Совпадение чисел с регулярными выражениями - только цифры и запятые
Я не могу понять, как построить регулярное выражение для значений примера:
123,456,789
-12,34
1234
-8
Не могли бы вы помочь мне?
10 ответов
Если вы хотите разрешить только цифры и запятые, ^[-,0-9]+$ это ваше регулярное выражение Если вы также хотите разрешить пробелы, используйте ^[-,0-9 ]+$,
Однако, если вы хотите разрешить правильные числа, лучше используйте что-то вроде этого:
^([-+] ?)?[0-9]+(,[0-9]+)?$
или просто используйте анализатор номеров.net (для различных NumberStyles см. MSDN):
try {
double.Parse(yourString, NumberStyle.Number);
}
catch(FormatException ex) {
/* Number is not in an accepted format */
}
Какой номер?
У меня простой вопрос к вашему "простому" вопросу: что именно вы подразумеваете под "числом"?
- Является
−0число? - Как вы относитесь к
√−1? - Является
⅝или же⅔число? - Является
186,282.42±0.02миль / секунду одно число - или это два или три из них? - Является
6.02e23число? - Является
3.141_592_653_589число? Как насчетπ, или жеℯ? А также−2π⁻³ ͥ? - Сколько номеров в
0.083̄? - Сколько номеров в
128.0.0.1? - Какой номер делает
⚄держать? Как насчет⚂⚃? - Есть ли
10,5 mmесть один номер - или два? - Является
∛8³число - или это три из них? - Какой номер делает
ↀↀⅮⅭⅭⅬⅫ AUCпредставляете, 2762 или 2009? - Являются
४५६७а также৭৮৯৮номера? - Как насчет
0377,0xDEADBEEF, а также0b111101101? - Является
Infчисло? ЯвляетсяNaN? - Является
④②число? Как насчет⓰? - Как вы относитесь к
㊅? - Что
ℵ₀а такжеℵ₁связано с числами? Или жеℝ,ℚ, а такжеℂ?
Предлагаемые шаблоны
Кроме того, вы знакомы с этими моделями? Можете ли вы объяснить плюсы и минусы каждого?
/\D//^\d+$//^\p{Nd}+$//^\pN+$//^\p{Numeric_Value:10}$//^\P{Numeric_Value:NaN}+$//^-?\d+$//^[+-]?\d+$//^-?\d+\.?\d*$//^-?(?:\d+(?:\.\d*)?|\.\d+)$//^([+-]?)(?=\d|\.\d)\d*(\.\d*)?([Ee]([+-]?\d+))?$//^((\d)(?(?=(\d))|$)(?(?{ord$3==1+ord$2})(?1)|$))$//^(?:(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2}))$//^(?:(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}))$//^(?:(?:[+-]?)(?:[0123456789]+))$//(([+-]?)([0123456789]{1,3}(?:,?[0123456789]{3})*))//^(?:(?:[+-]?)(?:[0123456789]{1,3}(?:,?[0123456789]{3})*))$//^(?:(?i)(?:[+-]?)(?:(?=[0123456789]|[.])(?:[0123456789]*)(?:(?:[.])(?:[0123456789]{0,}))?)(?:(?:[E])(?:(?:[+-]?)(?:[0123456789]+))|))$//^(?:(?i)(?:[+-]?)(?:(?=[01]|[.])(?:[01]{1,3}(?:(?:[,])[01]{3})*)(?:(?:[.])(?:[01]{0,}))?)(?:(?:[E])(?:(?:[+-]?)(?:[01]+))|))$//^(?:(?i)(?:[+-]?)(?:(?=[0123456789ABCDEF]|[.])(?:[0123456789ABCDEF]{1,3}(?:(?:[,])[0123456789ABCDEF]{3})*)(?:(?:[.])(?:[0123456789ABCDEF]{0,}))?)(?:(?:[G])(?:(?:[+-]?)(?:[0123456789ABCDEF]+))|))$//((?i)([+-]?)((?=[0123456789]|[.])([0123456789]{1,3}(?:(?:[_,]?)[0123456789]{3})*)(?:([.])([0123456789]{0,}))?)(?:([E])(([+-]?)([0123456789]+))|))/
Я подозреваю, что некоторые из приведенных выше шаблонов могут удовлетворить ваши потребности. Но я не могу сказать вам, какой из них или один, или, если нет, предоставит вам другой - потому что вы не сказали, что вы подразумеваете под "числом".
Как видите, существует огромное количество возможностей чисел: вполне вероятно, что на самом деле их стоит. ☺
Ключ к предложенным шаблонам
Каждое нумерованное объяснение, указанное ниже, описывает шаблон соответствующего нумерованного шаблона, указанного выше.
