Оценка динамических выражений в пандах с использованием pd.eval()
Цель и мотивация
eval а также query являются мощными, но недооцененными функциями в наборе API pandas, и их использование далеко не полностью документировано или понято. С правильным количеством заботы, query а также eval может значительно упростить код, повысить производительность и стать мощным инструментом для создания динамических рабочих процессов.
Цель этой канонической QnA - дать пользователям лучшее понимание этих функций, обсудить некоторые из менее известных функций, как их использовать и как их лучше использовать, с помощью ясных и простых для понимания примеров. В этом посте будут рассмотрены две основные темы:
- понимание
engine,parserа такжеtargetаргументы вpd.evalи как их можно использовать для оценки выражений - Понимание разницы между
pd.eval,df.evalа такжеdf.queryи когда каждая функция подходит для динамического выполнения.
Этот пост не заменяет документацию (ссылки в ответе), поэтому, пожалуйста, пройдите также!
Вопрос
Я сформулирую вопрос таким образом, чтобы начать обсуждение различных функций, поддерживаемых eval,
Учитывая два DataFrames
np.random.seed(0)
df1 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df2 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df1
A B C D
0 5 0 3 3
1 7 9 3 5
2 2 4 7 6
3 8 8 1 6
4 7 7 8 1
df2
A B C D
0 5 9 8 9
1 4 3 0 3
2 5 0 2 3
3 8 1 3 3
4 3 7 0 1
Я хотел бы выполнить арифметику на один или несколько столбцов, используя pd.eval, В частности, я хотел бы перенести следующий код:
x = 5
df2['D'] = df1['A'] + (df1['B'] * x)
... закодировать используя eval, Причина использования eval в том, что я хотел бы автоматизировать многие рабочие процессы, поэтому их динамическое создание будет для меня полезным.
Я пытаюсь лучше понять engine а также parser Аргументы, чтобы определить, как лучше всего решить мою проблему. Я просмотрел документацию, но мне не было ясно, какая разница.
- Какие аргументы следует использовать, чтобы мой код работал с максимальной производительностью?
- Есть ли способ присвоить результат выражения обратно
df2? - Кроме того, чтобы сделать вещи более сложными, как пройти
xв качестве аргумента внутри строкового выражения?
3 ответа
Этот ответ углубляется в различные функции и возможности, предлагаемые pd.eval, df.query, а также df.eval,
Настроить
Примеры будут включать эти DataFrames (если не указано иное).
np.random.seed(0)
df1 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df2 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df3 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df4 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
pandas.eval - "Отсутствует руководство"
Заметка
Из трех обсуждаемых функцийpd.evalсамый важный.df.evalа такжеdf.queryвызовpd.evalпод капотом. Поведение и использование более или менее согласованно для всех трех функций, с некоторыми незначительными семантическими вариациями, которые будут выделены позже. В этом разделе будут представлены функциональные возможности, которые являются общими для всех трех функций - это включает (но не ограничивается) разрешенный синтаксис, правила приоритета и аргументы ключевых слов.
pd.eval может оценивать арифметические выражения, которые могут состоять из переменных и / или литералов. Эти выражения должны быть переданы в виде строк. Итак, чтобы ответить на поставленный вопрос, вы можете сделать
x = 5
pd.eval("df1.A + (df1.B * x)")
Некоторые вещи, чтобы отметить здесь:
- Все выражение является строкой
df1,df2, а такжеxссылаются на переменные в глобальном пространстве имен, они подобраныevalпри разборе выражения- Доступ к определенным столбцам осуществляется с помощью индекса атрибута доступа. Вы также можете использовать
"df1['A'] + (df1['B'] * x)"к тому же эффекту.
