Что такое принцип обращения зависимостей и почему он важен?
Что такое принцип обращения зависимостей и почему он важен?
20 ответов
Проверьте этот документ: Принцип инверсии зависимостей.
Это в основном говорит:
- Модули высокого уровня не должны зависеть от модулей низкого уровня. Оба должны зависеть от абстракций.
- Абстракции никогда не должны зависеть от деталей. Детали должны зависеть от абстракций.
Что касается того, почему это важно, вкратце: изменения рискованны, и, полагаясь на концепцию, а не на реализацию, вы уменьшаете потребность в изменениях на сайтах вызовов.
По сути, DIP уменьшает связь между различными частями кода. Идея состоит в том, что хотя существует множество способов реализации, скажем, средства ведения журнала, способ его использования должен быть относительно стабильным во времени. Если вы можете извлечь интерфейс, который представляет концепцию ведения журнала, этот интерфейс должен быть гораздо более стабильным во времени, чем его реализация, и на сайты вызовов должно быть значительно меньше под влиянием изменений, которые вы могли бы внести при поддержке или расширении этого механизма ведения журнала.
Также делая зависимость реализации от интерфейса, вы получаете возможность выбирать во время выполнения, какая реализация лучше подходит для вашей конкретной среды. В зависимости от случаев это тоже может быть интересно.
Книги Agile Software Development, Принципы, Шаблоны и Практики и Agile Принципы, Шаблоны и Практики в C# являются лучшими ресурсами для полного понимания первоначальных целей и мотиваций, лежащих в основе Принципа инверсии зависимости. Статья "Принцип обращения зависимостей" также является хорошим ресурсом, но из-за того, что она является сжатой версией черновика, который в конечном итоге попал в ранее упомянутые книги, она оставляет некоторые важные дискуссии о концепции владение пакетами и интерфейсами, которые являются ключевыми для отличия этого принципа от более общего совета "программировать для интерфейса, а не реализации", который можно найти в книге "Шаблоны проектирования" (Gamma, et al.).
Для краткого изложения принцип инверсии зависимостей в первую очередь направлен на изменение традиционного направления зависимостей от компонентов "более высокого уровня" к компонентам "более низкого уровня", так что компоненты "более низкого уровня" зависят от интерфейсов, принадлежащих компонентам "более высокого уровня", (Примечание. Компонент "более высокого уровня" здесь относится к компоненту, требующему внешних зависимостей / сервисов, а не обязательно к его концептуальному положению в многоуровневой архитектуре.) При этом связь не уменьшается настолько, насколько она смещается от компонентов, которые теоретически менее ценным для компонентов, которые теоретически более ценны.
Это достигается путем разработки компонентов, чьи внешние зависимости выражаются в виде интерфейса, для которого потребитель компонента должен предоставить реализацию. Другими словами, определенные интерфейсы выражают то, что нужно компоненту, а не то, как вы используете компонент (например, "INeedSomething", а не "IDoSomething").
То, на что не ссылается Принцип обращения зависимостей, - это простая практика абстрагирования зависимостей с помощью интерфейсов (например, MyService → [ILogger ⇐ Logger]). Хотя это отделяет компонент от конкретной детали реализации зависимости, оно не инвертирует отношения между потребителем и зависимостью (например, [MyService → IMyServiceLogger] ⇐ Logger.
Важность принципа инверсии зависимости может быть сведена к единственной цели - возможности повторно использовать программные компоненты, которые полагаются на внешние зависимости для части их функциональных возможностей (регистрация, проверка и т. Д.)
В рамках этой общей цели повторного использования мы можем выделить два подтипа повторного использования:
Использование программного компонента в нескольких приложениях с реализациями зависимостей (например, вы разработали DI-контейнер и хотите обеспечить ведение журналов, но не хотите связывать свой контейнер с определенным регистратором, так что каждый, кто использует ваш контейнер, должен также использовать выбранную вами библиотеку журналов).
Использование программных компонентов в развивающемся контексте (например, вы разработали компоненты бизнес-логики, которые остаются неизменными в разных версиях приложения, где детали реализации развиваются).
В первом случае повторного использования компонентов в нескольких приложениях, например, с библиотекой инфраструктуры, цель состоит в том, чтобы предоставить потребителям базовую инфраструктуру без привязки ваших потребителей к зависимостям вашей собственной библиотеки, поскольку для получения зависимостей от таких зависимостей требуется потребителям также требуются такие же зависимости. Это может быть проблематично, когда потребители вашей библиотеки решают использовать другую библиотеку для тех же потребностей инфраструктуры (например, NLog и log4net), или если они решают использовать более позднюю версию требуемой библиотеки, которая не имеет обратной совместимости с версией требуется вашей библиотекой.
