Может ли x86 переупорядочить узкий магазин с более широкой загрузкой, которая полностью его содержит?
В Руководстве разработчика программного обеспечения для архитектур Intel® 64 и IA-32 говорится:
8.2.3.4 Грузы могут быть переупорядочены с более ранними магазинами в разные места
Модель упорядочения памяти Intel-64 позволяет переупорядочивать нагрузку с более ранним хранилищем в другое место. Однако грузы не переупорядочиваются с магазинами в одном месте.
А как насчет нагрузок, которые частично или полностью перекрывают предыдущие магазины, но не имеют одинаковый начальный адрес? (См. Конец этого поста для конкретного случая)
Предположим, следующий C-подобный код:
// lock - pointer to an aligned int64 variable
// threadNum - integer in the range 0..7
// volatiles here just to show direct r/w of the memory as it was suggested in the comments
int TryLock(volatile INT64* lock, INT64 threadNum)
{
if (0 != *lock)
return 0; // another thread already had the lock
((volatile INT8*)lock)[threadNum] = 1; // take the lock by setting our byte
if (1LL << 8*threadNum != *lock)
{ // another thread set its byte between our 1st and 2nd check. unset ours
((volatile INT8*)lock)[threadNum] = 0;
return 0;
}
return 1;
}
Или его эквивалент x64 asm:
; rcx - address of an aligned int64 variable
; rdx - integer in the range 0..7
TryLock PROC
cmp qword ptr [rcx], 0
jne @fail
mov r8, rdx
mov rax, 8
mul rdx
mov byte ptr [rcx+r8], 1
bts rdx, rax
cmp qword ptr [rcx], rdx
jz @success
mov byte ptr [rcx+r8], 0
@fail:
mov rax, 0
ret
@success:
mov rax, 1
ret
Затем предположим, что TryLock одновременно выполняется в двух потоках:
INT64 lock = 0;
void Thread_1() { TryLock(&lock, 1); }
void Thread_5() { TryLock(&lock, 5); }
Вопрос:
((INT8*)lock)[1] = 1; а также ((INT8*)lock)[5] = 1; магазины не находятся в том же месте, что и 64-битная загрузка lock, Тем не менее, каждый из них полностью содержится в этой загрузке, поэтому считается ли это "одним и тем же местом"? Кажется невозможным, чтобы процессор мог это сделать.
Как насчет ((INT8*)lock)[0] = 1? Адрес магазина тогда совпадает с адресом следующей загрузки. Являются ли эти операции "в том же месте", даже если предыдущий случай не был?
Пожалуйста, обратите внимание, что вопрос не в коде C/Asm, а в поведении процессоров x86.
2 ответа
Может ли x86 переупорядочить узкий магазин с более широкой загрузкой, которая полностью его содержит?
Да, x86 может переупорядочить узкое хранилище с более широкой загрузкой, которая полностью его содержит.
Вот почему ваш алгоритм блокировки нарушен, shared_value не равно 800000:
GCC 6.1.0 x86_64 - ссылка на код ассемблера: https://godbolt.org/g/ZK9Wql
shared_value =662198: http://coliru.stacked-crooked.com/a/157380085ccad40f
Clang 3.8.0 x86_64 - ссылка на код ассемблера: https://godbolt.org/g/qn7XuJ
shared_value =538246: http://coliru.stacked-crooked.com/a/ecec7f021a2a9782
Смотрите ниже правильный пример.
Вопрос:
((INT8*) блокировка)[ 1 ] = 1; и ((INT8*) блокировка)[ 5 ] = 1; магазины находятся не в том же месте, что и 64-битная загрузка блокировки. Тем не менее, каждый из них полностью содержится в этой загрузке, поэтому считается ли это "одним и тем же местом"?
Нет, это не так.
В Руководстве разработчика программного обеспечения для архитектур Intel® 64 и IA-32 говорится:
8.2.3.4 Нагрузки могут быть переупорядочены с более ранними хранилищами в разных местах. Модель упорядочения памяти Intel-64 позволяет переупорядочивать нагрузку с более ранними хранилищами в другое место. Однако грузы не переупорядочиваются с магазинами в одном месте.
Это упрощенное правило для случая, когда STORE и LOAD одинакового размера.
