Получение размера функции C++
Я читал этот вопрос, потому что я пытаюсь найти размер функции в программе на C++. Намекнули, что может быть способ, который зависит от платформы. Моя целевая платформа - Windows
Метод, который я сейчас использую в своей голове:
1. Получить указатель на функцию
2. Увеличивайте указатель (и счетчик), пока я не достигну значения машинного кода для ret
3. Счетчик будет размером функции?
Edit1: чтобы прояснить, что я имею в виду под "размером", я имею в виду количество байтов (машинный код), которые составляют функцию.
Edit2: было несколько комментариев, спрашивающих, почему или что я планирую делать с этим. Честный ответ: у меня нет намерений, и я не могу увидеть преимущества знания времени до компиляции длины функции. (хотя я уверен, что есть некоторые)
Мне кажется, это правильный метод, сработает ли это?
17 ответов
Нет, это не сработает
- Там нет никакой гарантии, что ваша функция содержит только один
retинструкция. - Даже если он содержит только один
retВы не можете просто смотреть на отдельные байты - потому что соответствующее значение может выглядеть как просто значение, а не как инструкция.
Первую проблему, возможно, можно обойти, если вы ограничите свой стиль кодирования, скажем, только одной точкой возврата в своей функции, но другая в основном требует дизассемблера, чтобы вы могли разделить отдельные инструкции.
Вау, я все время использую функцию подсчета размеров, и у нее много-много применений. Это надежно? Ни за что. Это стандарт с ++? Ни за что. Но именно поэтому вам нужно проверить его в дизассемблере, чтобы убедиться, что он работает, каждый раз, когда вы выпускаете новую версию. Флаги компилятора могут испортить порядок.
static void funcIwantToCount()
{
// do stuff
}
static void funcToDelimitMyOtherFunc()
{
__asm _emit 0xCC
__asm _emit 0xCC
__asm _emit 0xCC
__asm _emit 0xCC
}
int getlength( void *funcaddress )
{
int length = 0;
for(length = 0; *((UINT32 *)(&((unsigned char *)funcaddress)[length])) != 0xCCCCCCCC; ++length);
return length;
}
Кажется, лучше работать со статическими функциями. Глобальные оптимизации могут убить это.
PS Я ненавижу людей, спрашиваю, почему вы хотите сделать это, а это невозможно и т. Д. Перестаньте задавать эти вопросы, пожалуйста. Звучит глупо. Программистов часто просят делать нестандартные вещи, потому что новые продукты почти всегда выходят за пределы того, что доступно. Если они этого не делают, ваш продукт, вероятно, переосмысление того, что уже было сделано. Скучный!!!
Можно получить все блоки функции, но это неестественный вопрос, чтобы спросить, каков "размер" функции. Оптимизированный код переставляет кодовые блоки в порядке выполнения и перемещает редко используемые блоки (пути исключений) во внешние части модуля. Для получения дополнительной информации см. Оптимизация на основе профилей, например, как Visual C++ достигает этого при генерации временного кода ссылки. Таким образом, функция может начинаться с адреса 0x00001000, переходить по адресу 0x00001100 в переход с 0x20001000 и ret и иметь некоторый код обработки исключений 0x20001000. В 0x00001110 запускается другая функция. Каков "размер" вашей функции? Он охватывает диапазон от 0x00001000 до +0x20001000, но ему "принадлежит" только несколько блоков в этом диапазоне. Так что ваш вопрос должен быть не задан.
В этом контексте существуют и другие правильные вопросы, такие как общее количество инструкций, которые имеет функция (может быть определено из базы данных символов программы и из изображения), и, что более важно, каково количество инструкций в пути часто выполняемого кода внутри функция. Все эти вопросы обычно задаются в контексте измерения производительности, и существуют инструменты, которые кодируют инструмент и могут дать очень подробные ответы.
Погоня за указателями в памяти и поиск ret боюсь, ты никуда не доберешься. Современный код намного сложнее, чем этот.
Это не сработает... что, если есть прыжок, манекен ret, а затем цель прыжка? Ваш код будет одурачен.
В общем, это невозможно сделать со 100% точностью, потому что вы должны предсказать все пути кода, что похоже на решение проблемы остановки. Вы можете получить "довольно хорошую" точность, если внедрите свой собственный дизассемблер, но ни одно решение не будет таким легким, как вы себе представляете.
"Хитрость" заключается в том, чтобы выяснить, какой код функции находится после искомой функции, что дало бы довольно хорошие результаты, принимая определенные (опасные) предположения. Но тогда вам нужно знать, какая функция следует за вашей функцией, что после оптимизации довольно сложно понять.
