Повышение (дезагрегация) суммированных квартальных данных к ежемесячным данным
Я пытаюсь повысить данные с агрегированных квартальных до ежемесячных данных, но цифры, показанные ниже, не являются тем, что мне нужно. Мне нужно, чтобы эти точки данных были разбиты на месячные числа (которые добавляются к следующему кварталу). Таким образом, каждое новое значение должно составлять около трети следующего квартала.
i = ['2000-01-01','2000-04-01','2000-07-01','2000-10-01','2001-01-01','2001-04-01','2001-07-01','2001-10-01']
d = [0,54957.84767,0,0,0,56285.54879,0,0]
df = pd.DataFrame(index=i, data=d)
df.index = pd.to_datetime(df.index,infer_datetime_format=True)
df.index = df.index.to_period('Q')
df.resample('M').first().interpolate(method='cubic')
ОБНОВЛЕНИЕ: допустим, серия игрушек [0,0,9]. Итак, январь, февраль, март. Значение в конце марта равно 9. Я бы хотел, чтобы интерполированный результат был [3,3,3]. Таким образом, каждый месяц имеет значение 3, и когда вы объединяете их обратно в кварталы, это снова приводит к 9.
2 ответа
То, что вы хотите сделать, на самом деле невозможно только с двумя точками данных. Компания обычно имеет некоторый полиномиальный или экспоненциальный рост, но только с двумя точками данных вы не можете соответствовать такой сложной кривой роста. Возможна только линейная интерполяция.
Но давайте предположим, что у вас есть третий пункт
import pandas as pd
date = pd.date_range('2000-4-1', periods=3, freq='4Q') # quarter _end_!
Qsales = [54957.84767, 56285.54879, 58277.10047]
df = pd.DataFrame({'Quarter sales':Qsales}, index=pd.Index(date, name='date'))
print(df)
import matplotlib.pyplot as plt
plt.plot(df.index, df['Quarter sales'])
plt.show()
Это показывает:
Quarter sales
date
2000-06-30 54957.84767
2001-06-30 56285.54879
2002-06-30 58277.10047
Теперь мы можем что-то сделать. Давайте подгоним экспоненциальную кривую в соответствии с y = offset + factor * base^x, редактировать: я использую pd.datetime(2000, 1, 1) в качестве нулевой точки здесь.
#### curve fitting
import numpy as np
date_delta = (date - pd.datetime(2000, 1, 1)) /np.timedelta64(1,'M')
## convert data to x/y
x = date_delta.values
y = df['Quarter sales'].values
## expected function
def expFunc(x, offset, factor, base) : return offset + factor * base**x
## initial guess
guess = (53000, 1000, 1.05)
## call scipy curve fitting
from scipy.optimize import curve_fit
params = curve_fit(expFunc, x, y, guess)
## now first generate data for all quarters using interpolation
# generate new dates
date = pd.date_range('2000-1-1', periods=3*4, freq='Q') # quarter _end_!
date_delta = (date - pd.datetime(2000,1,1)) / np.timedelta64(1, 'M')
x = date_delta.values
Qsales = expFunc(x, params[0][0], params[0][1], params[0][2])
df = pd.DataFrame({'Quarter sales':Qsales}, index=pd.Index(date, name='date'))
print(df)
plt.plot(df.index, df['Quarter sales'])
plt.show()
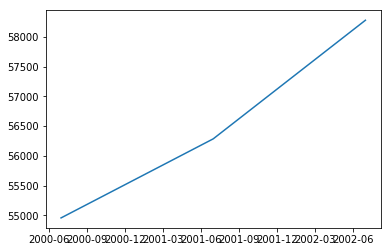
Это дает:
Quarter sales
date
2000-03-31 54702.538666
2000-06-30 54957.847670
2000-09-30 55243.580457
2000-12-31 55560.059331
2001-03-31 55902.585284
2001-06-30 56285.548790
2001-09-30 56714.147971
2001-12-31 57188.866281
2002-03-31 57702.655211
2002-06-30 58277.100470
2002-09-30 58919.999241
2002-12-31 59632.076706

Теперь это все сглаживает. Но этого все еще недостаточно. Вам необходимо определить объем продаж за месяц. Ну, поскольку вы теперь знаете кривую, вы можете распределить рост в месяц в соответствии с:
#now further interpolate to months
date = pd.date_range('2000-1-1', periods=3*12, freq='M') # month _end_!
