Сохранение искрового фрейма данных в фиксированном формате с различной шириной столбца
У меня есть PySpark dataframe (df), который выглядит так:
Входные данные:
+----+------------+-----------+
| id | first_name | last_name |
+----+------------+-----------+
| 1 | Zed | Seiler |
| 2 | Piotr | Ricardon |
| 3 | Ardeen | Crotch |
| 4 | Dredi | Steward |
| 5 | Adler | Putnam |
+----+------------+-----------+
Я хочу сохранить этот фрейм данных в фиксированном формате. Поля должны быть выровнены по левому краю. Фиксированный формат имеет различную ширину столбца и выглядит следующим образом:
+-------------------+-------+------------+-----------+
| column name = id | first_name | last_name |
+-------------------+-------+------------+-----------+
| Starting position = 1 | 6 | 16 |
+-------------------+-------+------------+-----------+
| Column Width = 5 | 10 | 20 |
+-------------------+-------+------------+-----------+
| DataType = int | char | char |
+-------------------+-------+------------+-----------+
| LPAD 0 = yes | no | no |
+-------------------+-------+------------+-----------+
| Sample input Data = 1 | zed | seiler |
+-------------------+-------+------------+-----------+
| Sample output Data= 00001 | zed | seiler |
+-------------------+-------+------------+-----------+
Пример ожидаемого выхода:
00001Zed Seiler
00002Piotr Ricardon
00003Ardeen Crotch
00004Dredi Steward
00005Adler Putnam
Я пытался реализовать решение с использованием Pandas, но оно не работает, получая ошибку значения, но когда я запускаю то же самое в кластере сообщества databricks, оно работает.
import pandas
vdf= df.toPandas()
dfrow = len(vdf.index)
#print (dfrow)
v = vdf.values.T.tolist()
for i in range(0,dfrow):
print(( '{:>05}{:<10}{:<20}'.format(v[0][i],v[1][i],v[2][i] )))
Окончательный вывод будет сохранен в формате hdf в текстовом формате.
Выход кластера базы данных: 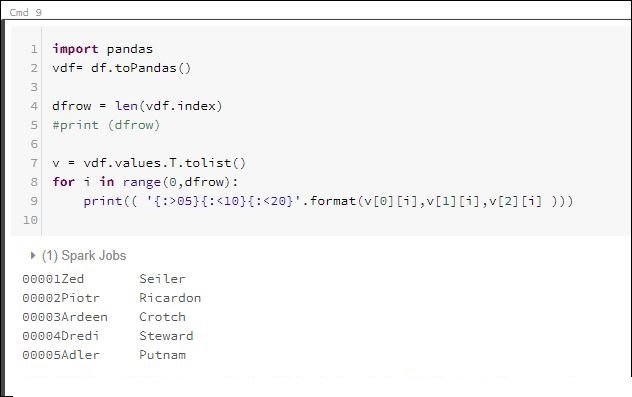
Будем весьма благодарны за любые рекомендации относительно наилучшего альтернативного способа сохранения PySpark DataFrame в фиксированном формате с различной шириной столбца в HDFS.