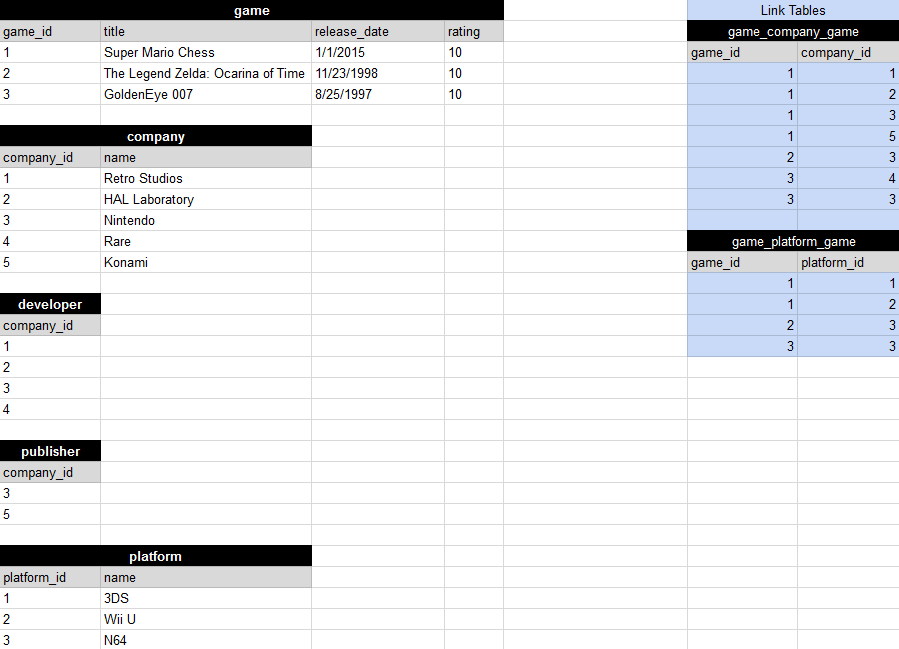
Элегантная нормализация без добавления полей, дополнительная таблица. Лучшие отношения
У меня есть 2 таблицы, которые я пытаюсь нормализовать. Проблема в том, что я не хочу создавать таблицу с новыми полями, хотя таблица ссылок, возможно, работает. Каков самый элегантный способ показать, что запись "Nintendo" ОБА издатель и разработчик? Я не хочу, чтобы "Nintendo" дублировалась. Я думаю, что отношения многие ко многим могут быть ключевыми здесь.
Я хочу подчеркнуть, что я абсолютно хочу, чтобы разработчик и издатель таблиц остались. Я не против создать связь между двумя новыми отношениями.
Вот две таблицы, которые я пытаюсь нормализовать:
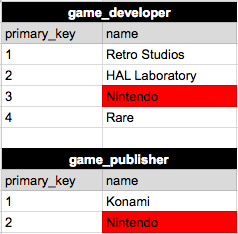
Ниже приведено решение, которое я попробовал (мне это не нравится):
4 ответа
Я думаю, что вы хотите что-то вроде этого:
Game_Company
ID Name
1 Retro Studios
2 HAL Laboratories
3 Nintendo
...
Company_Role
ID Name
1 Developer
2 Publisher
...
Game_Company_Role
CompanyID RoleID
1 1
2 1
3 1
3 2
...
To get a list of all companies that have role 'Developer':
SELECT gc.name
FROM Game_Company gc JOIN Game_Company_Role gcr ON gcr.CompanyID=gc.ID
WHERE gcr.RoleID = 1
В ваших двух столах нет ничего плохого.
На самом деле все, что вам нужно, это
developer(name) -- company [name] is a developer
publisher(name) -- company [name] is a publisher
Ваши изменения не имеют ничего общего с нормализацией. Нормализация никогда не создает новые имена столбцов. "Я не хочу, чтобы"Nintendo"дублировалась" - это неверное представление. Нет ничего плохого в том, что значения появляются в нескольких местах. Смотрите ответы sqlvogel & себя здесь.
НО: в зависимости от того, что означает, что строка находится в одной из ваших таблиц, может быть лучший способ уменьшить ошибки, потому что значения двух таблиц могут быть "ограничены", то есть зависеть друг от друга. Это как-то связано с "избыточностью", но касается ограничений и не предполагает нормализации. И для того, чтобы мы обратились к нему, вы должны точно указать нам, когда в каждую таблицу входит ряд, основанный на ситуации в мире.
Если вы не хотите повторять строки по причинам (зависящим от реализации) (занимаемое пространство или скорость операций за счет большего количества соединений), добавьте таблицу идентификаторов и строк имен (на самом деле идентификаторы и имена компаний) и замените ваши старые столбцы имен и значения по столбцам и значениям идентификатора компании. Но это не нормализация, это усложняет вашу схему ради компромиссов оптимизации данных, зависящих от реализации. (И вы должны продемонстрировать, что это необходимо и работает.)
