Консоль Amazon S3: загрузка нескольких файлов одновременно
Когда я захожу на консоль S3, я не могу загрузить несколько выбранных файлов (веб-интерфейс позволяет загружать только когда выбран один файл):
https://console.aws.amazon.com/s3
Это что-то, что можно изменить в политике пользователя или это ограничение Amazon?
17 ответов
Это невозможно через веб-интерфейс пользователя. Но это очень простая задача, если вы устанавливаете AWS CLI. Вы можете проверить шаги установки и настройки в разделе Установка в интерфейсе командной строки AWS.
После этого вы идете в cmd. Тип:
aws s3 cp "S3 PATH" "LOCAL PATH" --recursive
Не используйте двойные кавычки. Это скопирует все файлы с заданного пути S3 на заданный локальный путь.
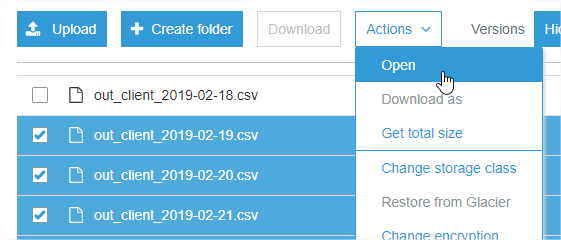
Выбрав набор файлов и нажав Действия-> Открыть, открыли каждый на вкладке браузера, и они сразу же начали загружаться (по 6 за раз).
Если вы используете AWS CLI, вы можете использовать exclude вместе с --include а также --recursive флаги для достижения этой цели
aws s3 cp s3://path/to/bucket/ . --recursive --exclude "*" --include "things_you_want"
Например.
--exclude "*" --include "*.txt"
загрузит все файлы с расширением.txt. Более подробная информация - https://docs.aws.amazon.com/cli/latest/reference/s3/
Если у вас установлена Visual Studio с установленным расширением AWS Explorer, вы также можете перейти к Amazon S3 (шаг 1), выбрать корзину (шаг 2), выбрать все файлы, которые вы хотите загрузить (шаг 3), и щелкнуть правой кнопкой мыши, чтобы загрузить их. все (шаг 4).

Я считаю, что это ограничение веб-интерфейса консоли AWS, поскольку я пытался (и не смог) сделать это сам.
В качестве альтернативы, возможно, используйте сторонний браузерный клиент S3, такой как http://s3browser.com/
Служба S3 не имеет значимых ограничений для одновременных загрузок (возможно несколько сотен загрузок за раз), и нет никакой политики, связанной с этим..., но консоль S3 позволяет выбирать только один файл для загрузки за раз.
Как только загрузка начнется, вы можете запустить другую и другую, столько, сколько ваш браузер позволит вам попробовать одновременно.
Используя AWS CLI, я запустил все загрузки в фоновом режиме с помощью «&», а затем дождался завершения всех pid. Это было потрясающе быстро. Очевидно, "aws s3 cp" знает, как ограничить количество одновременных подключений, потому что он запускал только 100 за раз.
aws --profile $awsProfile s3 cp "$s3path" "$tofile" &
pids[${npids}]=$! ## save the spawned pid
let "npids=npids+1"
с последующим
echo "waiting on $npids downloads"
for pid in ${pids[*]}; do
echo $pid
wait $pid
done
Скачал 1500+ файлов (72000 байт) примерно за минуту
Если кто-то все еще ищет браузер и загрузчик S3, я только что попробовал Fillezilla Pro (это платная версия). Это работало отлично.
Я создал соединение с S3 с ключом доступа и секретным ключом, настроенным через IAM. Подключение было мгновенным, и загрузка всех папок и файлов была быстрой.
Я сделал это, создав сценарий оболочки с помощью aws cli (например, example.sh)
#!/bin/bash
aws s3 cp s3://s3-bucket-path/example1.pdf LocalPath/Download/example1.pdf
aws s3 cp s3://s3-bucket-path/example2.pdf LocalPath/Download/example2.pdf
предоставить исполняемые права на example.sh (например, sudo chmod 777 example.sh)
затем запустите сценарий оболочки ./example.sh
Также, если вы работаете в Windows(tm), WinSCP теперь позволяет перетаскивать выбор нескольких файлов. Включая подпапки.
