TikZ: построение файла данных с пропущенными значениями
У меня есть эти данные:

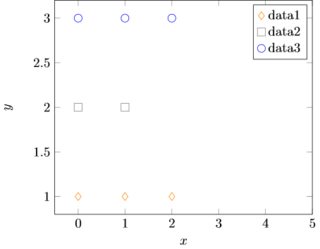
В data2 отсутствует третий пункт. Поэтому я подумал, что я бы определил два разных столбца x и назначил data2 x2.
Проблема: третий пункт data1 поднимается до 3 в скомпилированном графике. Если у меня разные и более значения, точки начинают уходить куда угодно, но не туда, где они принадлежат.
Вот код, который я использовал:
\addplot[only marks, mark = diamond, color = orange, mark size = 3pt]
table[x=x1, y=data1]{example.dat};
\addlegendentry{data1};
\addplot[only marks, mark = square, color = gray, mark size = 3pt]
table[x=x2, y=data2]{example.dat};
\addlegendentry{data2};
\addplot[only marks, mark = o, color = blue, mark size = 3pt]
table[x=x1, y=data3]{example.dat};
\addlegendentry{data3};
И вот график, который я получаю:

Большое спасибо!
Btw. в реальных данных в одном наборе данных отсутствует значение a x/y в середине данных. Я надеюсь, что это не имеет значения по сравнению с моим примером.
1 ответ
pgfplots интерпретирует 2 вкладки как один разделитель. Таким образом, он видит файл данных как:
x1 x2 data1 data2 data3
0 0 1 2 3
1 1 1 2 3
2 1 3
Решение 1. Вы можете заменить пустые ячейки на NaN. pgfplots будет правильно интерпретировать это:
x1 x2 data1 data2 data3
0 0 1 2 3
1 1 1 2 3
2 nan 1 nan 3
Решение 2. Используйте разделитель другого типа (например, точки с запятой или запятые):
\begin{filecontents*}{example.csv}
x1;x2;data1;data2;data3
0;0;1;2;3
1;1;1;2;3
2;;1;;3
\end{filecontents*}
\pgfplotstableread[col sep = semicolon]{example.csv}\mydata
\begin{document}
...
Здесь я включил файл данных в файл TeX, но он также должен работать с отдельным файлом данных.