Но общее правило заключается в том, что запись в память задерживается на некоторое время, и STORE (адрес + значение) ставится в очередь в буфере хранилища для ожидания строки кэша в монопольном состоянии (E) - когда эта строка кэша будет признана недействительной (Я) в кеше других CPU-ядер. Но вы можете использовать ASM операцию MFENCE (или любая операция с [LOCK] префикс) для принудительного ожидания завершения записи, и любые последующие инструкции могут быть выполнены только после того, как буфер буфера будет очищен, и STORE будет виден всем ядрам ЦП.
О переупорядочении двух строк:
((volatile INT8*)lock)[threadNum] = 1; // STORE
if (1LL << 8*threadNum != *lock) // LOAD
Если размеры STORE и LOAD равны, тогда LOAD CPU-Core выполняет поиск (Store-forwarding) в Store-Buffer и видит все необходимые данные - вы можете получить все фактические данные прямо сейчас, прежде чем STORE будет выполнен
Если размер STORE и LOAD не равен, STORE (1 байт) и LOAD (8 байт), то даже если LOAD CPU-Core выполняет поиск в Store-Buffer, он видит только 1/8 требуемых данных - вы не можете получить все фактические данные прямо сейчас, прежде чем STORE было сделано. Здесь может быть 2 варианта действий процессора:
case-1: CPU-Core загружает другие данные из строки кэша, которая находится в разделяемом состоянии (S), и перекрывает 1 байт из буфера хранилища, но STORE по-прежнему остается в буфере хранилища и ожидает получения исключительного состояния (E) строка кеша для ее изменения - т.е. CPU-Core считывает данные до того, как STORE был выполнен - в вашем примере это гонки данных (ошибка). STORE-LOAD переупорядочено в LOAD-STORE в глобально видимом. - это именно то, что происходит на x86_64
case-2: CPU-Core ожидает, когда Store-Buffer будет очищен, STORE ожидал исключительное состояние (E) строки кэша и STORE был выполнен, затем CPU-Core загружает все необходимые данные из строки кэша. STORE-LOAD не переупорядочен в глобально видимом. Но это так же, как если бы вы использовали
MFENCE,
Вывод, вы должны использовать MFENCE после МАГАЗИНА в любом случае:
- Это полностью решит проблему в деле-1.
- Это не повлияет на поведение и производительность в случае 2. Явный
MFENCEдля пустого Store-Buffer закончится немедленно.
Правильный пример на ассемблере C и x86_64:
Мы заставляем CPU-Core действовать, как в случае 2, используя MFENCEследовательно, нет переупорядочения StoreLoad
- GCC 6.1.0 (использует
mfenceочистить Store-Buffer): https://godbolt.org/g/dtNMZ7 - Clang 4.0 (использует
[LOCK] xchgb reg, [addr]сбросить Store-Buffer): https://godbolt.org/g/BQY6Ju
Замечания: xchgb всегда имеет префикс LOCK, поэтому обычно не пишется в asm и не указывается в скобках.
Все остальные компиляторы можно выбрать вручную по ссылкам выше: PowerPC, ARM, ARM64, MIPS, MIPS64, AVR.
C-код - должен использовать последовательную согласованность для первого STORE и следующей LOAD:
#ifdef __cplusplus
#include <atomic>
using namespace std;
#else
#include <stdatomic.h>
#endif
// lock - pointer to an aligned int64 variable
// threadNum - integer in the range 0..7
// volatiles here just to show direct r/w of the memory as it was suggested in the comments
int TryLock(volatile uint64_t* lock, uint64_t threadNum)
{
//if (0 != *lock)
if (0 != atomic_load_explicit((atomic_uint_least64_t*)lock, memory_order_acquire))
return 0; // another thread already had the lock
//((volatile uint8_t*)lock)[threadNum] = 1; // take the lock by setting our byte
uint8_t* current_lock = ((uint8_t*)lock) + threadNum;
atomic_store_explicit((atomic_uint_least8_t*)current_lock, (uint8_t)1, memory_order_seq_cst);
//if (1LL << 8*threadNum != *lock)
// You already know that this flag is set and should not have to check it.