Принятый ответ просто добавляет много лишних данных. Так же, как ваш вопрос добавляет три избыточных таблицы. В двух таблицах уже указано, какие компании являются разработчиками, а какие - издателями. Другие таблицы - это просто представления / запросы по двум!
Если вы хотите, чтобы новая таблица для "[id] идентифицировала компанию с именем [name] с помощью…", то это случай разработчиков и издателей как подтипов супертипной компании. Поиск по подтипам базы данных. Смотрите этот ответ. Тогда вы будете использовать идентификатор компании вместо имени, чтобы идентифицировать компании. Затем вы также можете еще больше упростить (!), Используя идентификатор компании в качестве единственного столбца в таблицах разработчика и издателя, а также везде, кроме developer_id и publisher_id.
"Избыточность" не относится к значениям, появляющимся в нескольких местах. Речь идет о нескольких строках, заявляющих одно и то же о приложении. При использовании такого дизайна есть две основные проблемы: сказать, что некоторые вещи задействованы в нескольких строках (в то время как нормализованная версия включает только одну строку); и нет никакого способа сказать только одну вещь за один раз (с которой нормализация может помочь с). Если вы сделаете два разных независимых заявления о Nintendo, то вам понадобятся две таблицы и Nintendo, упомянутые в каждой. Re строки, делающие заявления о приложении, видят это. (Ищите мои другие ответы по "утверждению" или критерию таблицы.) Нормализация помогает, потому что она заменяет таблицы, в строках которых указано состояние вида "... И...", другими таблицами, в которых указано "..." отдельно. См. это и это. (Обычно считается, что нормализация ошибочно включает или избегает использования нескольких похожих столбцов, избегая столбцов, значения которых имеют повторяющуюся структуру, и / или заменяя строки на идентификаторы, но хотя они могут быть хорошими идеями проектирования, они не являются нормализацией.)
В комментариях, чате и другом ответе вы дали такую отправную точку:

Вот самый простой дизайн. (Я предполагаю, что названия игр не уникальны, поэтому вам нужны game_ids.)
-- game [game_id] with title [title] released on [release_date] is rated [rating]
game(game_id,title,release_date,rating)
game_developer(game_id,name) -- game [game_id] is developed by company [name]
game_publisher(game_id,name) -- game [game_id] is published by company [name]
game_platform(game_id,name) -- game [game_id] is on platform [name]
Только если вам нужен отдельный список компаний, чтобы компания могла существовать без разработки или публикации и / или иметь свои собственные данные, вам нужно добавить:
company(name,...) -- [name] identifies a company
Только если вам нужны специфичные для роли данные для разработчиков и издателей, вам нужно добавить:
developer(name,...) -- developer [name] has ...
publisher(name,...) -- publisher [name] has ...
Соответствующие внешние ключи различных опций являются прямыми.
Ни одна из ваших версий не нужна _ids. Ваши версии 2 и 3 не будут работать, потому что они не говорят, какие компании разрабатывают игру или какие компании публикуют игру. Вам не нужны роли, но если они у вас есть (версия 2), то вам нужна таблица "game [game_id] имеет company [name] в качестве [role]". В противном случае (версия 3) вам понадобятся таблицы для "[game_id] разработан компанией [name]" и "game [game_id] опубликован компанией [name]". Где бы вы ни отличались от моих проектов, спросите себя, почему у вас есть дополнительная структура и почему вы можете обойтись без нее и (возможно), почему вы в любом случае явно хотите ее.
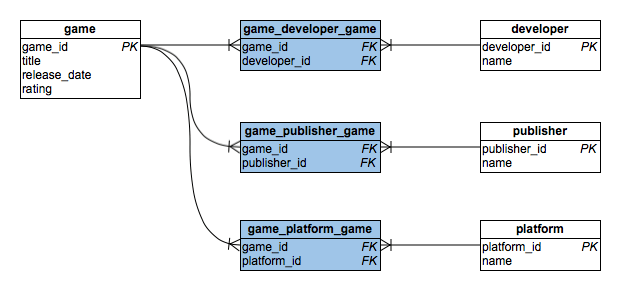
Это немного общий подход к проблеме, он может представлять интерес. Как отметил @Dour High Arch в своем решении, разработчик и издатель - всего лишь роли для "вечеринки". Каждая часть имеет 0,1 или более ролей с данным продуктом, и роли могут перекрываться. Это хорошо и плохо. Например, продукт может быть разработан 5 разработчиками, но опубликован не более чем одним издателем. Я решил ввести serial_id в качестве PK, сгенерированного системой, но это не обязательно. Вы можете использовать 3FK как PK, а не использовать serial_id.
