Каковы ограничения файла в Git (количество и размер)?
Кто-нибудь знает, каковы ограничения Git для количества файлов и размера файлов?
11 ответов
Это сообщение от самого Линуса может помочь вам с некоторыми другими ограничениями
[...] CVS, то есть он действительно в значительной степени ориентирован на модель "один файл за раз".
И это хорошо, потому что вы можете иметь миллион файлов, а затем проверить только несколько из них - вы даже никогда не увидите влияния других 999,995 файлов.
Git принципиально никогда не смотрит меньше, чем весь репо. Даже если вы немного ограничиваете вещи (то есть проверяете только часть или возвращаете историю немного назад), git в конечном итоге все равно всегда заботится обо всем и несет знания.
Так что git действительно плохо масштабируется, если вы заставляете его смотреть на все как на один огромный репозиторий. Я не думаю, что эта часть действительно исправима, хотя мы, вероятно, можем улучшить ее.
И да, тогда есть проблемы "большого файла". Я действительно не знаю, что делать с огромными файлами. Мы сосем их, я знаю.
Смотрите больше в моем другом ответе: ограничение с Git состоит в том, что каждый репозиторий должен представлять собой " согласованный набор файлов", саму "всю систему" (вы не можете пометить "часть репозитория").
Если ваша система состоит из автономных (но взаимозависимых) частей, вы должны использовать субмодули.
Как показано в ответе Talljoe, предел может быть системным (большое количество файлов), но если вы понимаете природу Git (о согласованности данных, представленной его ключами SHA-1), вы поймете истинный "предел" это одно использование: то есть вы не должны пытаться хранить все в Git-репозитории, если вы не готовы всегда получать или помечать все обратно. Для некоторых крупных проектов это не имеет смысла.
Для более глубокого изучения ограничений git см. " Git с большими файлами"
(в котором упоминается git-lfs: решение для хранения больших файлов вне git-репозитория. GitHub, апрель 2015 г.)
Три проблемы, которые ограничивают git-репо:
- огромные файлы ( xdelta для packfile находится только в памяти, что плохо с большими файлами)
- огромное количество файлов, что означает, один файл на блоб, и медленный git gc для генерации по одному пакетному файлу за раз.
- огромные файлы пакета, с индексом файла пакета, неэффективным для извлечения данных из (огромного) файла пакета.
Более поздняя ветка (февраль 2015 г.) иллюстрирует ограничивающие факторы для репозитория Git:
Будут ли несколько одновременных клонов с центрального сервера замедлять другие параллельные операции для других пользователей?
При клонировании сервер не блокируется, поэтому теоретически клонирование не влияет на другие операции. Клонирование может использовать много памяти (и много процессора, если вы не включите функцию растрового изображения, что вам следует).
Будет '
git pull'быть медленным?Если мы исключим серверную сторону, размер вашего дерева является основным фактором, но ваши 25k-файлы должны быть хорошими (linux имеет 48k-файлы).
'
git push"?Это не зависит от того, насколько глубока история вашего репо или насколько широк ваше дерево, поэтому должно быть быстрым.
Ах, количество рефери может повлиять как на
git-pushа такжеgit-pull,
Я думаю, что Стефан знает лучше меня в этой области.'
git commit"? (Он указан как медленный в ссылке 3.) 'git status"? (Снова медленно в ссылке 3, хотя я этого не вижу.)
(такжеgit-add)Опять размер вашего дерева. При размере вашего репо, я не думаю, что вам нужно беспокоиться об этом.
Некоторые операции могут показаться не повседневными, но если они часто вызываются веб-интерфейсом в GitLab/Stash/GitHub и т. Д., То они могут стать узкими местами. (например,
git branch --containsкажется, очень сильно пострадали от большого количества филиалов.)
git-blameможет быть медленным, когда файл сильно изменяется.
Нет никаких реальных ограничений - все названо 160-битным именем. Размер файла должен быть представлен в 64-битном числе, поэтому здесь нет никаких ограничений.
