Оптимизация нумерации страниц в функциональных представлениях (в Django)
В классном Джанго listviewкогда кто-то присваивает значение paginate_by, это гарантирует, что object_list доступно в get_context_data Метод ограничен только теми объектами, которые необходимы для этой конкретной страницы.
Например get_queryset может вернуть 1000 объектов, но если на одной странице будет отображаться 20 объектов, то только 20 объектов доступны как object_list в get_context_data, Это хорошая оптимизация при работе с большими наборами запросов.
Как можно создать такое же поведение в функциональных представлениях? При типичной реализации (и с использованием вышеупомянутого примера) все 1000 объектов будут оцениваться и затем использоваться для разбивки на страницы. Это означает, что в данном конкретном случае CBV определенно лучше, чем функциональные представления. Могут ли функциональные представления обеспечивать одинаковую функциональность? Был бы наглядный пример (или ответ типа "нет, они не могут").
Вот фактический CBV:
class PostListView(ListView):
model = Post
paginate_by = 20
template_name = "post_list.html"
def get_queryset(self):
return all_posts()
def get_context_data(self, **kwargs):
context = super(PostListView, self).get_context_data(**kwargs)
posts = retrieve_posts(context["object_list"]) #retrieves 20 posts
return context
Вот фактический FBV:
def post_list(request, *args, **kwargs):
form = PostListForm()
context = {}
obj_list = all_posts()
posts = retrieve_posts(obj_list) #retrieves 1000 posts
paginator = Paginator(posts, 20)
page = request.GET.get('page', '1')
try:
page = paginator.page(page)
except PageNotAnInteger:
page = paginator.page(1)
except EmptyPage:
page = paginator.page(paginator.num_pages)
retrieve_posts() функция:
def retrieve_posts(post_id_list):
my_server = redis.Redis(connection_pool=POOL)
posts = []
pipeline1 = my_server.pipeline()
for post_id in post_id_list:
hash_name="pt:"+str(post_id)
pipeline1.hgetall(hash_name)
result1 = pipeline1.execute()
count = 0
for hash_obj in result1:
posts.append(hash_obj)
count += 1
return posts
all_posts() функция:
def all_posts():
my_server = redis.Redis(connection_pool=POOL)
return my_server.lrange("posts:1000", 0, -1) #list of ids of 1000 posts
Разница во времени отклика двух подходов (через newrelic):
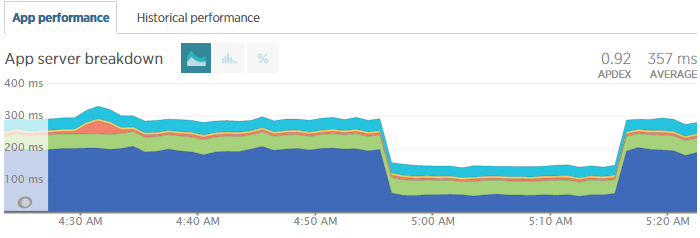
Синяя часть - это обработка вида.
1 ответ
Не звони retreive_posts с оригинальным списком объектов. Используйте список объектов страницы после разбивки на страницы.
posts = retrieve_posts(page.obj_list)