Во втором случае повторного использования компонентов бизнес-логики (т. Е. "Компонентов более высокого уровня") цель состоит в том, чтобы изолировать реализацию приложения в основной области от меняющихся потребностей ваших деталей реализации (например, изменение / обновление постоянных библиотек, библиотек обмена сообщениями). стратегии шифрования и т. д.). В идеале, изменение деталей реализации приложения не должно нарушать компоненты, инкапсулирующие бизнес-логику приложения.
Примечание. Некоторые могут возражать против описания этого второго случая как фактического повторного использования, полагая, что такие компоненты, как компоненты бизнес-логики, используемые в одном развивающемся приложении, представляют собой только одно использование. Идея, однако, заключается в том, что каждое изменение в деталях реализации приложения отображает новый контекст и, следовательно, другой вариант использования, хотя конечные цели можно отличить как изоляция и переносимость.
Хотя следование принципу инверсии зависимости во втором случае может принести некоторую пользу, следует отметить, что его значение применительно к современным языкам, таким как Java и C#, значительно снижено, возможно, до такой степени, что оно не имеет значения. Как обсуждалось ранее, DIP включает в себя полное разделение деталей реализации на отдельные пакеты. В случае развивающегося приложения, однако, простое использование интерфейсов, определенных в терминах бизнес-области, защитит от необходимости модифицировать компоненты более высокого уровня из-за меняющихся потребностей компонентов детализации реализации, даже если детали реализации в конечном счете будут находиться в одном и том же пакете. Эта часть принципа отражает аспекты, которые имели отношение к языку в момент его кодификации (т. Е. C++), которые не имеют отношения к более новым языкам. Тем не менее, важность Принципа инверсии зависимости прежде всего связана с разработкой повторно используемых программных компонентов / библиотек.
Более подробное обсуждение этого принципа, поскольку оно касается простого использования интерфейсов, внедрения зависимостей и шаблона разделенного интерфейса, можно найти здесь.
Эффективное применение инверсии зависимостей дает гибкость и стабильность на уровне всей архитектуры вашего приложения. Это позволит вашему приложению развиваться более безопасно и стабильно.
Традиционная многоуровневая архитектура
Традиционно пользовательский интерфейс многоуровневой архитектуры зависел от бизнес-уровня, а это, в свою очередь, зависело от уровня доступа к данным.
http://xurxodev.com/content/images/2016/02/Traditional-Layered.png
Вы должны понимать слой, пакет или библиотеку. Посмотрим, как будет выглядеть код.
У нас была бы библиотека или пакет для слоя доступа к данным.
// DataAccessLayer.dll
public class ProductDAO {
}
И другая бизнес-логика уровня библиотеки или пакета, которая зависит от уровня доступа к данным.
// BusinessLogicLayer.dll
using DataAccessLayer;
public class ProductBO {
private ProductDAO productDAO;
}
Многоуровневая архитектура с инверсией зависимостей
Инверсия зависимости указывает на следующее:
Модули высокого уровня не должны зависеть от модулей низкого уровня. Оба должны зависеть от абстракций.
Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Что такое модули высокого уровня и низкого уровня? Мышление модулей, таких как библиотеки или пакеты, высокоуровневыми модулями будут те, которые традиционно имеют зависимости и имеют низкий уровень, от которого они зависят.
Другими словами, высокий уровень модуля - это место, где вызывается действие, и низкий уровень, где оно выполняется.
Из этого принципа можно сделать разумный вывод: между конкрециями не должно быть никакой зависимости, но должна быть зависимость от абстракции. Но в соответствии с подходом, который мы используем, мы можем неправильно использовать зависимость от инвестиций, но это абстракция.
Представьте, что мы адаптируем наш код следующим образом:
У нас была бы библиотека или пакет для уровня доступа к данным, который определяет абстракцию.
// DataAccessLayer.dll
public interface IProductDAO
public class ProductDAO : IProductDAO{
}
И другая бизнес-логика уровня библиотеки или пакета, которая зависит от уровня доступа к данным.
// BusinessLogicLayer.dll
using DataAccessLayer;
public class ProductBO {
private IProductDAO productDAO;
}
Хотя мы зависим от абстракции, зависимость между бизнесом и доступом к данным остается неизменной.
http://xurxodev.com/content/images/2016/02/Traditional-Layered.png
Чтобы получить инверсию зависимостей, интерфейс персистентности должен быть определен в модуле или пакете, где находится логика или домен высокого уровня, а не в модуле низкого уровня.