Однако есть практический предел. У меня есть репозиторий ~8 ГБ с>880000, и Git GC занимает некоторое время. Рабочее дерево довольно большое, поэтому операции, которые затем проверяют весь рабочий каталог, занимают довольно много времени. Этот репо используется только для хранения данных, так что это всего лишь набор автоматизированных инструментов, которые обрабатывают его. Извлечение изменений из репозитория намного, намного быстрее, чем повторная синхронизация тех же данных.
%find . -type f | wc -l
791887
%time git add .
git add . 6.48s user 13.53s system 55% cpu 36.121 total
%time git status
# On branch master
nothing to commit (working directory clean)
git status 0.00s user 0.01s system 0% cpu 47.169 total
%du -sh .
29G .
%cd .git
%du -sh .
7.9G .
Если вы добавляете файлы слишком большого размера (в моем случае это ГБ, Cygwin, XP, 3 ГБ ОЗУ), ожидайте этого.
фатальный: нехватка памяти, malloc не удалось
Подробнее здесь
Обновление 3/2/11: увидел подобное в Windows 7 x64 с помощью Tortoise Git. Используется тонны памяти, очень и очень медленный отклик системы.
Еще в феврале 2012 года в списке рассылки Git была очень интересная тема от Джошуа Редстоуна, инженера-программиста Facebook, тестирующего Git в огромном тестовом репозитории:
Тестовое репо имеет 4 миллиона коммитов, линейную историю и около 1,3 миллиона файлов.
Проведенные тесты показывают, что для такого репо Git непригоден (холодная операция длится минуты), но это может измениться в будущем. В основном производительность оштрафована количеством stat() вызывает модуль ядра FS, так что это будет зависеть от количества файлов в репо и эффективности кэширования FS. Смотрите также этот Гист для дальнейшего обсуждения.
По состоянию на 2023 год мое практическое правило состоит в том, чтобы попытаться сохранить в вашем репозитории <524288 файлов (файлы + каталоги) и, возможно, несколько сотен ГБ... но для меня это всего лишь 2,1 миллиона файлов по 107 ГБ.
Число 524288, по-видимому, является максимальным количеством индексных дескрипторов, которые Linux может отслеживать на наличие изменений одновременно (с помощью «наблюдения за индексными дескрипторами»), и я думаю, насколько быстро находит измененные файлы - через уведомления об индексных дескрипторах или что-то в этом роде. Обновление: от @VonC, ниже:
Когда вы получаете предупреждение о недостаточном количестве часов, это происходит потому, что количество файлов в вашем репозитории превысило текущий предел. Увеличение лимита позволяет
inotify(и, соответственно, Git), чтобы отслеживать больше файлов. Однако это не означает, что Git не будет работать за пределами этого предела: если предел достигнут илиgit add -Aне «пропустил бы» изменения. Вместо этого эти операции могут стать медленнее, поскольку Git придется вручную проверять наличие изменений вместо того, чтобы получать обновления от механизма inotify.
Таким образом, вы можете выйти за пределы 524288 файлов (мой репозиторий ниже составляет 2,1 млн файлов), но все становится медленнее.
Мой эксперимент:
Я только что добавил 2095789 (~2,1M) файлов , общим объемом ~107 ГБ , в новый репозиторий. По сути, данные представляли собой всего лишь фрагмент кода и данных сборки размером 300 МБ, дублированный несколько сотен раз на протяжении многих лет, причем каждая новая папка представляла собой слегка измененную версию предыдущей.