- Соответствует, если в строке есть какие-либо нецифровые символы, включая пробелы, такие как разрывы строк.
- Соответствует только в том случае, если строка не содержит ничего, кроме цифр, с возможным исключением разрыва строки в конце. Обратите внимание, что цифра определяется как имеющая свойство Общая категория Десятичное число, которое доступно как
\p{Nd},\p{Decimal_Number}, или же\p{General_Category=Decimal_Number}, Этот поворот на самом деле является просто отражением тех кодовых точек, чья категория числового типа является десятичной, которая доступна как\p{Numeric_Type=Decimal}, - Это то же самое, что 2 в большинстве языков регулярных выражений. Java здесь исключение, потому что она не отображает простые экранированные символы, такие как
\wа также\W,\dа также\D,\sа также\S, а также\bили же\Bв соответствующее свойство Unicode. Это означает, что вы не должны использовать ни один из этих восьми односимвольных escape-символов для любых данных Unicode в Java, потому что они работают только на ASCII, даже если Java всегда использует символы Unicode для внутреннего использования. - Это немного отличается от 3 тем, что оно не ограничено десятичными числами, но может быть любым числом; то есть любой персонаж с
\pN,\p{Number}, или же\p{General_Category=Number}имущество. Они включают\p{Nl}или же\p{Letter_Number}для таких вещей, как римские цифры и\p{No}или же\p{Other_Number}для подписанных и подписанных чисел, дробей и чисел в кружках - среди прочего, таких как счетные стержни. - Это соответствует только тем строкам, которые целиком состоят из чисел, десятичное значение которых равно 10, поэтому
Ⅹримская цифра десять, и⑩,⑽,⒑,⓾,❿,➉, а также➓, - Только те строки, которые содержат символы, в которых отсутствует числовое значение NaN; другими словами, все символы должны иметь некоторое числовое значение.
- Соответствует только десятичным числам, опционально с лидирующим ГИФЕНСКИМ МИНУСОМ.
- То же, что 7, но теперь также работает, если знак плюс, а не минус.
- Ищет десятичные числа, с дополнительным HYPHEN MINUS и дополнительным FULL STOP плюс ноль или более десятичных чисел после.
- То же, что 9, но не требует цифр перед точкой, если она есть после.
- Стандартные обозначения с плавающей точкой для C и многих других языков, допускающие научное обозначение.
- Находит числа, состоящие только из двух или более десятичных знаков любого сценария в порядке убывания, например, 987 или 54321. Это рекурсивное регулярное выражение включает в себя обратный вызов в код Perl, который проверяет, имеет ли цифра прогнозного значения значение кодовой точки, являющееся преемником текущей цифры; то есть его порядковая стоимость на единицу больше. Это можно сделать в PCRE, используя функцию C в качестве выноски.
- При этом выполняется поиск действительного адреса IPv4 с четырьмя десятичными числами в допустимом диапазоне, например 128.0.0.1 или 255.255.255.240, но не 999.999.999.999.
- При этом ищется действительный MAC-адрес, поэтому шесть двоеточия разделяют две пары шестнадцатеричных цифр ASCII.
- Это ищет целые числа в диапазоне ASCII с необязательным начальным знаком. Это нормальный шаблон для сопоставления целых чисел ASCII.
- Это как 15, за исключением того, что для разделения групп по три требуется запятая.
- Это похоже на 15, за исключением того, что запятая для разделения групп теперь является необязательной.
- Это нормальный шаблон для сопоставления чисел с плавающей точкой в стиле C в ASCII.
- Это как 18, но требуется запятая для разделения групп из 3 и в базе-2, а не в базе-10.
- Это как 19, но в гексе. Обратите внимание, что необязательный показатель степени теперь обозначается как G вместо E, так как E является действительной шестнадцатеричной цифрой.
- Это проверяет, что строка содержит число с плавающей точкой в стиле C, но с необязательным разделителем группировки через каждые три цифры запятой или подчеркивания (LOW LINE) между ними. Он также сохраняет эту строку в
\1захватить группу, сделав доступной как$1после того, как матч удастся.
Источники и ремонтопригодность
Образцы с номерами 1,2,7–11 взяты из предыдущего воплощения списка часто задаваемых вопросов Perl в вопросе "Как проверить ввод?". Этот раздел был заменен предложением использовать модуль Regexp:: Common, написанный Абигейл и Дамианом Конвеем. Оригинальные шаблоны по-прежнему можно найти в рецепте 2.1 поваренной книги Perl"Проверка, является ли строка действительным числом", решения которой можно найти для головокружительного числа различных языков, включая ada, common lisp, groovy, guile, haskell, java, merd, ocaml, php, pike, python, rexx, ruby и tcl в проекте PLEAC.