Я буду рассматривать конкретную проблему переназначения в разделе, объясняющем target=... атрибут ниже. Но сейчас приведем более простые примеры допустимых операций с pd.eval:
pd.eval("df1.A + df2.A") # Valid, returns a pd.Series object
pd.eval("abs(df1) ** .5") # Valid, returns a pd.DataFrame object
...и так далее. Условные выражения также поддерживаются таким же образом. Приведенные ниже утверждения являются действительными выражениями и будут оцениваться движком.
pd.eval("df1 > df2")
pd.eval("df1 > 5")
pd.eval("df1 < df2 and df3 < df4")
pd.eval("df1 in [1, 2, 3]")
pd.eval("1 < 2 < 3")
Список с подробным описанием всех поддерживаемых функций и синтаксиса можно найти в документации. В итоге,
- Арифметические операции за исключением левого смещения (
<<) и правое смещение (>>) операторы, например,df + 2 * pi / s ** 4 % 42- the_golden_ratio- Операции сравнения, включая цепные сравнения, например,
2 < df < df2- Булевы операции, например,
df < df2 and df3 < df4или жеnot df_boollistа такжеtupleлитералы, например,[1, 2]или же(1, 2)- Доступ к атрибутам, например,
df.a- Подстрочные выражения, например,
df[0]- Простая оценка переменной, например,
pd.eval('df')(это не очень полезно)- Математические функции: sin, cos, exp, log, expm1, log1p, sqrt, sinh, cosh, tanh, arcsin, arccos, arctan, arccosh, arcsinh, arctanh, abs и arctan2.
В этом разделе документации также указаны синтаксические правила, которые не поддерживаются, в том числе set / dict литералы, операторы if-else, циклы и понимания, а также выражения-генераторы.
Из списка очевидно, что вы также можете передавать выражения, включающие индекс, такие как
pd.eval('df1.A * (df1.index > 1)')
Выбор парсера: parser=... аргумент
pd.eval поддерживает две разные опции парсера при разборе строки выражения для генерации синтаксического дерева: pandas а также python, Основное различие между ними выделено слегка отличающимися правилами приоритета.
Использование парсера по умолчанию pandas перегруженные побитовые операторы & а также | которые реализуют векторизованные операции И и ИЛИ с объектами панд, будут иметь тот же приоритет операторов, что и and и `или. Так,
pd.eval("(df1 > df2) & (df3 < df4)")
Будет так же, как
pd.eval("df1 > df2 & df3 < df4")
# pd.eval("df1 > df2 & df3 < df4", parser='pandas')
И так же, как
pd.eval("df1 > df2 and df3 < df4")
Здесь скобки необходимы. Чтобы сделать это условно, парены должны были бы переопределить более высокий приоритет побитовых операторов:
(df1 > df2) & (df3 < df4)
Без этого мы в конечном итоге
df1 > df2 & df3 < df4
ValueError: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
использование parser='python' если вы хотите поддерживать согласованность с действующими правилами приоритета операторов python при оценке строки.
pd.eval("(df1 > df2) & (df3 < df4)", parser='python')
Другое различие между двумя типами парсеров заключается в семантике == а также != операторы с узлами списков и кортежей, семантика которых аналогична in а также not in соответственно при использовании 'pandas' синтаксический анализатор. Например,
pd.eval("df1 == [1, 2, 3]")
Действителен и будет работать с той же семантикой, что и
pd.eval("df1 in [1, 2, 3]")
Ото, pd.eval("df1 == [1, 2, 3]", parser='python') бросит NotImplementedError ошибка.
Выбор внутреннего интерфейса: engine=... аргумент
Есть два варианта - numexpr (по умолчанию) и python, numexpr Опция использует бэкэнд Numberxpr, который оптимизирован для производительности.
