Получить метки точек на указанном расстоянии / Граница-Питон
Я хотел бы получить метку точек, которые находятся на указанном расстоянии
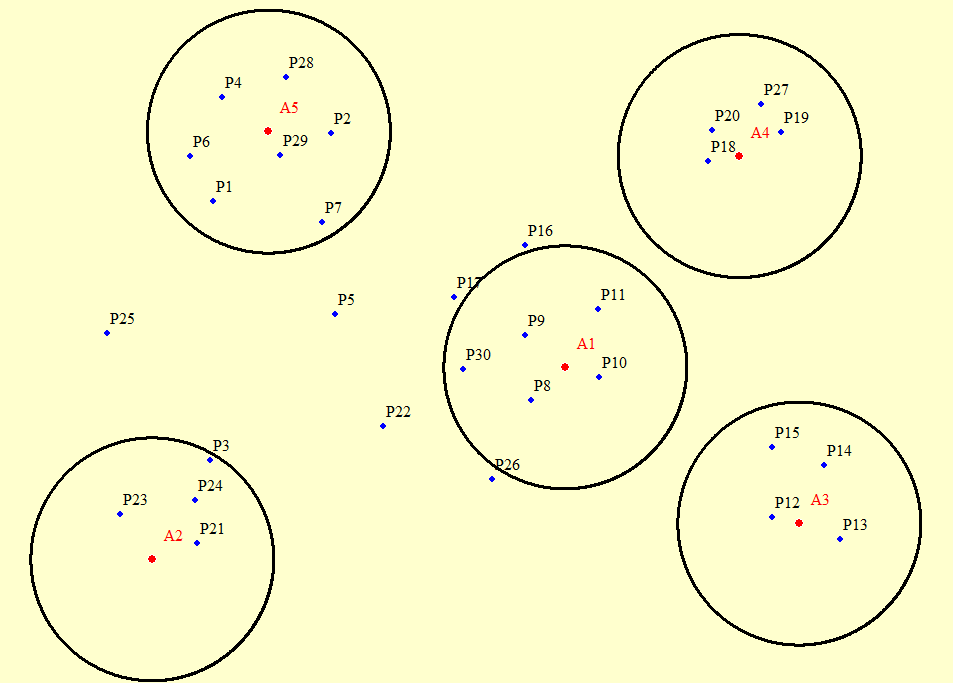
Я вставил пример координат ниже. Точки А1-А5 - это зоны, точки Р1-Р30 - это точки, которые нужно извлечь, которые находятся в 10000 метрах от зон. Для лучшего понимания я вставил изображение.
Координаты будут в Pandas Dataframe.
LABEL X Y
A1 704178 2359686
A2 670179 2343883
A3 723439 2346826
A4 718530 2377080
A5 679772 2379091
LABEL X Y
P1 675176 2373313
P2 684905 2378956
P3 675002 2352012
P4 675933 2381910
P5 685268 2364044
P6 673324 2377060
P7 684222 2371631
P8 701418 2356943
P9 700891 2362305
P10 706972 2358842
P11 706904 2364451
P12 721197 2347368
P13 726825 2345518
P14 725521 2351631
P15 721214 2353052
P16 700920 2369710
P17 695029 2365463
P18 715987 2376662
P19 721979 2379020
P20 716318 2379221
P21 673892 2345205
P22 689204 2354791
P23 667520 2347603
P24 673688 2348698
P25 666493 2362489
P26 698172 2350498
P27 720295 2381290
P28 681206 2383585
P29 680696 2377118
P30 695803 2359471
Мне нужно, чтобы результат был в формате ниже.
Label Zone
P8 A1
P9 A1
P10 A1
P11 A1
P30 A1
P3 A2
P23 A2
P24 A2
P21 A2
P12 A3
P13 A3
P14 A3
P15 A3
P18 A4
P20 A4
P19 A4
P27 A4
P1 A5
P2 A5
P4 A5
P6 A5
P28 A5
P29 A5
P7 A5
1 ответ
Предполагая следующую преамбулу (инициализация данных, импортированные библиотеки):
import numpy as np
import pandas as pd
from scipy.spatial.distance import cdist
zone_data = [['A1', 704178, 2359686], ['A2', 670179, 2343883], ['A3', 723439, 2346826],
['A4', 718530, 2377080], ['A5', 679772, 2379091]]
points_data = [['P1 ', 675176, 2373313], ['P2', 684905, 2378956],
['P3', 675002, 2352012], ['P4', 675933, 2381910],
['P5', 685268, 2364044], ['P6', 673324, 2377060],
['P7', 684222, 2371631], ['P8', 701418, 2356943],
['P9', 700891, 2362305], ['P10', 706972, 2358842],
['P11', 706904, 2364451], ['P12', 721197, 2347368],
['P13', 726825, 2345518], ['P14', 725521, 2351631],
['P15', 721214, 2353052], ['P16', 700920, 2369710],
['P17', 695029, 2365463], ['P18', 715987, 2376662],
['P19', 721979, 2379020], ['P20', 716318, 2379221],
['P21', 673892, 2345205], ['P22', 689204, 2354791],
['P23', 667520, 2347603], ['P24', 673688, 2348698],
['P25', 666493, 2362489], ['P26', 698172, 2350498],
['P27', 720295, 2381290], ['P28', 681206, 2383585],
['P29', 680696, 2377118], ['P30', 695803, 2359471]]
zones = pd.DataFrame(data=zone_data, columns=['LABEL', 'X', 'Y'])
points = pd.DataFrame(data=points_data, columns=['LABEL', 'X', 'Y'])
Вы можете сделать следующее:
zones = pd.DataFrame(data=zone_data, columns=['LABEL', 'X', 'Y'])
points = pd.DataFrame(data=points_data, columns=['LABEL', 'X', 'Y'])
mask = cdist(points[['X', 'Y']].values, zones[['X', 'Y']].values) < 10000
def zone(x):
return zones[x].LABEL.values[0] if x.any() else ''
result = points.drop(['X', 'Y'], axis=1)
result['zone'] = np.apply_along_axis(zone, 1, mask)
Выход
LABEL zone
0 P1 A5
1 P2 A5
2 P3 A2
3 P4 A5
4 P5
5 P6 A5
6 P7 A5
7 P8 A1
8 P9 A1
9 P10 A1
10 P11 A1
11 P12 A3
12 P13 A3
13 P14 A3
14 P15 A3
15 P16
16 P17
17 P18 A4
18 P19 A4
19 P20 A4
20 P21 A2
21 P22
22 P23 A2
23 P24 A2
24 P25
25 P26
26 P27 A4
27 P28 A5
28 P29 A5
29 P30 A1
Идея состоит в том, чтобы использовать cdist для вычисления расстояний между точками и зонами, а затем отфильтровывать (используя маску) эти зоны выше 10000, в случае, если более одной зоны ниже порогового значения, выбирается первая. Если все зоны находятся выше порога, возвращается пустая строка (см. zone функция).