if ( 0 != ( (~(1LL << 8*threadNum)) &
atomic_load_explicit((atomic_uint_least64_t*)lock, memory_order_seq_cst) ))
{ // another thread set its byte between our 1st and 2nd check. unset ours
//((volatile uint8_t*)lock)[threadNum] = 0;
atomic_store_explicit((atomic_uint_least8_t*)current_lock, (uint8_t)0, memory_order_release);
return 0;
}
return 1;
}
GCC 6.1.0 - x86_64 asm-code - следует использовать MFENCE для первого магазина:
TryLock(unsigned long volatile*, unsigned long):
movq (%rdi), %rdx
xorl %eax, %eax
testq %rdx, %rdx
je .L7
.L1:
rep ret
.L7:
leaq (%rdi,%rsi), %r8
leaq 0(,%rsi,8), %rcx
movq $-2, %rax
movb $1, (%r8)
rolq %cl, %rax
mfence
movq (%rdi), %rdi
movq %rax, %rdx
movl $1, %eax
testq %rdi, %rdx
je .L1
movb $0, (%r8)
xorl %eax, %eax
ret
Полный пример того, как это работает: /questions/796054/tip-fajla-microsoft-office-2007-tipyi-mime-i-identifitsiruyuschie-simvolyi/796071#796071
shared_value = 800000
Что будет, если вы не используете MFENCE - Data-Races
Существует переупорядочение StoreLoad, как в описанном выше случае-1 (т.е. если не используется последовательная согласованность для STORE) - asm: https://godbolt.org/g/p3j9fR
- GCC 6.1.0 x86_64 -
shared_value = 610307: http://coliru.stacked-crooked.com/a/469f087b1ce32977 - Clang 3.8.0 x86_64 -
shared_value = 678949: /questions/46988236/kris-pajn-rubi-ch-10-rekursiya/46988271#46988271
Я изменил барьер памяти для магазина из memory_order_seq_cst в memory_order_release удаляет MFENCE - и теперь есть гонки данных - shared_value не равно 800000.
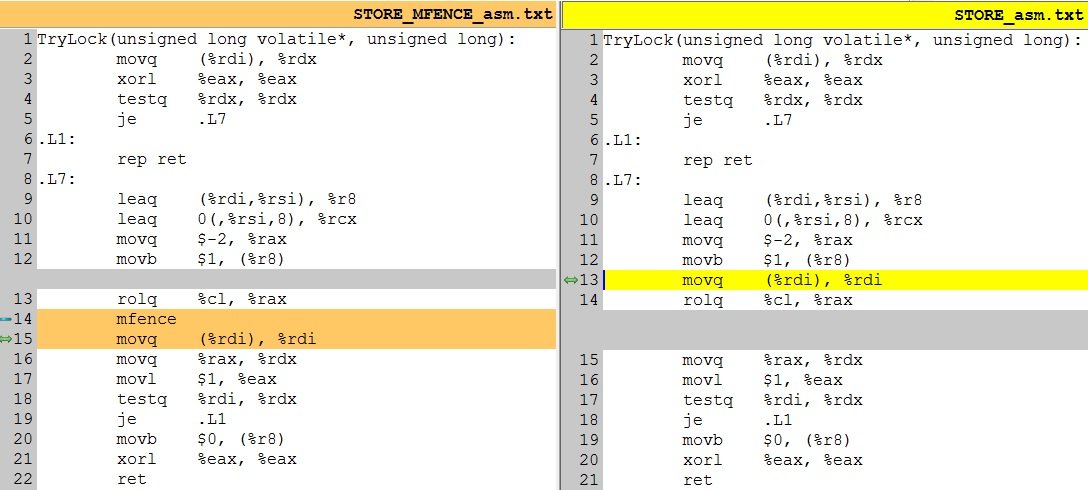
Можно mov byte [rcx+r8], 1 изменить порядок с cmp qword [rcx], rdx нагрузка, которая следует за этим? Это lock[threadNum]=1 сохранить и следующую загрузку, чтобы убедиться, что никто не записал байт.
Загрузка должна возвращать данные, которые включают в себя хранилище, потому что исполняющий поток всегда наблюдает за своими собственными действиями в программном порядке. (Это верно даже для слабо упорядоченных МСА).
Оказывается, эта идея точной блокировки была предложена ранее (для ядра Linux), и Линус Торвальдс объяснил, что x86 действительно допускает такой вид переупорядочения.
Несмотря на термин "сбой или остановка пересылки из хранилища", это не означает, что данные должны быть зафиксированы в кэше, прежде чем нагрузка сможет их прочитать. На самом деле его можно прочитать из буфера хранилища, пока строка кэша все еще находится в состоянии S ( MESI). (А на ядрах Atom по порядку вы даже не получите магазин-экспедитор.)