С 'python' бэкэнд, ваше выражение оценивается так же, как просто передать выражение в Python eval функция. Вы можете делать больше внутри выражений, например, таких как строковые операции.
df = pd.DataFrame({'A': ['abc', 'def', 'abacus']})
pd.eval('df.A.str.contains("ab")', engine='python')
0 True
1 False
2 True
Name: A, dtype: bool
К сожалению, этот метод не дает никаких преимуществ по сравнению с numexpr двигатель, и существует очень мало мер безопасности, чтобы гарантировать, что опасные выражения не оцениваются, поэтому ИСПОЛЬЗУЙТЕ НА СВОЙ РИСК! Как правило, не рекомендуется менять эту опцию на 'python' если вы не знаете, что делаете.
local_dict а также global_dict аргументы
Иногда полезно предоставить значения для переменных, используемых внутри выражений, но не определенных в вашем пространстве имен. Вы можете передать словарь local_dict
Например,
pd.eval("df1 > thresh")
UndefinedVariableError: name 'thresh' is not defined
Это не удается, потому что thresh не определено. Тем не менее, это работает:
pd.eval("df1 > x", local_dict={'thresh': 10})
Это полезно, когда у вас есть переменные для подачи из словаря. В качестве альтернативы, с 'python' двигатель, вы могли бы просто сделать это:
mydict = {'thresh': 5}
# Dictionary values with *string* keys cannot be accessed without
# using the 'python' engine.
pd.eval('df1 > mydict["thresh"]', engine='python')
Но это будет гораздо медленнее, чем использование 'numexpr' двигатель и передача словаря local_dict или же global_dict, Надеюсь, это должно стать убедительным аргументом в пользу использования этих параметров.
target (+ inplace) аргумент и выражения назначения
Это не часто требуется, потому что обычно есть более простые способы сделать это, но вы можете назначить результат pd.eval к объекту, который реализует __getitem__ такие как dict s, и (как вы уже догадались) DataFrames.
Рассмотрим пример в вопросе
x = 5 df2['D'] = df1['A'] + (df1['B'] * x)
Чтобы назначить столбец "D" df2, мы делаем
pd.eval('D = df1.A + (df1.B * x)', target=df2)
A B C D
0 5 9 8 5
1 4 3 0 52
2 5 0 2 22
3 8 1 3 48
4 3 7 0 42
Это не модификация на месте df2 (но это может быть... читать дальше). Рассмотрим другой пример:
pd.eval('df1.A + df2.A')
0 10
1 11
2 7
3 16
4 10
dtype: int32
Если вы хотите (например) назначить это обратно в DataFrame, вы можете использовать target аргумент следующим образом:
df = pd.DataFrame(columns=list('FBGH'), index=df1.index)
df
F B G H
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN NaN NaN NaN
4 NaN NaN NaN NaN
df = pd.eval('B = df1.A + df2.A', target=df)
# Similar to
# df = df.assign(B=pd.eval('df1.A + df2.A'))
df
F B G H
0 NaN 10 NaN NaN
1 NaN 11 NaN NaN
2 NaN 7 NaN NaN
3 NaN 16 NaN NaN
4 NaN 10 NaN NaN
Если вы хотите выполнить мутацию на месте df, задавать inplace=True,
pd.eval('B = df1.A + df2.A', target=df, inplace=True)
# Similar to
# df['B'] = pd.eval('df1.A + df2.A')
df
F B G H
0 NaN 10 NaN NaN
1 NaN 11 NaN NaN
2 NaN 7 NaN NaN
3 NaN 16 NaN NaN
4 NaN 10 NaN NaN
Если inplace устанавливается без цели, а ValueError Поднялся.
В то время как target с аргументом весело играть, вам редко понадобится его использовать.
Если вы хотите сделать это с df.eval, вы бы использовали выражение, включающее присваивание:
df = df.eval("B = @df1.A + @df2.A")
# df.eval("B = @df1.A + @df2.A", inplace=True)
df
F B G H
0 NaN 10 NaN NaN
1 NaN 11 NaN NaN
2 NaN 7 NaN NaN
3 NaN 16 NaN NaN
4 NaN 10 NaN NaN
Заметка
Один из pd.eval непреднамеренное использование разбирает буквенные строки способом, очень похожим на ast.literal_eval:
pd.eval("[1, 2, 3]")
array([1, 2, 3], dtype=object)
Он также может анализировать вложенные списки с помощью 'python' двигатель:
pd.eval("[[1, 2, 3], [4, 5], [10]]", engine='python')
[[1, 2, 3], [4, 5], [10]]
И списки строк:
pd.eval(["[1, 2, 3]", "[4, 5]", "[10]"], engine='python')
[[1, 2, 3], [4, 5], [10]]
Проблема, однако, для списков с длиной больше 10:
pd.eval(["[1]"] * 100, engine='python') # Works
pd.eval(["[1]"] * 101, engine='python')
AttributeError: 'PandasExprVisitor' object has no attribute 'visit_Ellipsis'
Подробнее об этой ошибке, причинах, исправлениях и обходных путях можно узнать здесь.