Git сделал это, но ему это не понравилось. Я использую действительно высокопроизводительный ноутбук (20 ядер, быстрый, ноутбук Dell Precision 5570, 64 ГБ ОЗУ, реальный высокоскоростной 3500 МБ/сек m.2, твердотельный накопитель емкостью 2 ТБ), работающий под управлением Linux Ubuntu 22.04.2, и вот мои результаты:
git --versionшоуgit version 2.34.1.git initбыло мгновенным.time git add -Aпотребовалось 17 минут 37,621 секунды.time git commitзаняло около 11 минут, так как видимо надо было бежать, собирать вещи.Я рекомендую использовать
time git commit -m "Add all files"вместо этого, чтобы текстовый редактор не открывал файл размером 2,1 МБ. Sublime Text был установлен в качестве моего редактора git в соответствии с моими инструкциями здесь , и он справился с этим нормально, но его открытие заняло несколько секунд, и у него не было подсветки синтаксиса, как обычно.Пока мой редактор коммитов был открыт и я печатал сообщение о коммите, у меня появилось всплывающее окно с графическим интерфейсом:
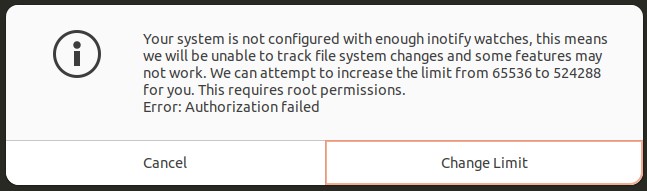
Текст:
В вашей системе недостаточно средств отслеживания inotify. Это означает, что мы не сможем отслеживать изменения файловой системы, а некоторые функции могут не работать. Мы можем попытаться увеличить для вас лимит с 65536 до 524288. Для этого требуются права root.
Ошибка: авторизация не удаласьИтак, я нажал «Изменить лимит» и ввел свой пароль root.
Кажется, это указывает на то, что если в вашем репо имеется более 524288 (~ 500 тыс.) файлов и папок, то git не может гарантировать, что заметит измененные файлы с помощью , не так ли?
После закрытия редактора коммитов вот о чем думал мой компьютер во время фиксации и упаковки данных:
Обратите внимание, что мое базовое использование ОЗУ составляло где-то около 17 ГБ, поэтому я предполагаю, что только ~10 ГБ из этого использования ОЗУ приходится на . На самом деле, «на глазок» график памяти ниже показывает, что использование моей оперативной памяти увеличилось с ~25% до фиксации, достигнув пика до ~53% во время фиксации, при общем использовании 53-23 = 28% x 67,1 ГБ = приблизительно 18,79 ГБ . Использование оперативной памяти.
Это имеет смысл, поскольку я вижу, что мой основной пак-файл составляет 10,2 ГБ, вот здесь:
.git/objects/pack/pack-0eef596af0bd00e16a9ba77058e574c23280e28f.pack. Таким образом, если рассуждать логически, потребуется как минимум столько же памяти, чтобы загрузить этот файл в ОЗУ и работать с ним, чтобы упаковать его.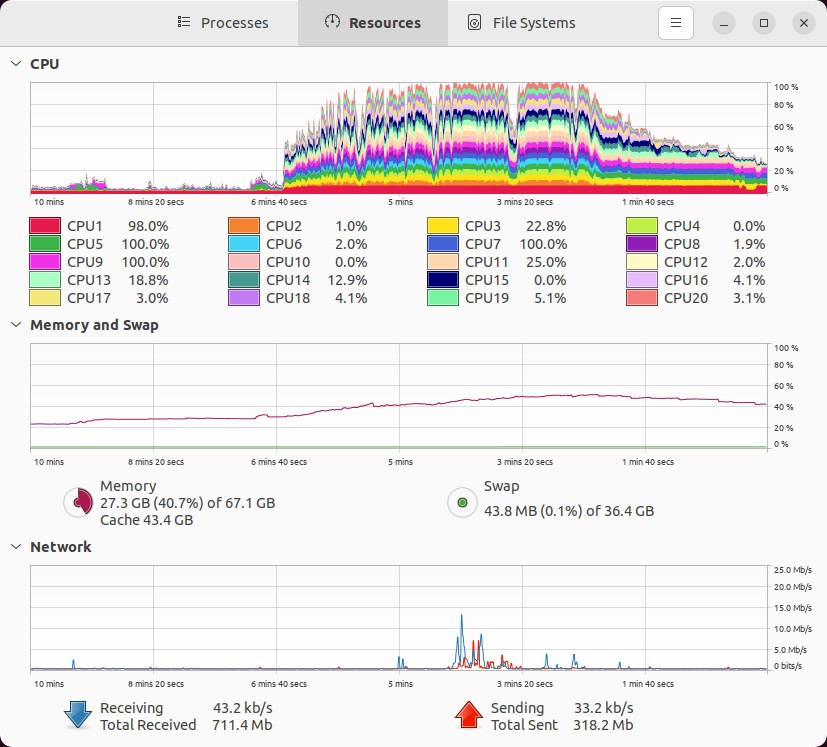
И вот что git вывел на экран:
$ time git commit Auto packing the repository in background for optimum performance. See "git help gc" for manual housekeeping.На выполнение ушло около 11 минут.