Обратите внимание, что наличие партии в качестве обобщения различных типов сущностей не всегда хорошо, поскольку для одного или нескольких столбцов должно быть установлено, что они не обязательны, если это не является общим для всех сторон, однако, это очень распространено в реальных приложениях.
Конвенция:
name_PK = первичный ключ,
name_FK = внешний ключ

Вот три окончательных решения, предложенные в комментариях. Вы можете видеть, что таблица разбита сверху "ненормализованной" таблицы.
Правила следующие:
- 1 игра может иметь 1 или много разработчиков, а 1 разработчик может иметь 1 или много игр.
- 1 игра может иметь 1 или несколько издателей, а 1 издатель может иметь 1 или несколько игр.
- 1 игра может иметь 1 или несколько платформ, а 1 платформа может иметь 1 или несколько игр.
Версия 1
Я оставил 2 записи "Nintendo" красным. Согласно исследованиям и реализации, это не технически избыточные данные. Смотрите мои комментарии под ответом Филиппа. Это выглядит просто и элегантно. 4 таблицы с отношением многие ко многим.
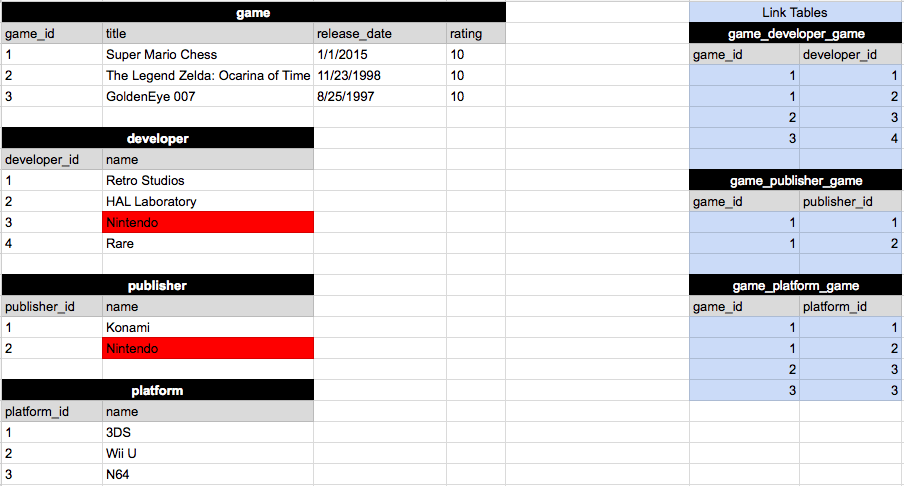
Вот диаграмма отношений (4 таблицы и 3 таблицы ссылок):
Verison 2
Версия 1 "повторяет" "Nintendo", но версия 2 имеет таблицу "Компания". Сравните 2 разные версии. Какой правильный путь?
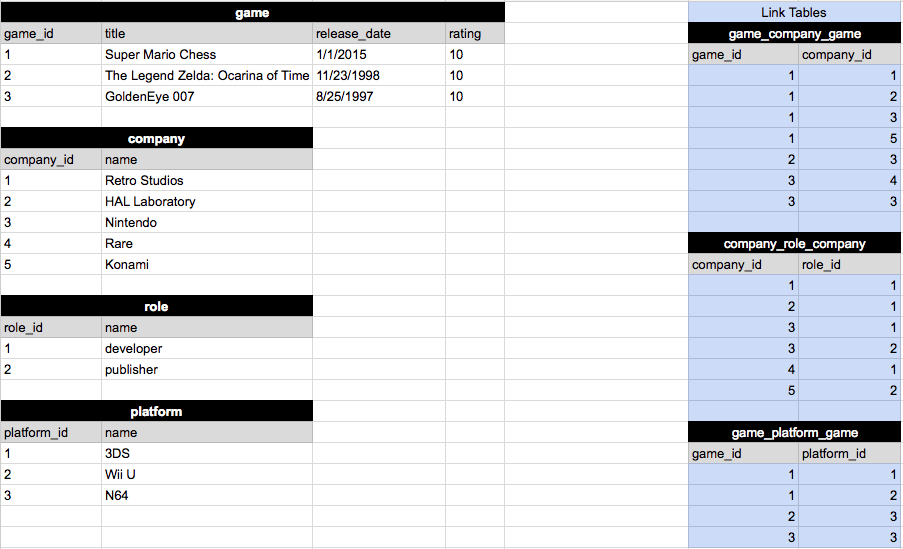
Версия 3
Вот о чем говорил филиппийский подтип. Как эта версия?