DataFrame.eval - сопоставление с pandas.eval
Как уже упоминалось выше, df.eval звонки pd.eval под капотом. Исходный код v0.23 показывает это:
def eval(self, expr, inplace=False, **kwargs):
from pandas.core.computation.eval import eval as _eval
inplace = validate_bool_kwarg(inplace, 'inplace')
resolvers = kwargs.pop('resolvers', None)
kwargs['level'] = kwargs.pop('level', 0) + 1
if resolvers is None:
index_resolvers = self._get_index_resolvers()
resolvers = dict(self.iteritems()), index_resolvers
if 'target' not in kwargs:
kwargs['target'] = self
kwargs['resolvers'] = kwargs.get('resolvers', ()) + tuple(resolvers)
return _eval(expr, inplace=inplace, **kwargs)eval создает аргументы, делает небольшую проверку и передает аргументы pd.eval,
Более подробно вы можете прочитать о: когда использовать DataFrame.eval() против pandas.eval() или python eval()
Различия в использовании
Выражения с помощью DataFrames v/s Series Expressions
Для динамических запросов, связанных со всеми DataFrames, вы должны предпочесть pd.eval, Например, не существует простого способа указать эквивалент pd.eval("df1 + df2") когда ты звонишь df1.eval или же df2.eval,
Указание имен столбцов
Другое важное отличие заключается в том, как осуществляется доступ к столбцам. Например, чтобы добавить два столбца "A" и "B" в df1 позвонил бы pd.eval со следующим выражением:
pd.eval("df1.A + df1.B")
С df.eval вам нужно только указать имена столбцов:
df1.eval("A + B")
Поскольку в контексте df1 Ясно, что "A" и "B" относятся к именам столбцов.
Вы также можете ссылаться на индекс и столбцы, используя index (если индекс не назван, в этом случае вы бы использовали имя).
df1.eval("A + index")
Или, в более общем случае, для любого DataFrame с индексом, имеющим 1 или более уровней, вы можете ссылаться на k- й уровень индекса в выражении, используя переменную "ilevel_k", которая обозначает " i ndex на уровне k ". IOW, выражение выше может быть записано как df1.eval("A + ilevel_0"),
Эти правила также применяются к query,
Доступ к переменным в локальном / глобальном пространстве имен
Переменным, указанным внутри выражений, должен предшествовать символ "@", чтобы избежать путаницы с именами столбцов.
A = 5
df1.eval("A > @A")
То же самое касается query /
Само собой разумеется, что имена ваших столбцов должны соответствовать правилам, чтобы действительные имена идентификаторов в Python были доступны внутри eval, Смотрите здесь список правил именования идентификаторов.
Многострочные Запросы и Назначение
Малоизвестный факт заключается в том, что eval поддержка многострочных выражений, связанных с присваиванием. Например, чтобы создать два новых столбца "E" и "F" в df1 на основе некоторых арифметических операций над некоторыми столбцами и третий столбец "G" на основе ранее созданных "E" и "F", мы можем сделать
df1.eval("""
E = A + B
F = @df2.A + @df2.B
G = E >= F
""")
A B C D E F G
0 5 0 3 3 5 14 False
1 7 9 3 5 16 7 True
2 2 4 7 6 6 5 True
3 8 8 1 6 16 9 True
4 7 7 8 1 14 10 True
... Острота! Тем не менее, обратите внимание, что это не поддерживается query,
eval в / с query - Заключительное слово
Это помогает думать о df.query как функция, которая использует pd.eval в качестве подпрограммы.