time git statusтеперь чисто, но это занимает около 2-3 секунд. Иногда он печатает обычное сообщение, например:$ time git status On branch main nothing to commit, working tree clean real 0m2.651s user 0m1.558s sys 0m7.365sИ иногда он печатает что-то еще с этим сообщением, похожим на предупреждение/уведомление:
$ time git status On branch main It took 2.01 seconds to enumerate untracked files. 'status -uno' may speed it up, but you have to be careful not to forget to add new files yourself (see 'git help status'). nothing to commit, working tree clean real 0m3.075s user 0m1.611s sys 0m7.443s^^^ Я предполагаю, что именно об этом говорил @VonC в своем комментарии, который я поместил в самом верху этого ответа: как это занимает больше времени, поскольку у меня недостаточно «инодных часов», чтобы отслеживать все файлы одновременно.
Сжатие очень хорошее , т.
du -sh .gitпоказывает это:$ du -sh .git 11G .gitИтак, мой каталог со всем содержимым (все 2,1 МБ файлов и 107 ГБ данных) занимает всего 11 ГБ.
Git пытается дедуплицировать данные между повторяющимися файлами , так что это хорошо.
Повторный запуск занял около 43 секунд и не оказал дополнительного влияния на размер моего каталога, вероятно, поскольку в моем репозитории есть только один коммит, и он запускался только тогда, когда
git commitвпервые сказал несколько минут назад. Смотрите мой ответ чуть выше для вывода.Общий размер каталога: активная файловая система + каталог составляет 123 ГБ:
$ time du -sh 123G . real 0m2.072s user 0m0.274s sys 0m1.781sВот насколько быстрый мой SSD. Это часть того, почему
git gcзаняло всего 11 минут (остальное — мои процессоры):Тест скорости Gnome Disks показывает скорость чтения 3,5 ГБ/с. Я ожидаю, что скорость записи составит ~75% от этой:

Я полагаю, что приведенный выше тест проводится на уровне блоков, который ниже уровня файловой системы. Я ожидаю, что скорость чтения и записи на уровне файловой системы будет составлять 1/10 от указанной выше скорости (варьируется от 1/5 до 1/20 от скорости на уровне блоков).
На этом мой реальный тест данных в git завершается. Я рекомендую вам придерживаться файлов размером менее 500 тыс. По размеру, не знаю. Возможно, вам подойдет 50 ГБ, 2 ТБ или 10 ТБ, если количество файлов приближается к 500 тысячам файлов или меньше.
Идти дальше:
1. Передача кому-нибудь моего репозитория объемом 107 ГБ через каталог размером 11 ГБ.
Теперь, когда git сжал мои 107 ГБ из 2,1 млн файлов в каталог размером 11 ГБ, я могу легко воссоздать этот каталог или поделиться им с коллегами, чтобы передать им весь репозиторий! Не копируйте весь каталог репозитория размером 123 ГБ. Вместо этого, если ваш репозиторий называется , просто создайте пустой каталог на внешнем диске, скопируйте в него только каталог, а затем передайте его коллеге. Они копируют его на свой компьютер, а затем воссоздают все рабочее дерево в репозитории следующим образом:
cd path/to/my_repo
# Unpack the whole working tree from the compressed .git dir.
# - WARNING: this permanently erases any changes not committed, so you better
# not have any uncommitted changes lying around when using `--hard`!
time git reset --hard
Для меня на этом же высокопроизводительном компьютереtime git reset --hardкоманда распаковки заняла 7 минут 32 секунды , иgit statusснова чист.