Реальное оборудование работает таким образом (как показывают тесты Алекса): ЦП будет объединять данные из L1D с данными из буфера хранилища, не передавая хранилище в L1D.
Это само по себе еще не переупорядочивает 1 (нагрузка видит данные магазина, и они соседствуют в глобальном порядке), но оставляет дверь открытой для переупорядочения. Строка кэша может быть аннулирована другим ядром после загрузки, но до фиксации хранилища. Магазин из другого ядра может стать глобально видимым после нашей загрузки, но до нашего магазина.
Таким образом, загрузка включает данные из нашего собственного хранилища, но не из другого хранилища из другого процессора. Другой процессор может видеть тот же эффект для своей нагрузки, и, таким образом, оба потока входят в критическую секцию.
1 (Это то, о чем я говорил в комментариях к ответу Алекса. Если x86 не разрешил это переупорядочение, процессоры могли бы по-прежнему делать пересылку хранилища спекулятивно, пока хранилище не стало глобально видимым, и сбить его, если другой процессор аннулировал кэш Эта строка ответа Алекса не доказала, что x86 работал так, как работает. Это дали только экспериментальные испытания и тщательное рассуждение о алгоритме блокировки.)
Если бы x86 действительно запретил это переупорядочение, пара "хранилище / частично перекрывающаяся перезагрузка" работала бы как MFENCE: более ранние загрузки не могут стать глобально видимыми до загрузки, а более ранние хранилища не могут стать глобально видимыми до магазина. Нагрузка должна стать видимой в глобальном масштабе перед любой последующей загрузкой или хранением, и это также предотвратит задержку хранилища.
Учитывая это, не совсем очевидно, почему идеально совпадающие магазины не эквивалентны MFENCE. Возможно, так оно и есть, и x86 может только ускорить разлив / перезагрузку или передачу аргументов в стек с помощью умозрительного выполнения!
Схема блокировки:
Это выглядит как TryLock может потерпеть неудачу для обоих / всех вызывающих абонентов: все они сначала видят ноль, все они записывают свой байт, затем они все видят по крайней мере два ненулевых байта каждый. Это не идеально для замков с сильной конкуренцией по сравнению с использованием lock инструкция Существует механизм аппаратного арбитража для обработки конфликтующих lock Ed Insns. (TODO: найдите сообщение на форуме Intel, где инженер Intel опубликовал это в ответ на очередной цикл повторения программного обеспечения по сравнению с lock Тема инструкций, IIRC.)
Узкое чтение / широкое чтение всегда будет вызывать остановку пересылки магазина на современном оборудовании x86. Я думаю, что это просто означает, что результат загрузки не готов к нескольким циклам, а не то, что выполнение других команд останавливается (по крайней мере, не в проекте ООО).
В легкомысленной блокировке, которая часто используется, ветвь будет правильно предсказана, чтобы выбрать путь без конфликтов. Спекулятивное выполнение по этому пути до тех пор, пока загрузка, наконец, не завершится, и ветвь не сможет отключиться, не должна останавливаться, потому что остановки при пересылке хранилища не достаточно длинные, чтобы заполнить ROB.
- SnB: ~ 12 циклов дольше, чем при пересылке магазина (~ 5c)
- HSW: ~ 10c длиннее
- SKL: на ~11c больше, чем при переадресации магазина (4c для 32- и 64-битных операндов, что на 1c меньше, чем у предыдущих процессоров)
- AMD K8 / K10: Агнер Фог не дает номер.
Семейство AMD Bulldozer: 25-26c (Steamroller)
Atom: "В отличие от большинства других процессоров, Atom может выполнять пересылку хранилища, даже если операнд чтения больше, чем предыдущий операнд записи, или выровнен по-другому", а задержка составляет всего 1с. Сбой только при пересечении границы строки кэша.
- Сильвермонт: ~5c дополнительно (база: 7c)
- AMD Bobcat / Jaguar: 4-11с дополнительно (база: 8с / 3с)
Таким образом, если вся схема блокировки работает, она может быть полезна для слегка оспариваемых блокировок.
Я думаю, что вы можете превратить его в блокировку нескольких читателей / писателей, используя бит 1 в каждом байте для читателей и бит 2 для писателей. TryLock_reader будет игнорировать биты чтения в других байтах. TryLock_writer будет работать как оригинал, требуя нуля во всех битах в других байтах.
Кстати, для того, чтобы упорядочить память , блог Джеффа Прешинга превосходен.