Сначала определите, что такое уровень домена, и абстракция его связи определяется постоянством.
// Domain.dll
public interface IProductRepository;
using DataAccessLayer;
public class ProductBO {
private IProductRepository productRepository;
}
После того, как уровень постоянства зависит от домена, теперь можно инвертировать, если определена зависимость.
// Persistence.dll
public class ProductDAO : IProductRepository{
}
http://xurxodev.com/content/images/2016/02/Dependency-Inversion-Layers.png
Углубление принципа
Важно хорошо усвоить концепцию, углубляя цель и выгоды. Если мы останемся в механике и изучим типичный репозиторий, мы не сможем определить, где мы можем применить принцип зависимости.
Но почему мы инвертируем зависимость? Какова основная цель за пределами конкретных примеров?
Такое обычно позволяет наиболее стабильным вещам, которые не зависят от менее стабильных вещей, меняться чаще.
Тип персистентности легче изменить, либо база данных или технология для доступа к той же базе данных, чем логика домена или действия, предназначенные для связи с постоянством. Из-за этого зависимость меняется на противоположную, потому что легче изменить постоянство, если это изменение произойдет. Таким образом, нам не придется менять домен. Доменный слой является наиболее стабильным из всех, поэтому он не должен зависеть ни от чего.
Но есть не только этот пример хранилища. Существует много сценариев, в которых применяется этот принцип, и существуют архитектуры, основанные на этом принципе.
архитектуры
Существуют архитектуры, в которых инверсия зависимостей является ключом к ее определению. Во всех доменах это наиболее важно, и именно абстракции будут указывать протокол связи между доменом и остальными пакетами или библиотеками.
Чистая Архитектура
В чистой архитектуре домен расположен в центре, и если вы посмотрите в направлении стрелок, указывающих на зависимость, станет ясно, какие слои являются наиболее важными и стабильными. Наружные слои считаются нестабильными инструментами, поэтому избегайте зависимости от них.

Шестиугольная архитектура
То же самое происходит с гексагональной архитектурой, где домен также расположен в центральной части, а порты являются абстракциями коммуникации от внешнего мира домино. Здесь снова очевидно, что область является наиболее устойчивой и традиционная зависимость является инвертированной.

Когда мы разрабатываем программные приложения, мы можем рассматривать классы низкого уровня, классы, которые реализуют базовые и основные операции (доступ к диску, сетевые протоколы,...), а классы высокого уровня - классы, которые инкапсулируют сложную логику (бизнес-потоки,...).
Последние полагаются на классы низкого уровня. Естественным способом реализации таких структур было бы написание низкоуровневых классов и, как только мы их получили, написание сложных высокоуровневых классов. Поскольку классы высокого уровня определяются в терминах других, это кажется логичным способом сделать это. Но это не гибкий дизайн. Что произойдет, если нам нужно заменить класс низкого уровня?
Принцип обращения зависимостей гласит:
- Модули высокого уровня не должны зависеть от модулей низкого уровня. Оба должны зависеть от абстракций.
- Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Этот принцип стремится "перевернуть" традиционное представление о том, что модули высокого уровня в программном обеспечении должны зависеть от модулей более низкого уровня. Здесь высокоуровневые модули владеют абстракцией (например, выбирая методы интерфейса), которые реализуются низкоуровневыми модулями. Таким образом, делая модули более низкого уровня зависимыми от модулей более высокого уровня.
В основном это говорит:
Класс должен зависеть от абстракций (например, интерфейса, абстрактных классов), а не от конкретных деталей (реализаций).
Для меня Принцип инверсии зависимостей, описанный в официальной статье, на самом деле является ошибочной попыткой увеличить возможность повторного использования модулей, которые по своей природе менее пригодны для повторного использования, а также способом обойти проблему в языке C++.
Проблема в C++ состоит в том, что заголовочные файлы обычно содержат объявления закрытых полей и методов. Следовательно, если модуль C++ высокого уровня включает файл заголовка для модуля низкого уровня, это будет зависеть от фактических деталей реализации этого модуля. И это, очевидно, не очень хорошая вещь. Но это не проблема в более современных языках, обычно используемых сегодня.
Модули высокого уровня по своей природе менее пригодны для повторного использования, чем модули низкого уровня, поскольку первые обычно более специфичны для приложения / контекста, чем последние. Например, компонент, который реализует экран пользовательского интерфейса, имеет самый высокий уровень и также очень (полностью?) Специфичен для приложения. Попытка повторно использовать такой компонент в другом приложении неэффективна и может привести только к чрезмерному проектированию.