date_delta = (date - pd.datetime(2000, 1, 1)) / np.timedelta64(1,'M')
x = date_delta.values
# first determine the exponential factor per month
dateFactors = expFunc(x, params[0][0], params[0][1], params[0][2])
MFactorSeries = pd.Series(dateFactors, index=date)
# now sum the exponential factors to get them for the quarters
QFactorSeries = MFactorSeries.resample('Q').sum()
# and divide them by the quartarly sales to get a monthly sales base
MSalesBase = np.divide(Qsales, QFactorSeries.values)
#now some numpy tricks to get the monthly sales
Msales = np.multiply(dateFactors.reshape(12,3), MSalesBase.reshape(12,1)).flatten()
df = pd.DataFrame({'Monthly sales':Msales}, index=pd.Index(date, name='date'))
print(df)
plt.plot(df.index, df['Monthly sales'])
plt.show()
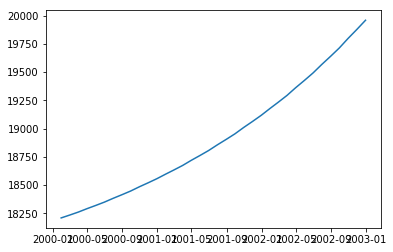
Это дает:
Monthly sales
date
2000-01-31 18208.780004
2000-02-29 18233.319078
2000-03-31 18260.439584
2000-04-30 18290.245845
2000-05-31 18319.272021
2000-06-30 18348.329804
2000-07-31 18382.360436
2000-08-31 18414.515147
2000-09-30 18446.704874
2000-10-31 18484.774541
2000-11-30 18519.227954
2000-12-31 18556.056836
2001-01-31 18596.904560
2001-02-28 18632.486725
2001-03-31 18673.193999
2001-04-30 18718.262419
2001-05-31 18761.833781
2001-06-30 18805.452590
2001-07-31 18856.427507
2001-08-31 18904.698469
2001-09-30 18953.021996
2001-10-31 19010.040490
2001-11-30 19061.766635
2001-12-31 19117.059156
2002-01-31 19178.229496
2002-02-28 19231.653416
2002-03-31 19292.772298
2002-04-30 19360.251134
2002-05-31 19425.676408
2002-06-30 19491.172928
2002-07-31 19567.484781
2002-08-31 19639.973435
2002-09-30 19712.541026
2002-10-31 19797.887582
2002-11-30 19875.573492
2002-12-31 19958.615633
Заметка
Я не специалист по пандам, скипетам, нямпи и т. Д. Это то, как я должен делать это, используя свое инженерное образование.
Вы можете сделать это, но method=cubic не работает из-за NaN.
df.resample('M').asfreq().interpolate()
Выход:
0
2000-01 0.000000
2000-02 18319.282557
2000-03 36638.565113
2000-04 54957.847670
2000-05 36638.565113
2000-06 18319.282557
2000-07 0.000000
2000-08 0.000000
2000-09 0.000000
2000-10 0.000000
2000-11 0.000000
2000-12 0.000000
2001-01 0.000000
2001-02 18761.849597
2001-03 37523.699193
2001-04 56285.548790
2001-05 37523.699193
2001-06 18761.849597
2001-07 0.000000
2001-08 0.000000
2001-09 0.000000
2001-10 0.000000
2001-11 0.000000
2001-12 0.000000