Спекулятивное исполнение Mapreduce/Spark
Я знаю, что Hadoop/Spark Framework будет обнаруживать неисправные или медленные машины и выполнять одинаковые задачи на разных машинах. Как будет (на каком основании) фреймворк идентифицировать медленно работающие машины. Есть ли какая-либо статистика для решения рамок?
Может ли кто-нибудь пролить свет здесь?
2 ответа
Модель MapReduce состоит в том, чтобы разбивать задания на задачи и запускать их параллельно, чтобы общее время выполнения задания было меньше, чем было бы, если бы задачи выполнялись последовательно.
yarn.app.mapreduce.am.job.task.estimator.class- Когда модель MapReduce запускает новое задание, это свойство и реализация используются для оценки времени выполнения задачи во время выполнения. Расчетное время выполнения задачи должно быть меньше минуты. Если задача выполняется дольше указанного времени, она может быть помечена как медленная.
yarn.app.mapreduce.am.job.speculator.class - Это свойство используется для реализации политики спекулятивного исполнения.
Значение по умолчанию Spark.speculation - false. Если установлено значение "true", выполняется спекулятивное выполнение задач. Это означает, что если одна или несколько задач на этапе выполняются медленно, они будут перезапущены.
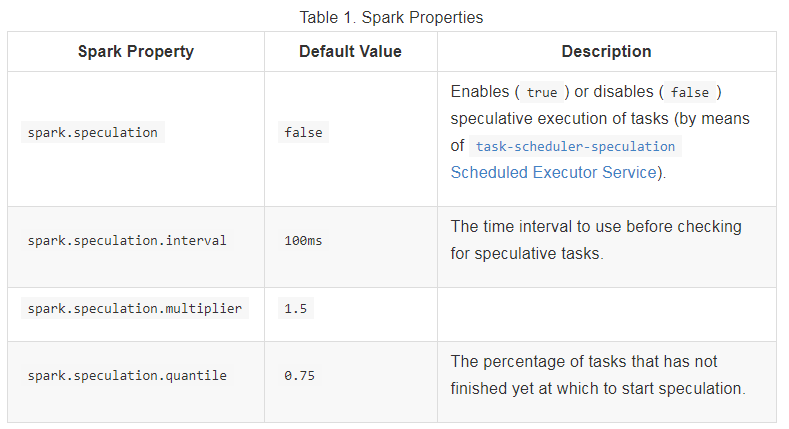
http://spark.apache.org/docs/latest/configuration.html
Вы можете добавить эти флаги в ваш spark-submit, передав их в --conf, например:
spark-submit \
--conf "spark.speculation=true" \
--conf "spark.speculation.multiplier=5" \
--conf "spark.speculation.quantile=0.90" \
--class "org.asyncified.myClass" "path/to/Vaquarkhanjar.jar"
Примечание. Драйвер Spark тратит много времени на размышления при управлении большим количеством задач. включите его только при необходимости.