Таким образом, создание отдельной абстракции на том же уровне компонента A, который зависит от компонента B (который не зависит от A), может быть выполнено только в том случае, если компонент A действительно будет полезен для повторного использования в различных приложениях или контекстах. Если это не так, то применение DIP будет плохим дизайном.
Гораздо более ясный способ сформулировать принцип обращения зависимостей:
Ваши модули, которые инкапсулируют сложную бизнес-логику, не должны напрямую зависеть от других модулей, которые инкапсулируют бизнес-логику. Вместо этого они должны зависеть только от интерфейсов для простых данных.
Т.е. вместо реализации вашего класса Logic как обычно делают люди:
class Dependency { ... }
class Logic {
private Dependency dep;
int doSomething() {
// Business logic using dep here
}
}
Вы должны сделать что-то вроде:
class Dependency { ... }
interface Data { ... }
class DataFromDependency implements Data {
private Dependency dep;
...
}
class Logic {
int doSomething(Data data) {
// compute something with data
}
}
Data а также DataFromDependency должен жить в том же модуле, что и Logic, не с Dependency,
Зачем это делать?
- Два модуля бизнес-логики теперь разъединены. когда
Dependencyизменения, вам не нужно менятьLogic, - Понимание того, что
Logicdo - гораздо более простая задача: она работает только с тем, что выглядит как ADT. Logicтеперь можно легче тестировать. Теперь вы можете напрямую создать экземплярDataс поддельными данными и передать их. Нет необходимости в издевательствах или сложных испытательных лесах.
Хорошие ответы и хорошие примеры уже даны здесь другими.
Причина, по которой DIP важен, заключается в том, что он обеспечивает ОО-принцип "слабо связанной конструкции".
Объекты в вашем программном обеспечении НЕ должны попадать в иерархию, где некоторые объекты являются объектами верхнего уровня, в зависимости от объектов низкого уровня. Изменения в объектах нижнего уровня будут затем распространяться на ваши объекты верхнего уровня, что делает программное обеспечение очень хрупким для изменений.
Вы хотите, чтобы ваши объекты "верхнего уровня" были очень стабильными и не хрупкими для изменений, поэтому вам нужно инвертировать зависимости.
Инверсия управления (IoC) - это шаблон проектирования, в котором объект получает свою зависимость от внешней структуры, а не запрашивает структуру для своей зависимости.
Пример псевдокода с использованием традиционного поиска:
class Service {
Database database;
init() {
database = FrameworkSingleton.getService("database");
}
}
Аналогичный код с использованием IoC:
class Service {
Database database;
init(database) {
this.database = database;
}
}
Преимущества IoC:
- У вас нет зависимости от центральной структуры, поэтому при желании это можно изменить.
- Поскольку объекты создаются путем внедрения, предпочтительно с использованием интерфейсов, легко создавать модульные тесты, которые заменяют зависимости фиктивными версиями.
- Развязка кода.
Принцип инверсии зависимостей
DIP является частью SOLID <sup>[About],</sup> который является частью OOD и был представлен дядей Бобом. Речь идет о слабой связи между классами (слоями ...)