Изменить 1:
Что делать, если функция даже не заканчивается ret инструкция вообще? Это может очень просто jmp вернуться к своему абоненту (хотя это маловероятно).
Изменить 2:
Не забывайте, что x86, по крайней мере, имеет инструкции переменной длины...
Обновить:
Для тех, кто говорит, что анализ потока - это не то же самое, что решение проблемы остановки:
Посмотрите, что происходит, когда у вас есть такой код:
foo:
....
jmp foo
Вам придется каждый раз выполнять переход, чтобы выяснить конец функции, и вы не можете игнорировать его после первого раза, потому что не знаете, имеете ли вы дело с самоизменяющимся кодом. (Например, в вашем коде C++ может быть встроенная сборка, которая сама себя модифицирует.) Она вполне может распространиться на другое место в памяти, поэтому ваш анализатор будет (или должен) заканчивать бесконечный цикл, если вы не допустите ложных отрицаний.
Разве это не похоже на проблему остановки?
Я публикую это, чтобы сказать две вещи:
1) Большинство ответов, приведенных здесь, действительно плохие и легко ломаются. Если вы используете указатель функции C (используя имя функции), в debug сборка вашего исполняемого файла, и, возможно, в других обстоятельствах, это может указывать на JMP шим что не будет иметь функции самого тела. Вот пример. Если я сделаю следующее для функции, которую я определил ниже:
FARPROC pfn = (FARPROC)some_function_with_possibility_to_get_its_size_at_runtime;
pfn Я получаю (например: 0x7FF724241893) укажет на это, что просто JMP инструкция:
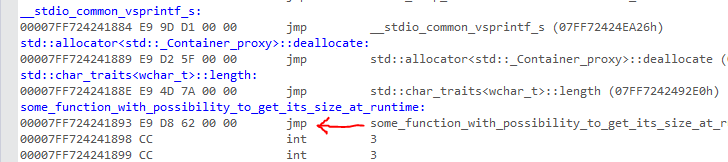
Кроме того, компилятор может вкладывать несколько таких оболочек или ветвить код вашей функции, чтобы он имел несколько эпилогов, или ret инструкции. Черт, он может даже не использовать ret инструкция. Тогда нет никакой гарантии, что сами функции будут скомпилированы и связаны в том порядке, в каком вы их определяете в исходном коде.
Вы можете делать все это на ассемблере, но не на C или C++.
2) Так что выше были плохие новости. Хорошей новостью является то, что ответ на первоначальный вопрос: да, есть способ (или способ взлома) получить точный размер функции, но он имеет следующие ограничения:
Он работает только в 64-битных исполняемых файлах под Windows.
Это, очевидно, специфично для Microsoft и не переносимо.
Вы должны сделать это во время выполнения.
Концепция проста - использовать способ, которым SEH реализован в двоичных файлах Windows x64. Компилятор добавляет детали каждой функции в заголовок PE32+ (в IMAGE_DIRECTORY_ENTRY_EXCEPTION каталог необязательного заголовка), который можно использовать для получения точного размера функции. (Если вам интересно, эта информация используется для перехвата, обработки и раскрутки исключений в __try/__except/__finally блоки.)
Вот быстрый пример:
//You will have to call this when your app initializes and then
//cache the size somewhere in the global variable because it will not
//change after the executable image is built.
size_t fn_size; //Will receive function size in bytes, or 0 if error
some_function_with_possibility_to_get_its_size_at_runtime(&fn_size);
а потом:
#include <Windows.h>
//The function itself has to be defined for two types of a call:
// 1) when you call it just to get its size, and
// 2) for its normal operation
bool some_function_with_possibility_to_get_its_size_at_runtime(size_t* p_getSizeOnly = NULL)
{
//This input parameter will define what we want to do:
if(!p_getSizeOnly)
{
//Do this function's normal work
//...
return true;
}
else
{
//Get this function size
//INFO: Works only in 64-bit builds on Windows!
