[Python+Altair (Vega-lite)]: потоковая передача с датафрейма Pandas в стиле Excel
У меня есть Dataframe от Pandas, который я хотел бы визуализировать с помощью Altair, но похоже, что синтаксис библиотеки все еще выше моих навыков:
Time WL1 WL2 WL3 WL4
0 2017-04-05 09:15:00 103448.0 100776.0 71581.1 81118.2
1 2017-04-05 09:30:00 114730.0 113206.0 68600.1 78322.2
2 2017-04-05 09:45:00 117252.0 114189.0 68208.5 77261.0
3 2017-04-05 10:00:00 115569.0 111300.0 67454.7 75347.4
4 2017-04-05 10:15:00 117504.0 114956.0 68709.9 76345.1
5 2017-04-05 10:30:00 116123.0 112637.0 66210.9 74544.4
6 2017-04-05 10:45:00 111050.0 106342.0 61699.3 70165.2
7 2017-04-05 11:00:00 111221.0 108409.0 66124.6 74842.1
8 2017-04-05 11:15:00 111604.0 106853.0 66950.5 75782.9
9 2017-04-05 11:30:00 113026.0 108071.0 68222.2 77848.0
Я не могу найти синтаксис для создания потокового графа, подобного этому, взятого из учебника Альтаира (06-AreaCharts): 
Я могу визуализировать отдельные строки, но это не лучшее представление для моих данных:
LayeredChart(data,
layers=[
Chart().mark_line().encode(
x='Time:T',
y='WL1:Q',
),
Chart().mark_line().encode(
x='Time:T',
y='WL2:Q',
),
Chart().mark_line().encode(
x='Time:T',
y='WL3:Q',
),
Chart().mark_line().encode(
x='Time:T',
y='WL4:Q',
),
]
)
Есть ли способ создать Streamgraph, не проходя через LayeredChart, непосредственно из фрейма данных с несколькими столбцами?
1 ответ
Эта страница содержит код для потокового графа.
Кстати, вы можете сравнить код со спецификацией json vega-lite, чтобы лучше понять синтаксис Altair.
Возможно, уже очень поздно, но я надеюсь, что этот пост будет полезен для тех, кто хочет использовать altair с данными из локальных или удаленных файлов csv, json.
import altair as alt
import pandas as pd
import numpy as np
time = np.array([
'2017-04-05 09:15:00',
'2017-04-05 09:30:00',
'2017-04-05 09:45:00',
'2017-04-05 10:00:00',
'2017-04-05 10:15:00',
'2017-04-05 10:30:00',
'2017-04-05 10:45:00',
'2017-04-05 11:00:00',
'2017-04-05 11:15:00',
'2017-04-05 11:30:00',
])
wl1 = np.array([
103448.0,
114730.0,
117252.0,
115569.0,
117504.0,
116123.0,
111050.0,
111221.0,
111604.0,
113026.0,
])
wl2 = np.array([
100776.0,
113206.0,
114189.0,
111300.0,
114956.0,
112637.0,
106342.0,
108409.0,
106853.0,
108071.0,
])
wl3 = np.array([
71581.1,
68600.1,
68208.5,
67454.7,
68709.9,
66210.9,
61699.3,
66124.6,
66950.5,
68222.2,
])
wl4 = np.array([
81118.2,
78322.2,
77261.0,
75347.4,
76345.1,
74544.4,
70165.2,
74842.1,
75782.9,
77848.0,
])
df = pd.DataFrame({'time': time, "wl1": wl1, "wl2": wl2, "wl3": wl3, "wl4": wl4})
df = df.melt('time') # Unpivot df with 'time' as identifier
# Save the data into csv and json format and upload them to a public website
lcsv = './timeseries.csv'
ljson = './timeseries.json'
rcsv = 'https://raw.githubusercontent.com/yoonghm/data/master/timeseries.csv'
rjson = 'https://raw.githubusercontent.com/yoonghm/data/master/timeseries.json'
df.to_csv(lcsv, index=False) # Remove index
df.to_json(ljson, orient='records') # In records orietation
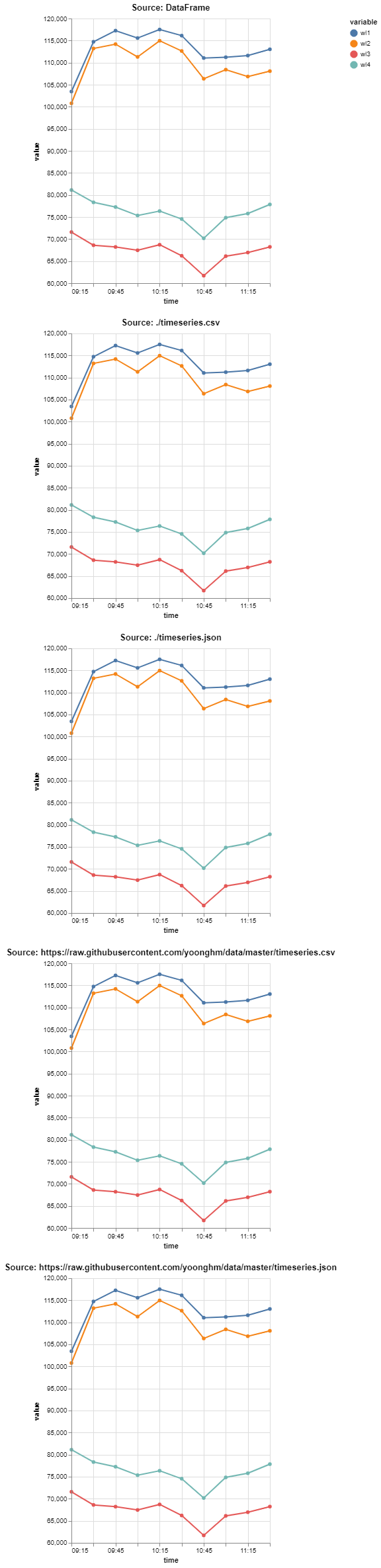
def plot_line(data, source=str(data)):
return (
alt.Chart(data, title='Source: ' + source).mark_line(point=True).encode(
x=alt.X('time:T', scale=alt.Scale(zero=False)),
y=alt.Y('value:Q', scale=alt.Scale(zero=False)),
color='variable:N',
tooltip=['time:T', 'value:Q']
).properties(
width=300, height=400
)
)
a = plot_line(df, source='DataFrame')
b = plot_line(lcsv, lcsv)
c = plot_line(ljson, ljson)
d = plot_line(rcsv, rcsv)
e = plot_line(rjson, rjson)
a & b & c & d & e
После создания графика vega-lite вы можете использовать vega-lite для обработки потоковых данных, как показано в этом посте и этом посте.