Обычный сценарий
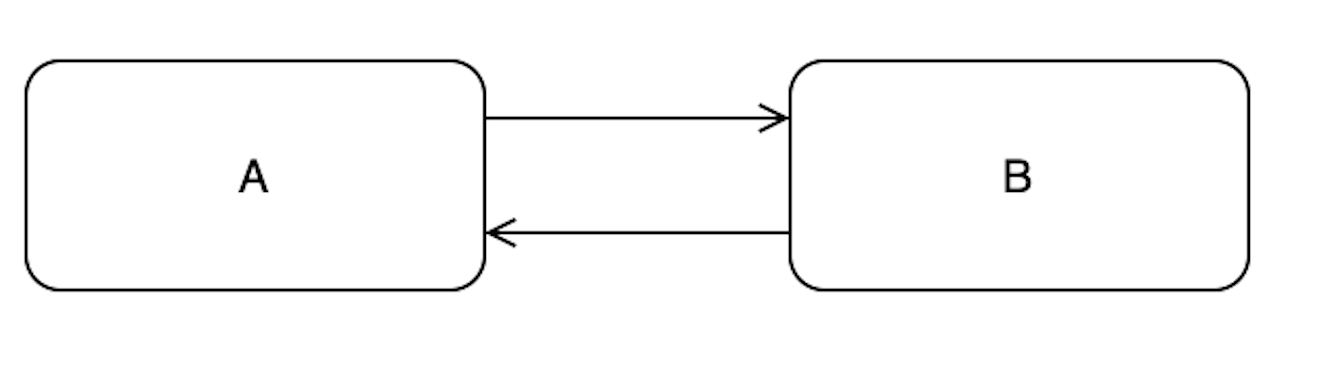
Принцип инверсии зависимостей предлагает
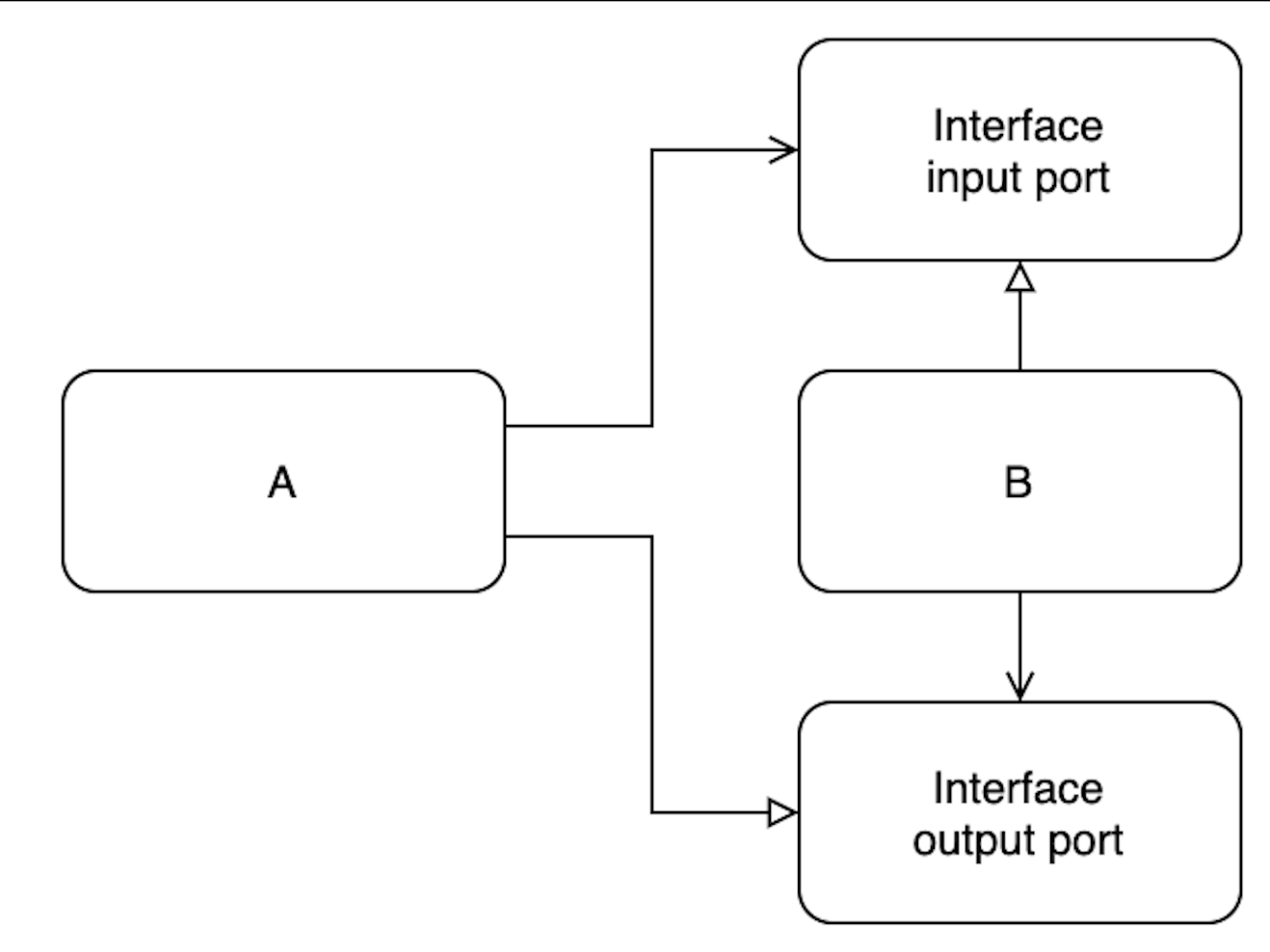
Псевдокод:
interface InterfaceInputPort {
func input()
}
interface InterfaceOutputPort {
func output()
}
class A: InterfaceOutputPort {
let inputPort = B(outputPort: self)
func output() {
print("output")
}
}
class B: InterfaceInputPort {
let outputPort: InterfaceOutputPort
init(outputPort: InterfaceOutputPort) {
self.outputPort = outputPort
}
func input() {
print("input")
}
}
Если мы можем принять как данность, что сотруднику "высокого уровня" в корпорации платят за выполнение его планов и что эти планы реализуются путем совокупного выполнения планов многих сотрудников "низкого уровня", то мы могли бы сказать Как правило, это ужасный план, если описание плана сотрудника высокого уровня каким-либо образом связано с конкретным планом любого сотрудника более низкого уровня.
