Как поместить наборы данных, созданные torchvision.datasets в GPU, в одну операцию?
Я имею дело с CIFAR10 и использую torchvision.datasets для его создания. Мне нужен графический процессор для ускорения вычислений, но я не могу найти способ поместить весь набор данных в графический процессор за один раз. В моей модели нужно использовать мини-партии, и на каждую партию уходит много времени.
Я пытался поместить каждую мини-серию в графический процессор отдельно, но это кажется очень трудоемким.
2 ответа
TL;DR
Вы не сэкономите время, перемещая весь набор данных одновременно.
Я не думаю, что вы обязательно захотите сделать это, даже если у вас есть память GPU для обработки всего набора данных (конечно, CIFAR10 крошечный по современным стандартам).
Я пробовал разные размеры пакетов и рассчитывал время перехода на GPU следующим образом:
num_workers = 1 # Set this as needed
def time_gpu_cast(batch_size=1):
start_time = time()
for x, y in DataLoader(dataset, batch_size, num_workers=num_workers):
x.cuda(); y.cuda()
return time() - start_time
# Try various batch sizes
cast_times = [(2 ** bs, time_gpu_cast(2 ** bs)) for bs in range(15)]
# Try the entire dataset like you want to do
cast_times.append((len(dataset), time_gpu_cast(len(dataset))))
plot(*zip(*cast_times)) # Plot the time taken
За num_workers = 1 вот что я получил:
И если мы попробуем параллельную загрузку (num_workers = 8) становится еще понятнее 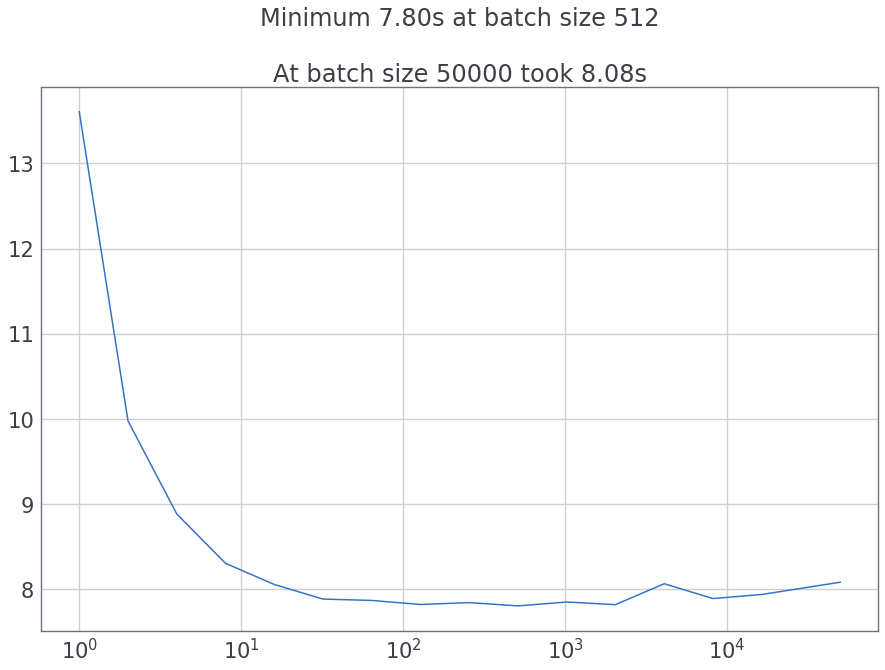
У меня есть ответ, и я попробую его позже. Это кажется многообещающим.
Вы можете написать класс набора данных, в котором в функции init вы красите весь набор данных, примените все необходимые преобразования и преобразуете их в тензорный формат. Затем отправьте этот тензор в GPU (при условии, что памяти достаточно). Затем в функции getitem вы можете просто использовать индекс для извлечения элементов этого тензора, который уже находится в графическом процессоре.