Pytorch, каковы градиентные аргументы
Я читаю документацию PyTorch и нашел пример, где они пишут
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
print(x.grad)
где x была исходной переменной, из которой был построен y (3-вектор). Вопрос в том, каковы аргументы тензора градиентов 0,1, 1,0 и 0,0001? Документация не очень ясно об этом.
3 ответа
объяснение
Для нейронных сетей мы обычно используем loss оценить, насколько хорошо сеть научилась классифицировать входное изображение (или другие задачи). loss Термин обычно является скалярным значением. Для того чтобы обновить параметры сети, нам нужно рассчитать градиент loss по параметрам, что на самом деле leaf node в графе вычислений (кстати, эти параметры в основном представляют собой вес и смещение различных слоев, таких как Convolution, Linear и так далее).
Согласно правилу цепочки, для расчета градиента loss по отношению к конечному узлу мы можем вычислить производную loss по некоторой промежуточной переменной и градиенту промежуточной переменной по отношению к листовой переменной, получим скалярное произведение и суммируем все это.
gradient аргументы Variable "s backward() Метод используется для вычисления взвешенной суммы каждого элемента переменной по отношению к листовой переменной. Эти веса просто производная от финала loss по каждому элементу промежуточной переменной.
Конкретный пример
Давайте рассмотрим конкретный и простой пример, чтобы понять это.
from torch.autograd import Variable
import torch
x = Variable(torch.FloatTensor([[1, 2, 3, 4]]), requires_grad=True)
z = 2*x
loss = z.sum(dim=1)
# do backward for first element of z
z.backward(torch.FloatTensor([[1, 0, 0, 0]]))
print(x.grad.data)
x.grad.data.zero_() #remove gradient in x.grad, or it will be accumulated
# do backward for second element of z
z.backward(torch.FloatTensor([[0, 1, 0, 0]]))
print(x.grad.data)
x.grad.data.zero_()
# do backward for all elements of z, with weight equal to the derivative of
# loss w.r.t z_1, z_2, z_3 and z_4
z.backward(torch.FloatTensor([[1, 1, 1, 1]]))
print(x.grad.data)
x.grad.data.zero_()
# or we can directly backprop using loss
loss.backward() # equivalent to loss.backward(torch.FloatTensor([1.0]))
print(x.grad.data)
В приведенном выше примере, результат первого print является
2 0 0 0
[torch.FloatTensor размером 1x4]
которая является точно производной от z_1 по x.
Исход второй print является:
0 2 0 0
[torch.FloatTensor размером 1x4]
которая является производной от z_2 по x.
Теперь, если использовать вес [1, 1, 1, 1] для вычисления производной z по x, результат будет 1*dz_1/dx + 1*dz_2/dx + 1*dz_3/dx + 1*dz_4/dx, Поэтому неудивительно, что выход 3-го print является:
2 2 2 2
[torch.FloatTensor размером 1x4]
Следует отметить, что вектор весов [1, 1, 1, 1] точно является производной от loss по отношению к z_1, z_2, z_3 и z_4. Производная от loss по отношению к x рассчитывается как:
d(loss)/dx = d(loss)/dz_1 * dz_1/dx + d(loss)/dz_2 * dz_2/dx + d(loss)/dz_3 * dz_3/dx + d(loss)/dz_4 * dz_4/dx
Итак, выход 4-й print такой же, как 3-й print:
2 2 2 2
[torch.FloatTensor размером 1x4]
Как правило, ваш вычислительный граф имеет один скалярный вывод: loss, Тогда вы можете вычислить градиент loss по весам (w) от loss.backward(), Где аргумент по умолчанию backward() является 1.0,
Если ваш вывод имеет несколько значений (например, loss=[loss1, loss2, loss3]), вы можете вычислить градиенты потерь по весам loss.backward(torch.FloatTensor([1.0, 1.0, 1.0])),
Кроме того, если вы хотите добавить веса или значения к различным потерям, вы можете использовать loss.backward(torch.FloatTensor([-0.1, 1.0, 0.0001])),
Это значит рассчитать -0.1*d(loss1)/dw, d(loss2)/dw, 0.0001*d(loss3)/dw одновременно.
Здесь выходные данные forward(), т. Е. Y, представляют собой 3-вектор.
Три значения являются градиентами на выходе сети. Обычно они устанавливаются на 1,0, если y является конечным выходом, но могут иметь и другие значения, особенно если y является частью более крупной сети.