Если у руководителя высокого уровня есть план "улучшить время доставки" и он указывает, что служащий судоходной линии должен пить кофе и делать растяжки каждое утро, то этот план сильно связан и имеет низкую сплоченность. Но если в плане не упоминается какой-либо конкретный сотрудник, а на самом деле просто требуется, чтобы "субъект, который может выполнять работу, готов к работе", тогда план слабо связан и более согласован: планы не пересекаются и могут быть легко заменены. Подрядчики или роботы могут легко заменить сотрудников, и план высокого уровня остается неизменным.
"Высокий уровень" в принципе инверсии зависимостей означает "более важный".
Инверсия Контейнеров Контроля и паттерн Внедрения Зависимостей Мартина Фаулера тоже хорошо читаются. Я нашел Head First Design Patterns отличной книгой для моей первой попытки изучить DI и другие шаблоны.
Точка инверсии зависимостей заключается в создании программного обеспечения многократного использования.
Идея состоит в том, что вместо двух частей кода, полагающихся друг на друга, они полагаются на какой-то абстрактный интерфейс. Тогда вы можете повторно использовать любой кусок без другого.
Чаще всего это достигается путем использования контейнера инвертирования управления (IoC), такого как Spring в Java. В этой модели свойства объектов устанавливаются через конфигурацию XML вместо того, чтобы объекты выходили и находили свою зависимость.
Представьте себе этот псевдокод...
public class MyClass
{
public Service myService = ServiceLocator.service;
}
MyClass напрямую зависит как от класса Service, так и от класса ServiceLocator. Это нужно обоим, если вы хотите использовать его в другом приложении. Теперь представьте это...
public class MyClass
{
public IService myService;
}
Теперь MyClass использует единый интерфейс - интерфейс IService. Мы бы позволили контейнеру IoC фактически установить значение этой переменной.
Так что теперь MyClass можно легко использовать в других проектах, не добавляя зависимости двух других классов вместе с ним.
Более того, вам не нужно перетаскивать зависимости MyService, и зависимости этих зависимостей, и... ну, вы поняли идею.
В дополнение к другим ответам....
Позвольте мне привести пример в первую очередь..
Пусть будет гостиница, которая попросит у производителя продуктов питания его запасы. Отель дает название еды (скажем, курицу) Генератору еды, и Генератор возвращает запрашиваемую еду в гостиницу. Но отель не заботится о типе пищи, которую он получает и подает. Таким образом, Генератор поставляет продукты с этикеткой "Еда" в отель.
Эта реализация в JAVA
FactoryClass с фабричным методом. Пищевой Генератор
public class FoodGenerator {
Food food;
public Food getFood(String name){
if(name.equals("fish")){
food = new Fish();
}else if(name.equals("chicken")){
food = new Chicken();
}else food = null;
return food;
}
}
Класс Аннотация / Интерфейс
public abstract class Food {
//None of the child class will override this method to ensure quality...
public void quality(){
String fresh = "This is a fresh " + getName();
String tasty = "This is a tasty " + getName();
System.out.println(fresh);
System.out.println(tasty);
}
public abstract String getName();
}
Курица реализует Еду (Конкретный Класс)
public class Chicken extends Food {
/*All the food types are required to be fresh and tasty so
* They won't be overriding the super class method "property()"*/
public String getName(){
return "Chicken";
}
}
Рыба реализует Пищу (Конкретный Класс)
public class Fish extends Food {
/*All the food types are required to be fresh and tasty so
* They won't be overriding the super class method "property()"*/
public String getName(){
return "Fish";
}
}
в заключение
Отель
public class Hotel {
public static void main(String args[]){
//Using a Factory class....
FoodGenerator foodGenerator = new FoodGenerator();
//A factory method to instantiate the foods...