Если каталог сжат в.tar.xzфайл как, вместо этого инструкции могут выглядеть так:
Как восстановить все 107 ГБ
my_repoрепо от
my_repo.tar.xz, который содержит только 11 ГБ
.gitреж.:
# Extract the archive (which just contains a .git dir)
mkdir -p my_repo
time tar -xf my_repo.tar.xz --directory my_repo
# In a **separate** terminal, watch the extraction progress by watching the
# output folder grow up to ~11 GB with:
watch -n 1 'du -sh my_repo'
# Now, have git unpack the entire repo
cd my_repo
time git status | wc -l # Takes ~4 seconds on a high-end machine, and shows
# that there are 1926587 files to recover.
time git reset --hard # Will unpack the entire repo from the .git dir!;
# takes about 8 minutes on a high-end machine.
2. Сравнение изменений между скопированными версиями папок вmeld
Сделай это:
meld path/to/code_dir_rev1 path/to/code_dir_rev2
Meld открывает представление сравнения папок, как если бы вы находились в проводнике. Измененные папки и файлы будут окрашены. Нажмите на папки, затем на измененные файлы, чтобы увидеть, как они открывают представление параллельного сравнения файлов, чтобы просмотреть изменения. Meld открывает это в новой вкладке. По завершении закройте вкладку и вернитесь к виду папки. Найдите другой измененный файл и повторите. Это позволяет мне быстро сравнивать эти измененные версии папок без предварительного ввода их вручную в линейную историю git, как это должно было быть в первую очередь.
Смотрите также:
- Мой ответ: как рекурсивно запустить
dos2unix(или любую другую команду) в нужном каталоге или пути, используя несколько процессов - Выполняет ли git дедупликацию между файлами?
- Брайан Гарри из Microsoft, о «Самом большом репозитории Git на планете» . У Microsoft, очевидно, есть огромный монорепозиторий объемом 300 ГБ с 3,5 миллионами файлов, в которых содержится практически весь их код. (Мне бы не хотелось быть удаленным работником и попытаться добиться этого...)
- @VonC о цепочках графов фиксации и о том, насколько быстр git
Это зависит от вашего значения. Существуют практические ограничения по размеру (если у вас много больших файлов, это может быть скучно медленно). Если у вас много файлов, сканирование также может быть медленным.
Тем не менее, на самом деле нет ограничений, присущих модели. Вы, конечно, можете использовать это плохо и быть несчастным.
По состоянию на 2018-04-20 в Git для Windows есть ошибка, которая эффективно ограничивает размер файла до 4 ГБ макс при использовании этой конкретной реализации (эта ошибка распространяется также на lfs).
Я думаю, что это хорошая попытка избежать фиксации больших файлов как части репозитория (например, дамп базы данных может быть лучше в другом месте), но если учесть размер ядра в его репозитории, вы, вероятно, можете ожидать, что он будет работать комфортно с чем-то меньшим по размеру и менее сложным, чем это.
У меня есть большое количество данных, которые хранятся в моем репо как отдельные фрагменты JSON. В нескольких каталогах содержится около 75 000 файлов, и это не сильно сказывается на производительности.
Проверка их в первый раз была, очевидно, немного медленной.
Я обнаружил, что это пытается сохранить огромное количество файлов (350k+) в репо. Да, магазин. Смеётся.
$ time git add .
git add . 333.67s user 244.26s system 14% cpu 1:06:48.63 total
Следующие выдержки из документации Bitbucket довольно интересны.
Когда вы работаете с клонированием и проталкиванием репозитория DVCS, вы работаете со всем репозиторием и всей его историей. На практике, когда ваш репозиторий станет больше 500 МБ, вы можете начать видеть проблемы.
... 94% клиентов Bitbucket имеют репозитории менее 500 МБ. И ядро Linux, и Android меньше 900 МБ.
Рекомендуемое решение на этой странице - разделить ваш проект на более мелкие части.
Git имеет лимит 4G (32 бита) для репо.