Google Colab Laboratory "ResourceExhaustedError" с графическим процессором
Я пытаюсь подстроить Vgg16 модель с использованием colaboratory но я столкнулся с этой ошибкой при тренировках с GPU.
OOM when allocating tensor of shape [7,7,512,4096]
INFO:tensorflow:Error reported to Coordinator: <class 'tensorflow.python.framework.errors_impl.ResourceExhaustedError'>, OOM when allocating tensor of shape [7,7,512,4096] and type float
[[Node: vgg_16/fc6/weights/Momentum/Initializer/zeros = Const[_class=["loc:@vgg_16/fc6/weights"], dtype=DT_FLOAT, value=Tensor<type: float shape: [7,7,512,4096] values: [[[0 0 0]]]...>, _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]]
Caused by op 'vgg_16/fc6/weights/Momentum/Initializer/zeros', defined at:
также есть этот вывод для моей сессии VM:
--- colab vm info ---
python v=3.6.3
tensorflow v=1.4.1
tf device=/device:GPU:0
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
MemTotal: 13341960 kB
MemFree: 1541740 kB
MemAvailable: 10035212 kB
мой tfrecord всего 118 256x256 JPG с file size <2MB
Есть ли обходной путь? он работает, когда я использую процессор, но не графический процессор
4 ответа
Мне не удалось воспроизвести первоначально сообщенную ошибку, но если это вызвано нехваткой памяти графического процессора (в отличие от основной памяти), это может помочь:
# See https://www.tensorflow.org/tutorials/using_gpu#allowing_gpu_memory_growth
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
а затем пройти session_config=config например slim.learning.train() (или любой другой сеансовый ctor, который вы используете).
Небольшое количество свободной памяти GPU почти всегда означает, что вы создали сеанс TensorFlow без allow_growth = True вариант. Смотрите: https://www.tensorflow.org/guide/using_gpu
Если вы не установите эту опцию, по умолчанию TensorFlow зарезервирует почти всю память GPU при создании сеанса.
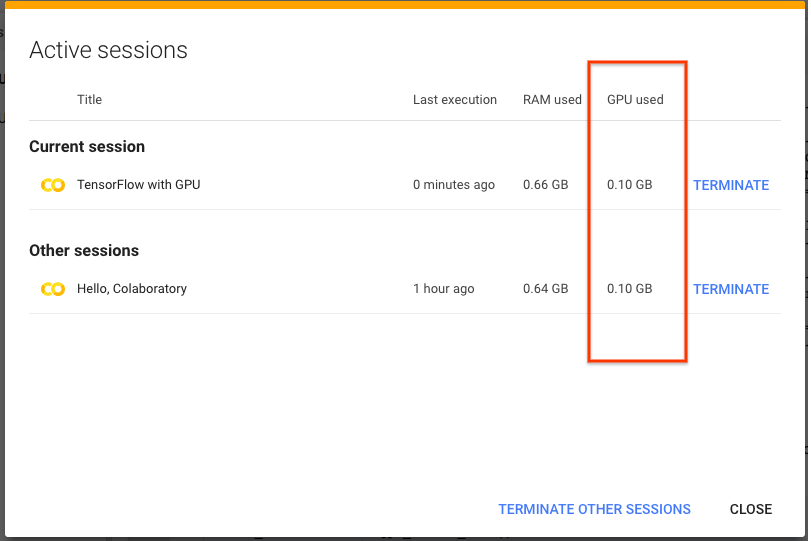
Хорошие новости: На этой неделе Colab теперь устанавливает эту опцию по умолчанию, так что при использовании нескольких ноутбуков в Colab вы должны увидеть гораздо меньший рост. Кроме того, вы также можете проверить использование памяти графическим процессором для каждого ноутбука, выбрав "Управление сессиями" в меню времени выполнения.
После выбора вы увидите диалоговое окно, в котором перечислены все ноутбуки и память, которую каждый из них использует. Чтобы освободить память, вы также можете прекратить время выполнения из этого диалога.
Я столкнулся с той же проблемой, и я обнаружил, что моя проблема была вызвана кодом ниже:
from tensorflow.python.framework.test_util import is_gpu_available as tf
if tf()==True:
device='/gpu:0'
else:
device='/cpu:0'
Я использовал приведенный ниже код для проверки состояния использования памяти графическим процессором и обнаружил, что использование составляет 0% перед запуском приведенного выше кода, а после стало 95%.
# memory footprint support libraries/code
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install gputil
!pip install psutil
!pip install humanize
import psutil
import humanize
import os
import GPUtil as GPU
GPUs = GPU.getGPUs()
# XXX: only one GPU on Colab and isn't guaranteed
gpu = GPUs[0]
def printm():
process = psutil.Process(os.getpid())
print("Gen RAM Free: " + humanize.naturalsize( psutil.virtual_memory().available ), " I Proc size: " + humanize.naturalsize( process.memory_info().rss))
print('GPU RAM Free: {0:.0f}MB | Used: {1:.0f}MB | Util {2:3.0f}% | Total {3:.0f}MB'.format(gpu.memoryFree, gpu.memoryUsed, gpu.memoryUtil*100, gpu.memoryTotal))
printm()
До:
Оперативная память: 12,7 ГБ, объем памяти: 139,1 МБ.
ОЗУ графического процессора: 11438 МБ | Используется: 1MB | Util 0% | Всего 11439 МБ
После:
Оперативная память: 12,0 ГБ, объем памяти: 1,0 ГБ.
ОЗУ графического процессора: 564 МБ | Используется: 10875MB | Использовать 95% | Всего 11439 МБ
Каким-то образом is_gpu_available() удалось потреблять большую часть памяти GPU без освобождения их после, поэтому вместо этого я использовал приведенный ниже код для определения состояния GPU для меня, проблема решена
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install gputil
try:
import GPUtil as GPU
GPUs = GPU.getGPUs()
device='/gpu:0'
except:
device='/cpu:0'
В моем случае я не решил с помощью решения, предоставленного Ami, даже если оно превосходное, вероятно, потому что Colab Laboratory VM не мог предоставить больше ресурсов.
У меня была ошибка OOM в фазе обнаружения (не обучение модели). Я решил с помощью обходного пути, отключив графический процессор для обнаружения:
config = tf.ConfigProto(device_count = {'GPU': 0})
sess = tf.Session(config=config)