Шаблон 12 может быть более разборчиво переписан
m{
^
(
( \d )
(?(?= ( \d ) ) | $ )
(?(?{ ord $3 == 1 + ord $2 }) (?1) | $ )
)
$
}x
Он использует рекурсию regex, которая встречается во многих движках шаблонов, включая Perl и все языки, основанные на PCRE. Но он также использует встроенный код для проверки своего второго условного шаблона; насколько мне известно, кодовые выноски доступны только в Perl и PCRE.
Шаблоны 13–21 были получены из вышеупомянутого модуля Regexp:: Common. Обратите внимание, что для краткости все они написаны без пробелов и комментариев, которые вы определенно захотите в производственном коде. Вот как это может выглядеть в /x Режим:
$real_rx = qr{ ( # start $1 to hold entire pattern
( [+-]? ) # optional leading sign, captured into $2
( # start $3
(?= # look ahead for what next char *will* be
[0123456789] # EITHER: an ASCII digit
| [.] # OR ELSE: a dot
) # end look ahead
( # start $4
[0123456789]{1,3} # 1-3 ASCII digits to start the number
(?: # then optionally followed by
(?: [_,]? ) # an optional grouping separator of comma or underscore
[0123456789]{3} # followed by exactly three ASCII digits
) * # repeated any number of times
) # end $4
(?: # begin optional cluster
( [.] ) # required literal dot in $5
( [0123456789]{0,} ) # then optional ASCII digits in $6
) ? # end optional cluster
) # end $3
(?: # begin cluster group
( [E] ) # base-10 exponent into $7
( # exponent number into $8
( [+-] ? ) # optional sign for exponent into $9
( [0123456789] + ) # one or more ASCII digits into $10
) # end $8
| # or else nothing at all
) # end cluster group
) }xi; # end $1 and whole pattern, enabling /x and /i modes
С точки зрения разработки программного обеспечения, все еще есть несколько проблем со стилем, используемым в /x Версия режима сразу выше. Во-первых, есть много повторений кода, где вы видите то же самое [0123456789]; что произойдет, если одна из этих последовательностей случайно пропустит цифру? Во-вторых, вы полагаетесь на позиционные параметры, которые вы должны учитывать. Это означает, что вы можете написать что-то вроде:
(
$real_number, # $1
$real_number_sign, # $2
$pre_exponent_part, # $3
$pre_decimal_point, # $4
$decimal_point, # $5
$post_decimal_point, # $6
$exponent_indicator, # $7
$exponent_number, # $8
$exponent_sign, # $9
$exponent_digits, # $10
) = ($string =~ /$real_rx/);
что откровенно отвратительно! Легко ошибиться в нумерации, трудно вспомнить, куда идут символические имена, и писать утомительно, особенно если вам не нужны все эти фрагменты. Переписав это, чтобы использовать именованные группы вместо просто пронумерованных. Опять же, я буду использовать синтаксис Perl для переменных, но содержимое шаблона должно работать везде, где поддерживаются именованные группы.
use 5.010; # Perl got named patterns in 5.10
$real_rx = qr{
(?<real_number>
# optional leading sign
(?<real_number_sign> [+-]? )
(?<pre_exponent_part>
(?= # look ahead for what next char *will* be
[0123456789] # EITHER: an ASCII digit
| [.] # OR ELSE: a dot
) # end look ahead
(?<pre_decimal_point>
[0123456789]{1,3} # 1-3 ASCII digits to start the number
(?: # then optionally followed by
(?: [_,]? ) # an optional grouping separator of comma or underscore
[0123456789]{3} # followed by exactly three ASCII digits
) * # repeated any number of times
) # end <pre_decimal_part>
(?: # begin optional anon cluster
(?<decimal_point> [.] ) # required literal dot
(?<post_decimal_point>
[0123456789]{0,} )
) ? # end optional anon cluster
) # end <pre_exponent_part>
# begin anon cluster group:
(?:
(?<exponent_indicator> [E] ) # base-10 exponent
(?<exponent_number> # exponent number
(?<exponent_sign> [+-] ? )
(?<exponent_digits> [0123456789] + )
) # end <exponent_number>
| # or else nothing at all
) # end anon cluster group
) # end <real_number>
}xi;
Теперь названы абстракции, что помогает. Вы можете вывести группы по именам, и вам нужны только те, которые вам небезразличны. Например:
if ($string =~ /$real_rx/) {
($pre_exponent, $exponent_number) =
@+{ qw< pre_exponent exponent_number > };
}
Есть еще одна вещь, чтобы сделать этот шаблон, чтобы сделать его еще более ремонтопригодным. Проблема в том, что все еще слишком много повторений, что означает, что его слишком легко изменить в одном месте, но не в другом. Если бы вы проводили анализ МакКейба, вы бы сказали, что его показатель сложности слишком высок. Большинство из нас просто сказали бы, что это слишком отступ. Это мешает следовать. Чтобы исправить все эти вещи, нам нужен "грамматический шаблон", в котором есть блок определения для создания именованных абстракций, который мы затем воспринимаем как вызов подпрограммы позже в матче.