Например, если x является входом, y = [y1, y2, y3] является промежуточным выходом, который используется для вычисления конечного выхода z,
Затем,
dz/dx = dz/dy1 * dy1/dx + dz/dy2 * dy2/dx + dz/dy3 * dy3/dx
Итак, здесь три значения назад
[dz/dy1, dz/dy2, dz/dy3]
а затем backward() вычисляет dz/dx
Исходный код я больше не нашел на сайте PyTorch.
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
print(x.grad)
Проблема с приведенным выше кодом: нет функции, основанной на том, что вычислять градиенты. Это означает, что мы не знаем, сколько параметров (аргументов принимает функция) и размерность параметров.
Чтобы полностью понять это, я создал пример, близкий к оригиналу:
Пример 1:
a = torch.tensor([1.0, 2.0, 3.0], requires_grad = True)
b = torch.tensor([3.0, 4.0, 5.0], requires_grad = True)
c = torch.tensor([6.0, 7.0, 8.0], requires_grad = True)
y=3*a + 2*b*b + torch.log(c)
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients,retain_graph=True)
print(a.grad) # tensor([3.0000e-01, 3.0000e+00, 3.0000e-04])
print(b.grad) # tensor([1.2000e+00, 1.6000e+01, 2.0000e-03])
print(c.grad) # tensor([1.6667e-02, 1.4286e-01, 1.2500e-05])
Я предположил, что наша функция y=3*a + 2*b*b + torch.log(c) а параметры - тензоры с тремя элементами внутри.
Вы можете думать о gradients = torch.FloatTensor([0.1, 1.0, 0.0001]) вроде это аккумулятор.
Как вы, наверное, слышали, расчет системы автограда PyTorch эквивалентен произведению Якоби.
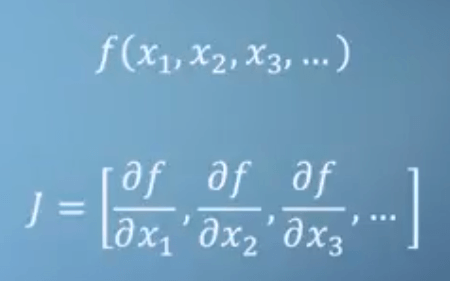
Если у вас есть функция, как у нас:
y=3*a + 2*b*b + torch.log(c)
Якобианец был бы [3, 4*b, 1/c]. Однако этот якобиан - это не то, как PyTorch вычисляет градиенты в определенной точке.
PyTorch использует в тандеме прямое и обратное автоматическое распознавание (AD).
Здесь нет символической математики и числового дифференцирования.
Численное дифференцирование было бы для вычисления
δy/δb, заb=1а такжеb=1+εгде ε мало.
Если вы не используете градиенты в y.backward():
Пример 2
a = torch.tensor(0.1, requires_grad = True)
b = torch.tensor(1.0, requires_grad = True)
c = torch.tensor(0.1, requires_grad = True)
y=3*a + 2*b*b + torch.log(c)
y.backward()
print(a.grad) # tensor(3.)
print(b.grad) # tensor(4.)
print(c.grad) # tensor(10.)
Вы просто получите результат в определенный момент, в зависимости от того, как вы установите a, b, c тензоры изначально.
Будьте осторожны при инициализации своего a, b, c:
Пример 3:
a = torch.empty(1, requires_grad = True, pin_memory=True)
b = torch.empty(1, requires_grad = True, pin_memory=True)
c = torch.empty(1, requires_grad = True, pin_memory=True)
y=3*a + 2*b*b + torch.log(c)
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
print(a.grad) # tensor([3.3003])
print(b.grad) # tensor([0.])
print(c.grad) # tensor([inf])
Если вы используете torch.empty() и не используйте pin_memory=True у вас могут быть разные результаты каждый раз.
Кроме того, градиенты нот похожи на аккумуляторы, поэтому при необходимости обнуляйте их.
Пример 4:
a = torch.tensor(1.0, requires_grad = True)
b = torch.tensor(1.0, requires_grad = True)
c = torch.tensor(1.0, requires_grad = True)
y=3*a + 2*b*b + torch.log(c)
y.backward(retain_graph=True)
y.backward()
print(a.grad) # tensor(6.)
print(b.grad) # tensor(8.)
print(c.grad) # tensor(2.)
И напоследок несколько советов по терминам, которые использует PyTorch:
PyTorch создает динамический вычислительный граф при вычислении градиентов в прямом проходе. Это очень похоже на дерево.
Поэтому вы часто слышите, что листья этого дерева являются входными тензорами, а корень - выходными тензорами.
Градиенты вычисляются путем отслеживания графика от корня к листу и умножения каждого градиента способом с использованием правила цепочки. Это умножение происходит при обратном проходе.