Функция стоимости MSE для обучения нейронной сети
В онлайн-учебнике по нейронным сетям и глубокому обучению автор иллюстрирует основы нейронной сети с точки зрения минимизации функции квадратичной стоимости, которая, по его словам, является синонимом среднеквадратичной ошибки. Однако две вещи меня смущают из-за его функций (псевдокод ниже).
MSE≡ (1 / 2n) * Σ‖y_true-y_pred‖^2
- Вместо того, чтобы делить сумму квадратов ошибок на количество обучающих примеров n, почему она вместо этого делится на 2n? Как это означает что-либо?
- Почему вместо круглых скобок используется двойная нотация? Это заставило меня подумать, что происходит какой-то другой расчет, такой как L2-норма, который явно не показан. Я подозреваю, что это не тот случай, и этот термин предназначен для выражения простой старой суммы квадратов ошибок. Очень запутанно, хотя.
Мы очень ценим любые идеи, которые вы можете предложить!
3 ответа
Коэффициент 0,5, на который умножается функция стоимости, не важен. На самом деле вы можете умножить ее на любую действительную константу, какую захотите, и обучение будет таким же. Он используется только для того, чтобы производная функции стоимости по выходным данным была просто $$y - y_{t}$$. Что удобно в некоторых приложениях, таких как обратное распространение.
Обозначение ∥v∥ просто обозначает обычную функцию длины для вектора v. Из онлайн-учебника, на который вы ссылались.
Найти больше информации о двойных барах здесь. Но из того, что я понимаю, вы можете рассматривать это как абсолютный термин.
Я не уверен, почему это говорит 2n, но это не всегда 2n. Википедия например пишет функцию следующим образом:
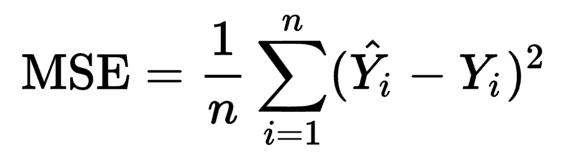
Погугление Mean Squared Error также имеет много источников, использующих Википедию, а не те, что из онлайн-учебника.
Двойная полоса - это мера расстояния, и скобка неверна, если y многомерно. Для среднеквадратичной ошибки нет 2 с n, но это неважно. Он будет поглощен скоростью обучения. Однако при вычислении производной часто приходится отменять квадрат числа 2.