use 5.010; # Perl first got regex subs in v5.10
$real__rx = qr{
^ # anchor to front
(?&real_number) # call &real_number regex sub
$ # either at end or before final newline
##################################################
# the rest is definition only; think of ##
# each named buffer as declaring a subroutine ##
# by that name ##
##################################################
(?(DEFINE)
(?<real_number>
(?&mantissa)
(?&abscissa) ?
)
(?<abscissa>
(?&exponent_indicator)
(?&exponent)
)
(?<exponent>
(&?sign) ?
(?&a_digit) +
)
(?<mantissa>
# expecting either of these....
(?= (?&a_digit)
| (?&point)
)
(?&a_digit) {1,3}
(?: (?&digit_separator) ?
(?&a_digit) {3}
) *
(?: (?&point)
(?&a_digit) *
) ?
)
(?<point> [.] )
(?<sign> [+-] )
(?<digit_separator> [_,] )
(?<exponent_indicator> [Ee] )
(?<a_digit> [0-9] )
) # end DEFINE block
}x;
Видите, насколько безумно лучше грамматическая схема, чем оригинальная линия с шумом? Также намного проще получить правильный синтаксис: я набрал его без единой синтаксической ошибки регулярного выражения, которую нужно было исправить. (Хорошо, я набрал все остальные без синтаксических ошибок, но я делал это некоторое время.:)
Грамматические паттерны больше похожи на БНФ, чем на старые уродливые регулярные выражения, которые люди ненавидят. Их гораздо проще читать, писать и поддерживать. Итак, давайте не будем больше отвратительных моделей, хорошо?
Попробуй это:
^-?\d{1,3}(,\d{3})*(\.\d\d)?$|^\.\d\d$
Позволяет:
1
12
.99
12.34
-18.34
12,345.67
999,999,999,999,999.99
Поскольку этот вопрос был вновь открыт четыре года спустя, я хотел бы предложить другой вариант. Поскольку кто-то тратит много времени на работу с регулярными выражениями, мой взгляд таков:
A. Если возможно, не используйте регулярные выражения для проверки чисел
Если это вообще возможно, используйте свой язык. Могут быть функции, помогающие определить, является ли значение, содержащееся в строке, действительным числом. При этом, если вы принимаете различные форматы (запятые и т. Д.), У вас может не быть выбора.
Б. Не пишите регулярное выражение для проверки диапазона номеров
- Написание регулярного выражения для совпадения числа в заданном диапазоне сложно. Вы можете ошибиться, даже написав регулярное выражение для совпадения числа от 1 до 10.
- Если у вас есть регулярное выражение для диапазона номеров, его сложно отладить. Во-первых, смотреть на это ужасно. Во-вторых, как вы можете быть уверены, что он соответствует всем значениям, которые вы хотите, не сопоставляя ни одно из значений, которые вы не хотите? Честно говоря, если ты один, без сверстников, смотрящих через плечо, ты не сможешь. Лучшая техника отладки - это программный вывод целого диапазона чисел и сравнение их с регулярным выражением.
- К счастью, есть инструменты для автоматического создания регулярного выражения для диапазона номеров.
C. Тратьте энергию Regex с умом: используйте инструменты
- Сопоставление чисел в заданном диапазоне является проблемой, которая была решена. Вам не нужно пытаться изобретать велосипед. Это проблема, которая может быть решена программно механическим способом, гарантирующим отсутствие ошибок. Воспользуйтесь этой бесплатной поездкой.
