Добавьте Jar в автономный pyspark
Я запускаю программу pyspark:
$ export SPARK_HOME=
$ export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.9-src.zip
$ python
И код py:
from pyspark import SparkContext, SparkConf
SparkConf().setAppName("Example").setMaster("local[2]")
sc = SparkContext(conf=conf)
Как добавить jar-зависимости, такие как databricks csv jar? Используя командную строку, я могу добавить пакет следующим образом:
$ pyspark/spark-submit --packages com.databricks:spark-csv_2.10:1.3.0
Но я не использую ничего из этого. Программа является частью более крупного рабочего процесса, в котором не используется spark-submit. Я должен иметь возможность запускать свою программу./foo.py, и она должна просто работать.
- Я знаю, что вы можете установить свойства spark для extraClassPath, но вам нужно копировать JAR-файлы на каждый узел?
- Попробовал conf.set("spark.jars", "jar1,jar2"), который тоже не работал с исключением pyFj CNF
7 ответов
Здесь есть много подходов (установка ENV-переменных, добавление в $SPARK_HOME/conf/spark-defaults.conf и т. Д.), Некоторые ответы уже охватывают их. Я хотел добавить дополнительный ответ для тех, кто специально использует Jupyter Notebooks и создает сеанс Spark из записной книжки. Вот решение, которое работает лучше всего для меня (в моем случае я хотел загрузить пакет Kafka):
spark = SparkSession.builder.appName('my_awesome')\
.config('spark.jars.packages', 'org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0')\
.getOrCreate()
Используя эту строку кода, мне больше ничего не нужно было делать (никаких ENV или изменений в conf-файле).
Любые зависимости могут быть переданы с помощью spark.jars.packages (настройка spark.jars должен работать так же) недвижимость в $SPARK_HOME/conf/spark-defaults.conf, Это должен быть список координат через запятую.
И пакеты или свойства classpath должны быть установлены до запуска JVM, и это происходит во время SparkConf инициализация. Это означает, что SparkConf.set метод не может быть использован здесь.
Альтернативный подход заключается в установке PYSPARK_SUBMIT_ARGS переменная среды перед SparkConf объект инициализирован:
import os
from pyspark import SparkConf
SUBMIT_ARGS = "--packages com.databricks:spark-csv_2.11:1.2.0 pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS
conf = SparkConf()
sc = SparkContext(conf=conf)
Я столкнулся с похожей проблемой для другого jar ("Разъем MongoDB для Spark", mongo-spark-connector), но большая оговорка была в том, что я установил Spark с помощью pyspark в conda (conda install pyspark). Поэтому вся помощь для Spark конкретные ответы были не совсем полезны. Для тех из вас, кто устанавливает с conda вот процесс, который я собрал вместе:
1) Найдите, где ваш pyspark/jars расположены. Мои были на этом пути: ~/anaconda2/pkgs/pyspark-2.3.0-py27_0/lib/python2.7/site-packages/pyspark/jars,
2) Скачать jar файл в путь, найденный в шаге 1, из этого места.
3) Теперь вы сможете запустить что-то вроде этого (код взят из официального руководства MongoDB, используя ответ Брифорда Уайли выше):
from pyspark.sql import SparkSession
my_spark = SparkSession \
.builder \
.appName("myApp") \
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/spark.test_pyspark_mbd_conn") \
.config("spark.mongodb.output.uri", "mongodb://127.0.0.1:27017/spark.test_pyspark_mbd_conn") \
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.11:2.2.2') \
.getOrCreate()
Отказ от ответственности:
1) Я не знаю, является ли этот ответ правильным местом / ТАК вопрос, чтобы поставить это; пожалуйста, посоветуйте лучшее место, и я перенесу его.
2) Если вы считаете, что я допустил ошибку или у меня есть улучшения в вышеуказанном процессе, пожалуйста, прокомментируйте, и я пересмотрю.
Работая с PySpark, PostgreSQL и Apache Sedona, я научился решать это двумя способами .
Способ 1: Загрузите файл JAR и добавьте вspark.jars
Чтобы использовать PostgreSQL в Spark, мне нужно было добавить драйвер JDBC (файл JAR) в PySpark.
Сначала я создалjarsкаталог на том же уровне, что и моя программа, и сохранитьpostgresql-42.5.0.jarфайл там.