Как правило, query (как следует из названия) используется для оценки условных выражений (т. е. выражений, которые приводят к значениям True/False) и возвращают строки, соответствующие True результат. Результат выражения затем передается loc (в большинстве случаев), чтобы вернуть строки, которые удовлетворяют выражению. Согласно документации,
Результат оценки этого выражения сначала передается
DataFrame.locи если это не удается из-за многомерного ключа (например, DataFrame), то результат будет переданDataFrame.__getitem__(),Этот метод использует верхний уровень
pandas.eval()функция для оценки пройденного запроса.
С точки зрения сходства, query а также df.eval оба одинаковы в том, как они получают доступ к именам столбцов и переменным.
Эта ключевая разница между ними, как упоминалось выше, заключается в том, как они обрабатывают результат выражения. Это становится очевидным, когда вы фактически запускаете выражение через эти две функции. Например, рассмотрим
df1.A
0 5
1 7
2 2
3 8
4 7
Name: A, dtype: int32
df2.B
0 9
1 3
2 0
3 1
4 7
Name: B, dtype: int32
Чтобы получить все строки, где "A" >= "B" в df1 мы бы использовали eval как это:
m = df1.eval("A >= B")
m
0 True
1 False
2 False
3 True
4 True
dtype: bool
m представляет промежуточный результат, полученный путем вычисления выражения "A >= B". Затем мы используем маску для фильтрации df1:
df1[m]
# df1.loc[m]
A B C D
0 5 0 3 3
3 8 8 1 6
4 7 7 8 1
Однако с query промежуточный результат "m" напрямую передается loc так с query, вам просто нужно сделать
df1.query("A >= B")
A B C D
0 5 0 3 3
3 8 8 1 6
4 7 7 8 1
Производительность мудрая, она точно такая же.
df1_big = pd.concat([df1] * 100000, ignore_index=True)
%timeit df1_big[df1_big.eval("A >= B")]
%timeit df1_big.query("A >= B")
14.7 ms ± 33.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
14.7 ms ± 24.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Но последний является более кратким и выражает ту же операцию за один шаг.
Обратите внимание, что вы также можете делать странные вещи с query вот так (скажем, чтобы вернуть все строки, проиндексированные df1.index)
df1.query("index")
# Same as df1.loc[df1.index] # Pointless,... I know
A B C D
0 5 0 3 3
1 7 9 3 5
2 2 4 7 6
3 8 8 1 6
4 7 7 8 1
Но не надо.
Итог: пожалуйста, используйте query при запросе или фильтрации строк на основе условного выражения.
Отличный учебник уже, но имейте в виду, что, прежде чем дико прыгать в использование eval/query Привлеченный своим более простым синтаксисом, он имеет серьезные проблемы с производительностью, если ваш набор данных содержит менее 15 000 строк.
В этом случае просто используйте df.loc[mask1, mask2],
См. https://pandas.pydata.org/pandas-docs/version/0.22/enhancingperf.html.
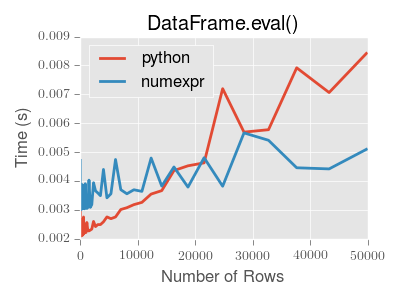
Отличный учебник @cs95. Я просматривал книгу Джейка Вандерпласа (Справочник Python DataScience, и в ней был код:
births['decade'] = 10 * (births['year'] // 10)
Если вы посмотрите на floordiv() (//) выше, я не смог сделать это с помощью eval ().
births.eval("decade = 10 * (year // 10)")
Это дает ошибку. Однако, прочитав вашу статью, я поменял движок, и он заработал нормально.
births.eval("decade = 10 * (year // 10)", engine= "python")
Спасибо @cs95.