Не создавать файл, когда источник имеет 0 строк
У меня есть ниже в области потока данных. Проблема, с которой я сталкиваюсь, заключается в том, что даже если результат равен 0, он все равно создает файл.
Кто-нибудь может увидеть, что я здесь делаю не так?
https://s tackru.com/images/30028e72d830528ed5f560d4edaebf8d222b1a44.png
https://s tackru.com/images/fb50b5c8f84beff87a3906d4ae1d62410dbe333c.png
https://s tackru.com/images/995e293f94ecd2c73b8bf6cbba30d00b186cc992.png
2 ответа
Это довольно ожидаемое и известное раздражающее поведение. Служба SSIS создаст пустой плоский файл, даже если он не отмечен: "имена столбцов в первой строке данных".
Обходные пути:
удалить такой файл задачей файловой системы, если
@RowCountWriteOff = 0только после выполнения потока данных.в качестве альтернативы, не запускайте поток данных, если ожидаемое количество строк в источнике равно 0:
Обновление 2019-02-11:
У меня есть проблема, что у меня есть 13 из этих команд экспорта в CSV в потоке данных, и это дорогостоящие запросы
- Тогда двойной запрос источника для проверки количества строк будет еще дороже и, возможно, лучше будет повторно использовать значение переменной @RowCountWriteOff.
- Первоначальный проект имеет 13 потоков данных, добавляя 13 ограничений и 13 задач файловой системы, основной поток управления сделает пакет более сложным и сложным в обслуживании
- Таким образом, предложение заключается в использовании
OnPostExecuteобработчик событий, поэтому логика очистки изолирована от некоторого определенного потока данных:
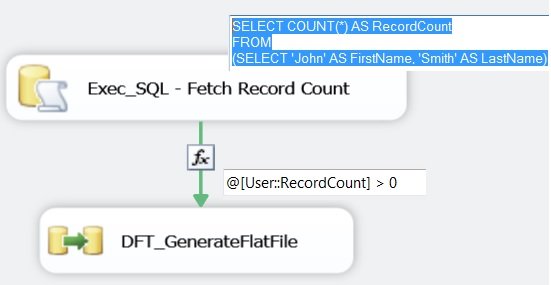
Обновление 1 - добавление более подробной информации на основе комментариев OP
Исходя из вашего комментария, я предполагаю, что вы хотите перебрать много таблиц с помощью команд SQL, проверить, содержит ли таблица строки, если это так, то вы должны экспортировать строки в плоские файлы, иначе вы должны игнорировать таблицы. Я упомяну шаги, которые вам нужны для этого, и предоставлю ссылки, которые содержат больше деталей для каждого шага.
- Сначала вы должны создать контейнер цикла по каждому элементу для циклического перемещения по таблицам.
- Вы должны добавить
Execute SQL Taskс командой подсчетаSELECT COunt(*) FROM ....)и сохранить Resultset внутри переменной - Добавьте задачу потока данных, которая импортирует данные из источника OLEDB в место назначения плоского файла.
- После этого вы должны добавить ограничение приоритета с выражением в задачу потока данных с выражением, аналогичным
@[User::RowCount] > 0
Кроме того, полезно проверить предоставленные мной ссылки, поскольку они содержат много полезной информации и пошаговые руководства.
Начальный ответ
Предотвращение создания пустых плоских файлов службами SSIS - это распространенная проблема, в Интернете можно найти множество ссылок, предлагается множество обходных путей и множество методов, которые могут решить эту проблему:
- Попробуйте установить
Data Flow TaskDelay Validationсобственность наTrue - Создать другой
Data Flow Taskвнутри пакета, который будет использоваться только для подсчета строк в источнике, если он больше, чем0тогда ограничение приоритета должно привести к другомуData Flow Task - Добавить
File System TaskпослеData Flow Taskкоторые удаляют выходной файл, если RowCounto, вы должны установить выражение ограничения приоритета, чтобы убедиться, что.
Рекомендации и полезные ссылки
- Как предотвратить создание пакета SSIS пустым плоским файлом в месте назначения
- Запретить SSIS создавать пустой плоский файл
- Устранение пустых выходных файлов в SSIS
- Запрет SSIS для создания пустого файла CSV в месте назначения
- Проверьте количество возвращаемых строк и не создавайте пустой файл назначения
- Установить
Data Flow TaskDelay Validationсобственность наTrue