Затем я просто добавляю эту конфигурацию в SparkSession с помощью:SparkSession.builder.config("spark.jars", "{JAR_FILE_PATH}")
spark = (
SparkSession.builder
.config("spark.jars", "jars/postgresql-42.5.0.jar")
.master("local[*]")
.appName("Example - Add a JAR file")
.getOrCreate()
)
Способ 2: используйте центральную координату Maven иspark.jars.packages
Если ваши JAR-файлы зависимостей доступны в Maven , вы можете использовать этот метод и не нужно поддерживать какой-либо JAR-файл .
Шаги
Найдите свой пакет в Maven Central RepositorySearch
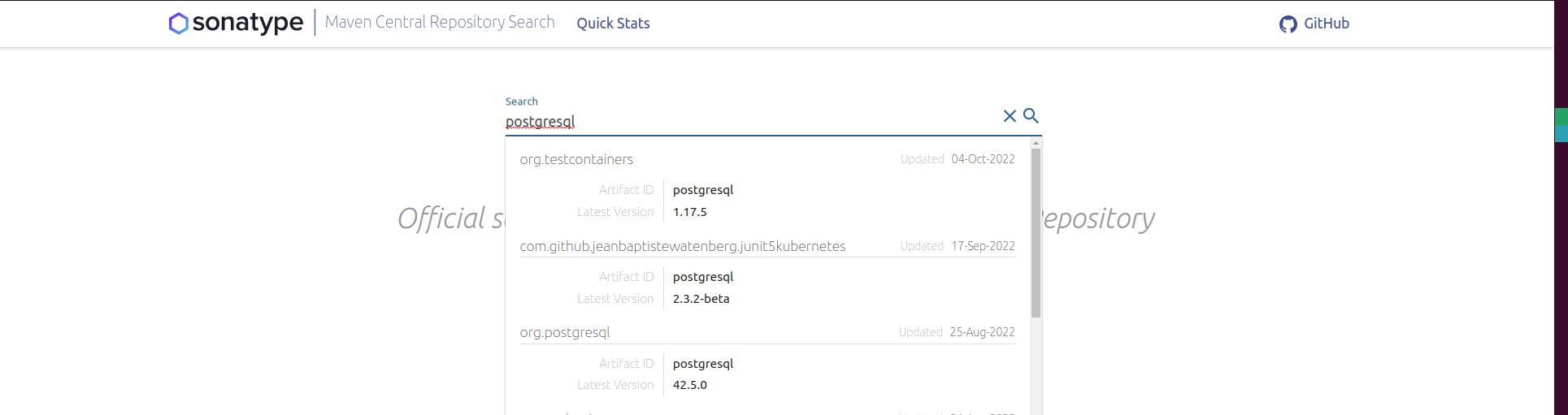
Выберите правильный артефакт пакета и скопируйте координату Maven Central.
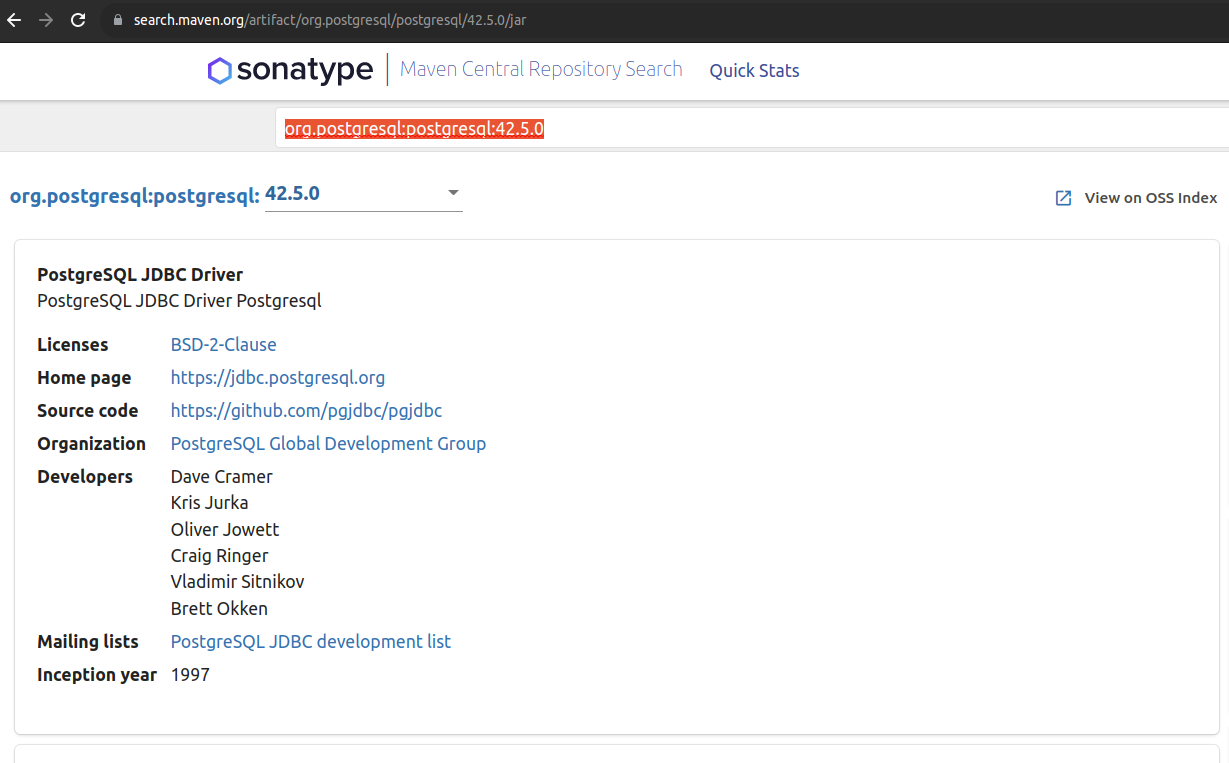
В Python вызовите
SparkSession.builder.config("spark.jars.packages", "{MAVEN_CENTRAL_COORDINATE}").spark = ( SparkSession.builder .appName('Example - adding many Maven packages') .config("spark.serializer", KryoSerializer.getName) .config("spark.kryo.registrator", SedonaKryoRegistrator.getName) .config("spark.jars.packages", "org.postgresql:postgresql:42.5.0," + "org.apache.sedona:sedona-python-adapter-3.0_2.12:1.2.1-incubating," + "org.datasyslab:geotools-wrapper:1.1.0-25.2") .getOrCreate() )
Плюсы использования
- Вы можете добавить несколько пакетов
- Вам не нужно управлять толстыми файлами JAR
Минусы использованияsparks.jars.packages
The .config("sparks.jars.packages", ...)принимать один параметр , поэтому для добавления нескольких пакетов необходимо сцепить координаты пакета с помощью,как разделитель.
"org.postgresql:postgresql:42.5.0,"
+ "org.apache.sedona:sedona-python-adapter-3.0_2.12:1.2.1-incubating,"
+ "org.datasyslab:geotools-wrapper:1.1.0-25.2"
