежать аннулирования и добавить сообщение о "касании"). (В настоящее время MONITOR / MWAIT является привилегированным, но это может измениться в будущем.)
Подобным образом, это может помешать некоторым умным использованиям транзакционной памяти. Если область памяти используется в качестве защиты, чтобы избежать явной загрузки других областей памяти или, в архитектуре, которая ее поддерживает (например, в AMD Advanced Synchronization Facility), удаление удаленных областей памяти из набора для чтения.
(Аппаратная блокировка Elision является очень ограниченной реализацией автоматического исключения хранилища ABA. У нее есть преимущество реализации, заключающееся в том, что проверка согласованности значений явно запрашивается.)
Есть также проблемы реализации с точки зрения влияния на производительность / сложности дизайна. Такое запрещало бы избегать чтения для владения (если исключение хранилища без вывода сообщений было активным, только когда строка кэша уже присутствовала в общем состоянии), хотя избегание чтения для владения также в настоящее время не реализовано.
Специальная обработка хранилищ без вывода сообщений также усложнит реализацию модели согласованности памяти (вероятно, особенно относительно сильной модели x86). Это также может увеличить частоту откатов на спекуляциях, которые не смогли согласоваться. Если бы хранилища без вывода сообщений поддерживались только для линий L1-присутствует, временное окно было бы очень маленьким, а откаты чрезвычайно редкими; сохранение в кэш-памяти строк L3 или памяти может увеличить частоту до очень редкого значения, что может сделать ее заметной проблемой.
Молчание при гранулярности строки кэша также менее распространено, чем молчание на уровне доступа, поэтому число предотвращенных недействительности будет меньше.
Дополнительная пропускная способность кэша также будет проблемой. В настоящее время Intel использует четность только на кэшах L1, чтобы избежать необходимости чтения-изменения-записи при небольших операциях записи. Требование каждой записи иметь чтение для обнаружения хранилищ без вывода сообщений имело бы очевидные последствия для производительности и мощности. (Такое чтение может быть ограничено строками общего кэша и может выполняться оппортунистически, используя циклы без полного использования доступа к кэшу, но это все равно потребует затрат на электроэнергию.) Это также означает, что эти затраты упадут, если поддержка чтения-изменения-записи будет уже присутствует для поддержки L1 ECC (эта функция порадует некоторых пользователей).
Я не очень хорошо разбираюсь в устранении хранилищ без вывода сообщений, поэтому, возможно, есть и другие проблемы (и обходные пути).
Поскольку большая часть низко висящих плодов для повышения производительности уже была достигнута, более сложные, менее выгодные и менее общие оптимизации становятся более привлекательными. Поскольку оптимизация хранилища в режиме без вывода сообщений становится все более важной с ростом числа межъядерных соединений, а связь между ядрами будет возрастать по мере использования большего количества ядер для работы над одной задачей, значение такого показателя, вероятно, возрастет.
Это возможно реализовать на аппаратном уровне, но я не думаю, что кто-то делает. Выполнение этого для каждого магазина будет стоить пропускной способности для чтения из кэша или потребует дополнительного порта чтения и усложнит конвейеризацию.
Вы бы построили кеш, который выполнял цикл чтения / сравнения / записи вместо простой записи и мог бы условно оставить строку в исключительном состоянии вместо модифицированного ( MESI). Делая это таким образом (вместо проверки, пока он еще был Shared) все равно лишает законной силы другие копии строки, но это означает, что нет никакого взаимодействия с упорядочением памяти. Хранилище (без вывода сообщений) становится глобально видимым, в то время как ядро обладает исключительным владением строкой кэша, так же, как если бы оно переключилось на "Модифицированный", а затем обратно на "Исключительное", выполнив обратную запись в DRAM.
Чтение / сравнение / запись должны выполняться атомарно (вы не можете потерять строку кэша между чтением и записью; если это произойдет, результат сравнения будет устаревшим). Это затрудняет передачу данных, поступающих на L1D из очереди хранилища.
В многопоточной программе может быть целесообразно сделать это как оптимизацию программного обеспечения только для общих переменных.
Избегайте аннулирования чьего-либо кеша, поэтому стоит конвертировать
shared = x;
в
if(shared != x)
shared = x;
Я не уверен, есть ли здесь смысл упорядочения памяти. Очевидно, что если shared = x никогда не бывает, нет последовательности релиза, так что вам нужно только получить семантику вместо релиза. Но если ценность, которую вы храните, часто является той, которая уже есть, любое ее использование для заказа других вещей будет иметь проблемы с ABA.
IIRC, Херб Саттер упоминает эту потенциальную оптимизацию в первой или второй части своего атомного оружия: доклад о модели памяти C++ и о современном аппаратном обеспечении. (Пару часов видео)
Это, конечно, слишком дорого, чтобы делать это в программном обеспечении для чего-либо, кроме общих переменных, где стоимость их записи - много циклов задержки в других потоках (ошибки кеша и ошибки в предположении порядка памяти: машина очищается: каковы затраты на задержку и пропускную способность совместного использования производителем-потребителем места в памяти между гипер-братьями и сестрами и не-гипер-братьями?)