Food food = foodGenerator.getFood("chicken");
food.quality();
}
}
Как вы могли видеть, отель не знает, является ли это курицей или рыбой. Известно только, что это объект питания, т. Е. Отель зависит от класса питания.
Также вы могли бы заметить, что класс Fish and Chicken реализует класс Food и не связан напрямую с отелем. т.е. курица и рыба также зависит от класса продуктов питания.
Это означает, что компонент высокого уровня (гостиница) и компонент низкого уровня (рыба и курица) зависят от абстракции (еда).
Это называется инверсией зависимости.
Я думаю, что у меня есть намного лучший (более интуитивный) пример.
- Представьте себе систему (веб-приложение) с сотрудником и управлением контактами (два экрана).
- Они не совсем связаны друг с другом, поэтому вы хотите, чтобы они были в отдельном модуле / папке.
Таким образом, у вас будет некоторая "основная" точка входа, которая должна знать как о модуле управления сотрудниками, так и о модуле управления контактами, и она должна будет предоставлять ссылки в навигации и принимать запросы API и т. Д. Другими словами, основной модуль будет зависеть на этих двоих - он будет знать об их контроллерах, маршрутах и ссылках, которые должны отображаться в (общей) навигации.
Пример Node.js
// main.js
import express from 'express'
// two modules, each having many exports
import { api as contactsApi, navigation as cNav } from './contacts/'
import { api as employeesApi, navigation as eNav } from './employees/'
const api = express()
const navigation = {
...cNav,
...eNav
}
api.use('contacts', contactsApi)
api.use('employees', employeesApi)
// do something with navigation, possibly do some other setup
Кроме того, обратите внимание, что есть случаи (простые), когда это совершенно нормально.
Таким образом, со временем это приведет к тому, что добавлять новые модули не так просто. Вы должны помнить, чтобы зарегистрировать API, навигацию, возможно разрешения, и этот main.js становится все больше и больше.
И вот тут возникает инверсия зависимости. Вместо того, чтобы ваш основной модуль зависел от всех других модулей, вы введете некоторое "ядро" и заставите каждый модуль регистрироваться сам.
Таким образом, в данном случае речь идет о представлении некоторого ApplicationModule, который может подчиняться многим службам (маршрутам, навигации, разрешениям), а основной модуль может оставаться простым (просто импортируйте модуль и дайте ему установить).
Другими словами, речь идет о создании подключаемой архитектуры. Это дополнительная работа и код, который вы должны будете писать / читать и поддерживать, поэтому вы должны делать это не сразу, а когда у вас такой запах.
Что особенно интересно, вы можете сделать что-нибудь плагином, даже слой персистентности - что может быть полезно, если вам нужно поддерживать много реализаций персистентности, но обычно это не так. Посмотрите другой ответ для изображения с гексагональной архитектурой, он отлично подходит для иллюстрации - здесь есть ядро, а все остальное по сути является плагином.
Инверсия зависимостей: зависит от абстракций, а не от конкреций.
Инверсия управления: главное против абстракции и то, как главное - это клей систем.

Вот несколько хороших постов, рассказывающих об этом:
https://coderstower.com/2019/03/26/dependency-inversion-why-you-shouldnt-avoid-it/
https://coderstower.com/2019/04/02/main-and-abstraction-the-decoupled-peers/
https://coderstower.com/2019/04/09/inversion-of-control-putting-all-together/
В дополнение к шквалу хороших ответов, я хотел бы добавить крошечный собственный пример, чтобы продемонстрировать хорошие и плохие практики. И да, я не из тех, кто бросает камни!
Скажем, вы хотите, чтобы небольшая программа преобразовывала строку в формат base64 через консольный ввод-вывод. Вот наивный подход:
class Program
{
static void Main(string[] args)
{
/*
* BadEncoder: High-level class *contains* low-level I/O functionality.
* Hence, you'll have to fiddle with BadEncoder whenever you want to change
* the I/O mode or details. Not good. A good encoder should be I/O-agnostic --
* problems with I/O shouldn't break the encoder!
*/
BadEncoder.Run();
}
}
public static class BadEncoder
{
public static void Run()
{
Console.WriteLine(Convert.ToBase64String(Encoding.UTF8.GetBytes(Console.ReadLine())));
}
}
DIP в основном говорит, что высокоуровневые компоненты не должны зависеть от низкоуровневой реализации, где "уровень" - это расстояние от ввода-вывода согласно Роберту К. Мартину ("Чистая архитектура"). Но как выйти из этого затруднительного положения? Просто сделав центральный кодировщик зависимым только от интерфейсов, не беспокоясь о том, как они реализованы:
class Program
{
static void Main(string[] args)
{
/* Demo of the Dependency Inversion Principle (= "High-level functionality
* should not depend upon low-level implementations"):
* You can easily implement new I/O methods like
* ConsoleReader, ConsoleWriter without ever touching the high-level
* Encoder class!!!