*** Строка не допускает следующей строки , пробелов или табуляции в вашем коде, и это вызовет неприятные ошибки, которые выдают нерелевантные журналы ошибок.
Наконец-то нашел ответ после нескольких попыток. Ответ специфичен для использования spark-csv jar. Создайте на жестком диске папку, скажем, D:\Spark\spark_jars. Поместите туда следующие банки:
- spark-csv_2.10-1.4.0.jar (это версия, которую я использую)
- Обще-CSV-1.1.jar
- однозначность-парсеры-1.5.1.jar
2 и 3 - зависимости, необходимые для spark-csv, поэтому эти два файла также необходимо загрузить. Перейдите в каталог conf, где вы скачали Spark. В файле spark-defaults.conf добавьте строку:
spark.driver.extraClassPath D: / Spark / spark_jars / *
Звездочка должна включать все банки. Теперь запустите Python, создайте SparkContext, SQLContext, как обычно. Теперь вы должны быть в состоянии использовать spark-CSV в качестве
sqlContext.read.format('com.databricks.spark.csv').\
options(header='true', inferschema='true').\
load('foobar.csv')
import os
import sys
spark_home = os.environ.get('SPARK_HOME', None)
sys.path.insert(0, spark_home + "/python")
sys.path.insert(0, os.path.join(spark_home, 'python/lib/py4j-0.10.4-src.zip'))
Вот оно...
sys.path.insert(0, <PATH TO YOUR JAR>)
Затем...
import pyspark
import numpy as np
from pyspark import SparkContext
sc = SparkContext("local[1]")
.
.
.
Для искрового оператора в манифесте yml вы можете использовать в искровой конфигурации "spark.jars.packages" для нескольких пакетов.
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: test
namespace: default
spec:
type: Python
pythonVersion: "3"
mode: cluster
sparkVersion: "3.3.2"
sparkConf:
"spark.jars.packages": "org.apache.hadoop:hadoop-aws:3.3.2,com.amazonaws:aws-java-sdk-bundle:1.12.99"