См. Этот ответ для получения дополнительной информации о пропускной способности памяти x86 в целом, особенно о ресурсах NT и non-NT, а также о "платформах с привязкой к задержке", чтобы узнать, почему пропускная способность однопоточной памяти на многоядерных Xeons ниже, чем на четырехъядерных. ядро, хотя совокупная пропускная способность от нескольких ядер выше.
Я нашел доказательства того, что некоторые современные процессоры x86 от Intel, включая клиентские чипы Skylake и Ice Lake, могут оптимизировать избыточные (тихие) хранилища по крайней мере в одном конкретном случае:
- Строка кэша со всеми нулями полностью или частично перезаписывается нулями.
То есть сценарий "нули над нулями".
Например, эта диаграмма показывает производительность (кружки, измеренные на левой оси) и соответствующие счетчики производительности для сценария, в котором область переменного размера заполнена 32-битными значениями нуля или единицы на Ice Lake:
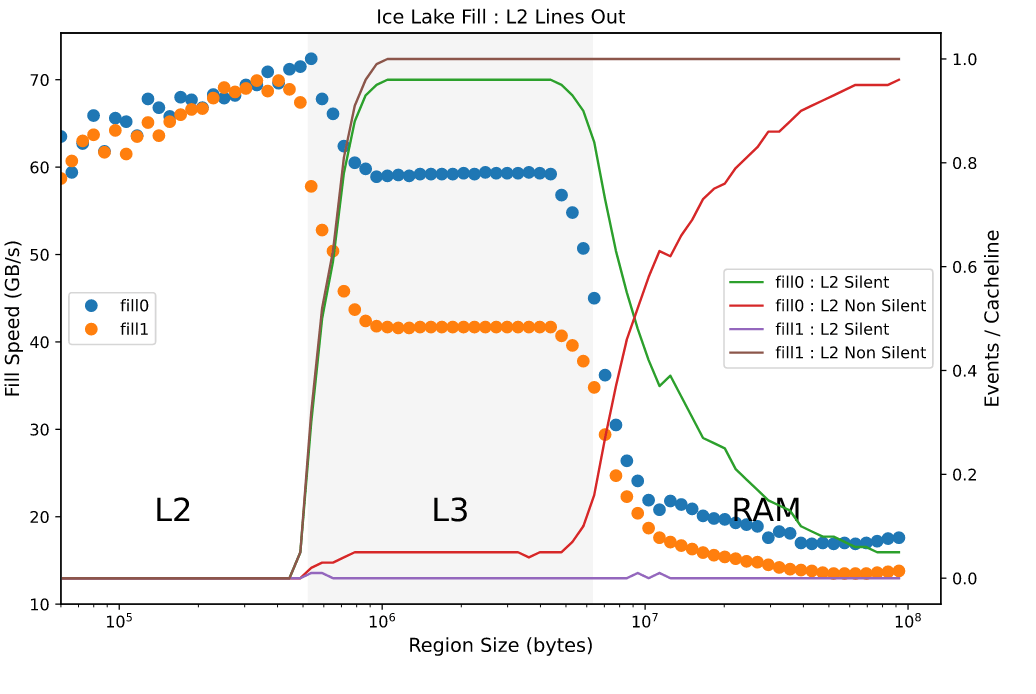
Как только область больше не помещается в кэш L2, появляется явное преимущество записи нулей: пропускная способность заполнения почти в 1,5 раза выше. В случае нулей мы также видим, что выселения из L2 не почти все "тихие", что указывает на то, что не нужно записывать грязные данные, в то время как в другом случае все выселения не молчаливы.
Некоторые другие подробности об этой оптимизации:
- Он оптимизирует обратную запись строки грязного кэша, а не RFO, который все еще должен произойти (действительно, чтение, вероятно, необходимо, чтобы решить, можно ли применить оптимизацию).
- Похоже, это происходит вокруг интерфейса L2 или L2 <-> L3. То есть я не нахожу доказательств этой оптимизации для нагрузок, которые подходят для L1 или L2.
- Поскольку оптимизация вступает в силу в какой-то момент за пределами самого внутреннего уровня иерархии кеша, нет необходимости записывать только нули, чтобы воспользоваться преимуществом: достаточно, чтобы строка содержала все нули только после того, как она была записана обратно в L3. Итак, начиная с нулевой строки, вы можете выполнить любое количество ненулевых операций записи, за которыми следует окончательная запись нуля для всей строки 1, пока эта строка не перейдет на L3.
- Оптимизация влияет на производительность по-разному: иногда оптимизация выполняется на основе наблюдения за соответствующими счетчиками производительности, но почти не увеличивается пропускная способность. В других случаях воздействие может быть очень большим.
- Я не нахожу доказательств эффекта в сервере Skylake или более ранних чипах Intel.
Я описал это более подробно здесь, и есть приложение для Ice Lake, которое здесь сильнее демонстрирует этот эффект.
1 Или хотя бы перезаписать ненулевые части строки нулями.