*/
GoodEncoder.Run(new ConsoleReader(), new ConsoleWriter()); }
}
public static class GoodEncoder
{
public static void Run(IReadable input, IWriteable output)
{
output.WriteOutput(Convert.ToBase64String(Encoding.ASCII.GetBytes(input.ReadInput())));
}
}
public interface IReadable
{
string ReadInput();
}
public interface IWriteable
{
void WriteOutput(string txt);
}
public class ConsoleReader : IReadable
{
public string ReadInput()
{
return Console.ReadLine();
}
}
public class ConsoleWriter : IWriteable
{
public void WriteOutput(string txt)
{
Console.WriteLine(txt);
}
}
Обратите внимание, что вам не нужно прикасаться GoodEncoderчтобы изменить режим ввода-вывода - этот класс доволен интерфейсами ввода-вывода, которые он знает; любая реализация на низком уровнеIReadable а также IWriteable никогда не побеспокоит это.
Я вижу, что в ответах выше было дано хорошее объяснение. Однако я хочу дать простое объяснение на простом примере.
Принцип инверсии зависимостей позволяет программисту удалять жестко запрограммированные зависимости, так что приложение становится слабосвязанным и расширяемым.
Как этого добиться: с помощью абстракции
Без инверсии зависимостей:
class Student {
private Address address;
public Student() {
this.address = new Address();
}
}
class Address{
private String perminentAddress;
private String currentAdrress;
public Address() {
}
}
В приведенном выше фрагменте кода адресный объект жестко запрограммирован. Вместо этого, если мы можем использовать инверсию зависимостей и внедрить объект адреса, передав метод конструктора или установщика. Давайте посмотрим.
С инверсией зависимостей:
class Student{
private Address address;
public Student(Address address) {
this.address = address;
}
//or
public void setAddress(Address address) {
this.address = address;
}
}
Допустим, у нас есть два класса: Engineer а также Programmer:
Инженер классов зависит от класса программиста, как показано ниже:
class Engineer () {
fun startWork(programmer: Programmer){
programmer.work()
}
}
class Programmer {
fun work(){
//TODO Do some work here!
}
}
В этом примере класса Engineer зависит от наших Programmerкласс. Что будет, если мне нужно будет изменитьProgrammer?
Очевидно, мне нужно изменить Engineerслишком. (Вау, в этот моментOCP тоже нарушается)
Тогда что мы должны навести порядок в этом беспорядке? На самом деле ответ - абстракция. Путем абстракции мы можем удалить зависимость между этими двумя классами. Например, я могу создатьInterface для класса Programmer и с этого момента каждый класс, который хочет использовать Programmer должен использовать свой Interface, Затем, изменив класс Programmer, нам не нужно изменять какие-либо классы, которые его использовали, из-за абстракции, которую мы использовали.
Заметка: DependencyInjection может помочь нам сделать DIP а также SRP слишком.
Принцип инверсии зависимости (DIP) гласит, что
i) Модули высокого уровня не должны зависеть от модулей низкого уровня. Оба должны зависеть от абстракций.
ii) Абстракции никогда не должны зависеть от деталей. Детали должны зависеть от абстракций.
Пример:
public interface ICustomer
{
string GetCustomerNameById(int id);
}
public class Customer : ICustomer
{
//ctor
public Customer(){}
public string GetCustomerNameById(int id)
{
return "Dummy Customer Name";
}
}
public class CustomerFactory
{
public static ICustomer GetCustomerData()
{
return new Customer();
}
}
public class CustomerBLL
{
ICustomer _customer;
public CustomerBLL()
{
_customer = CustomerFactory.GetCustomerData();
}
public string GetCustomerNameById(int id)
{
return _customer.GetCustomerNameById(id);
}
}
public class Program
{
static void Main()
{
CustomerBLL customerBLL = new CustomerBLL();
int customerId = 25;
string customerName = customerBLL.GetCustomerNameById(customerId);
Console.WriteLine(customerName);
Console.ReadKey();
}
}
Примечание. Класс должен зависеть от абстракций, таких как интерфейс или абстрактные классы, а не от конкретных деталей (реализация интерфейса).