- Решение регулярного выражения с числовым диапазоном может быть несколько раз интересно для изучения. Кроме того, если у вас есть энергия, чтобы инвестировать в развитие своих навыков регулярных выражений, потратьте их на что-то полезное, например, на углубление понимания жадности регулярных выражений, чтение регулярных выражений Unicode, игру с совпадениями нулевой ширины или рекурсию, чтение SO regex FAQ и обнаружение изящных уловок, таких как, как исключить определенные образцы из соответствия регулярному выражению... или чтение классики, такой как Matering Regular Expressions, 3rd Ed или The Regular Expressions Cookbook, 2nd Ed.
Для инструментов вы можете использовать:
- В сети: Regex_for_range
- Офлайн: единственный, о котором я знаю, это
RegexMagic(не бесплатно) от гуру регулярных выражений Яна Гойваертса. Это его новаторский продукт для регулярных выражений, и, насколько я помню, у него есть широкий спектр возможностей для генерации чисел в заданном диапазоне, помимо других функций. - Если условия слишком сложные, автоматически сгенерируйте два диапазона... затем соедините их с оператором чередования
|
D. Упражнение: построение регулярного выражения для спецификаций в вопросе
Эти характеристики довольно широки... но не обязательно расплывчаты. Давайте снова посмотрим на пример значений:
123,456,789
-12,34
1234
-8
Как соотносятся первые два значения? В первом запятая соответствует группе степеней по три. Во втором он, вероятно, соответствует десятичной запятой в числовом формате континентального европейского стиля. Это не означает, что мы должны позволять цифры везде, как в 1,2,3,44, К тому же, мы не должны быть ограничительными. Например, регулярное выражение в принятом ответе не будет соответствовать одному из требований, 123,456,789 (см. демо).
Как мы строим наше регулярное выражение, чтобы соответствовать спецификациям?
- Давайте закрепим выражение между
^а также$чтобы избежать совпадений - Давайте допустим дополнительный минус:
-? - Давайте сопоставим два типа чисел по обе стороны от чередования
(?:this|that): - Слева - европейская цифра с необязательной запятой для десятичной части:
[1-9][0-9]*(?:,[0-9]+)? - Справа число с разделителями тысяч:
[1-9][0-9]{1,2}(?:,[0-9]{3})+
Полное регулярное выражение:
^-?(?:[1-9][0-9]*(?:,[0-9]+)?|[1-9][0-9]{1,2}(?:,[0-9]{3})+)$
Смотрите демо.
Это регулярное выражение не позволяет номера в европейском стиле, начиная с 0, такие как 0,12, Это особенность, а не ошибка. Чтобы соответствовать им, небольшой твик подойдет:
^-?(?:(?:0|[1-9][0-9]*)(?:,[0-9]+)?|[1-9][0-9]{1,2}(?:,[0-9]{3})+)$
Смотрите демо.
Попробуй это:
^-?[\d\,]+$
Это позволит опционально - в качестве первого символа, а затем любая комбинация запятых и цифр.
^[-+]?(\d{1,3})(,?(?1))*$
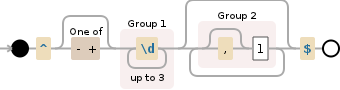
Так что же это?!
^отмечает начало строки[-+]?позволяет минус или плюс сразу после начала строки(\d{1,3})соответствует как минимум одному и максимум трем ({1,3}) цифры (\d- обычно[0-9]) подряд и группирует их (скобки(...)строит группу) как первая группа(,?(?1))*хорошо... давай разберемся с этим(...)строит другую группу (не так важно),?соответствует запятой (если существует) сразу после первой последовательности цифр(?1)снова соответствует шаблону первой группы (помните(\d{1,3})); в словах: в этот момент выражение соответствует знаку (плюс / минус / нет), за которым следует последовательность цифр, возможно, за которой следует запятая, а затем снова другая последовательность цифр.(,?(?1))*,*повторяет вторую часть (запятая и последовательность) как можно чаще
$наконец совпадает с концом строки
Преимущество таких выражений состоит в том, чтобы не определять снова и снова и снова один и тот же шаблон в вашем выражении... ну, иногда недостатком является сложность:-/
^-? # start of line, optional -
(\d+ # any number of digits
|(\d{1,3}(,\d{3})*)) # or digits followed by , and three digits
((,|\.)\d+)? # optional comma or period decimal point and more digits
$ # end of line
В Java вы можете использовать java.util.Scanner с этими useLocale метод
Scanner myScanner = new Scanner(input).useLocale( myLocale)
isADouble = myScanner.hasNextDouble()
Попробуй это:
boxValue = boxValue.replace(/[^0-9\.\,]/g, "");
Этот RegEx будет соответствовать только цифрам, точкам и запятым.
Для примеров:
^(-)?([,0-9])+$
Он должен работать. Реализуйте это на любом языке, который вы хотите.