На многих рабочих станциях предприятия установлен WinSCP для редактирования файлов на серверах посредством SSH.
Я не аффилирован, я просто думаю, что это действительно стоило сделать.
Я думаю, что самый простой способ загружать или выгружать файлы - использовать команду aws s3 sync . Вы также можете использовать его для
sync два ведра s3 одновременно.
aws s3 sync <LocalPath> <S3Uri> or <S3Uri> <LocalPath> or <S3Uri> <S3Uri>
# Download file(s)
aws s3 sync s3://<bucket_name>/<file_or_directory_path> .
# Upload file(s)
aws s3 sync . s3://<bucket_name>/<file_or_directory_path>
# Sync two buckets
aws s3 sync s3://<1st_s3_path> s3://<2nd_s3_path>
Также вы можете использовать --include "filename" много раз в одной команде, каждый раз включая имя файла в двойные кавычки, например
aws s3 mycommand --include "file1" --include "file2"
Это сэкономит ваше время, а не будет повторять команду для загрузки одного файла за раз.
В моем случае Aur не сработал, и если вы ищете быстрое решение для загрузки всех файлов в папке, просто используя браузер, вы можете попробовать ввести этот фрагмент в консоли разработчика:
(function() {
const rows = Array.from(document.querySelectorAll('.fix-width-table tbody tr'));
const downloadButton = document.querySelector('[data-e2e-id="button-download"]');
const timeBetweenClicks = 500;
function downloadFiles(remaining) {
if (!remaining.length) {
return
}
const row = remaining[0];
row.click();
downloadButton.click();
setTimeout(() => {
downloadFiles(remaining.slice(1));
}, timeBetweenClicks)
}
downloadFiles(rows)
}())
Я написал простой сценарий оболочки для загрузки НЕ ПРОСТО всех файлов, а также всех версий каждого файла из определенной папки в AWS s3 bucket. Вот оно, и вы можете найти это полезным
# Script generates the version info file for all the
# content under a particular bucket and then parses
# the file to grab the versionId for each of the versions
# and finally generates a fully qualified http url for
# the different versioned files and use that to download
# the content.
s3region="s3.ap-south-1.amazonaws.com"
bucket="your_bucket_name"
# note the location has no forward slash at beginning or at end
location="data/that/you/want/to/download"
# file names were like ABB-quarterly-results.csv, AVANTIFEED--quarterly-results.csv
fileNamePattern="-quarterly-results.csv"
# AWS CLI command to get version info
content="$(aws s3api list-object-versions --bucket $bucket --prefix "$location/")"
#save the file locally, if you want
echo "$content" >> version-info.json
versions=$(echo "$content" | grep -ir VersionId | awk -F ":" '{gsub(/"/, "", $3);gsub(/,/, "", $3);gsub(/ /, "", $3);print $3 }')
for version in $versions
do
echo ############### $fileId ###################
#echo $version
url="https://$s3region/$bucket/$location/$fileId$fileNamePattern?versionId=$version"
echo $url
content="$(curl -s "$url")"
echo "$content" >> $fileId$fileNamePattern-$version.csv
echo ############### $i ###################
done
Обычно я монтирую ведро s3 (с s3fs) на Linux-машине и заархивирую нужные мне файлы в один, а затем просто загружаю этот файл с любого компьютера / браузера.
# mount bucket in file system
/usr/bin/s3fs s3-bucket -o use_cache=/tmp -o allow_other -o uid=1000 -o mp_umask=002 -o multireq_max=5 /mnt/local-s3-bucket-mount
# zip files into one
cd /mnt/local-s3-bucket-mount
zip all-processed-files.zip *.jpg
Вы также можете использовать CyberDuck. Он хорошо работает с S3, и вы можете скачать папку.
Импорт ОС импорт Boto3 импорт JSON
s3 = boto3.resource('s3', aws_access_key_id="AKIAxxxxxxxxxxxxJWB", aws_secret_access_key="LV0+vsaxxxxxxxxxxxxxxxxxxxxxry0/LjxZkN") my_bucket = s3.Bucket('s3testing')
загрузить файл в текущий каталог
для s3_object в my_bucket.objects.all(): # Необходимо разделить s3_object.key на путь и имя файла, иначе это выдаст ошибку, файл не найден. путь, имя файла = os.path.split (s3_object.key) my_bucket.download_file (s3_object.key, имя файла)