size_t nFnSz = 0;
//One of the reasons why we have to do this at run-time is
//so that we can get the address of a byte inside
//the function body... we'll get it as this thread context:
CONTEXT context = {0};
RtlCaptureContext(&context);
DWORD64 ImgBase = 0;
RUNTIME_FUNCTION* pRTFn = RtlLookupFunctionEntry(context.Rip, &ImgBase, NULL);
if(pRTFn)
{
nFnSz = pRTFn->EndAddress - pRTFn->BeginAddress;
}
*p_getSizeOnly = nFnSz;
return false;
}
}
Это может работать в очень ограниченных сценариях. Я использую его как часть написанной мной утилиты внедрения кода. Я не помню, где я нашел информацию, но у меня есть следующее (C++ в VS2005):
#pragma runtime_checks("", off)
static DWORD WINAPI InjectionProc(LPVOID lpvParameter)
{
// do something
return 0;
}
static DWORD WINAPI InjectionProcEnd()
{
return 0;
}
#pragma runtime_checks("", on)
И тогда в какой-то другой функции у меня есть:
size_t cbInjectionProc = (size_t)InjectionProcEnd - (size_t)InjectionProc;
Вы должны отключить некоторые оптимизации и объявить функции как статические, чтобы заставить это работать; Я не помню специфику. Я не знаю, точное ли это количество байтов, но оно достаточно близко. Размер - это только размер непосредственной функции; он не включает никаких других функций, которые могут быть вызваны этой функцией. За исключением крайних случаев, подобных этому, "размер функции" не имеет смысла и бесполезен.
Реальное решение этой проблемы - копаться в документации вашего компилятора. Компилятор ARM, который мы используем, может быть создан для создания дампа сборки (code.dis), из которого довольно просто вычесть смещения между данной меткой искаженной функции и следующей меткой искаженной функции.
Однако я не уверен, какие инструменты вам понадобятся для этой цели. Похоже, что инструменты, перечисленные в ответе на этот вопрос, могут быть тем, что вы ищете.
Также обратите внимание, что я (работая во встроенном пространстве) предположил, что вы говорили о посткомпиляционном анализе. Возможно, что все эти промежуточные файлы можно будет программно проверить как часть сборки при условии, что:
- Целевая функция находится в другом объекте
- Система сборки обучена зависимостям
- Вы точно знаете, что компилятор будет создавать эти объектные файлы
Обратите внимание, что я не совсем уверен, ПОЧЕМУ вы хотите знать эту информацию. В прошлом я нуждался в этом, чтобы быть уверенным, что смогу разместить определенный кусок кода в определенном месте памяти. Должен признаться, мне любопытно, к чему это приведет в более общих целях настольных ОС.
Просто установите PAGE_EXECUTE_READWRITE по адресу, по которому вы получили свою функцию. Затем прочитайте каждый байт. Когда вы получили байт "0xCC", это означает, что конец функции - фактический_адрес_адрес - 1.
В C++ нет понятия размера функции. В дополнение ко всему остальному, макросы препроцессора также имеют неопределенный размер. Если вы хотите посчитать количество командных слов, вы не можете сделать это в C++, потому что он не существует, пока не будет скомпилирован.
В Стандарте C++ нет средств для получения размера или длины функции.
Смотрите мой ответ здесь: возможно ли загрузить функцию в некоторую выделенную память и запустить ее оттуда?
В общем, знание размера функции используется во встроенных системах при копировании исполняемого кода из источника, доступного только для чтения (или устройства с медленной памятью, такого как последовательная флэш-память), в ОЗУ. Настольные и другие операционные системы загружают функции в память, используя другие методы, такие как динамические или разделяемые библиотеки.
Что вы имеете в виду "размер функции"?
Если вы имеете в виду указатель на функцию, то для 32-битных систем это всегда всего 4 байта.
Если вы имеете в виду размер кода, то вам нужно просто разобрать сгенерированный код и найти точку входа и ближайший ret вызов. Один из способов сделать это - прочитать регистр указателя инструкций в начале и в конце вашей функции.
Если вы хотите выяснить количество инструкций, вызываемых в среднем случае для вашей функции, вы можете использовать профилировщики и разделить количество выбывших инструкций на количество вызовов.
Я думаю, что это будет работать на программах Windows, созданных с помощью msvc, так как для ветвей 'ret', кажется, всегда приходит в конце (даже если есть ветви, которые возвращаются рано, это делает jne, чтобы идти в конец). Однако вам понадобится какая-нибудь библиотека дизассемблера, чтобы определить текущую длину кода операции, поскольку они являются переменной длиной для x86. Если вы не сделаете этого, вы столкнетесь с ложными срабатываниями.
Я не был бы удивлен, если бы были случаи, которые это не ловит.
Ниже приведен код получения точного размера функционального блока, он работает нормально с моим тестом runtime_checks отключить _RTC_CheckEsp в режиме отладки
#pragma runtime_checks("", off)
DWORD __stdcall loadDll(char* pDllFullPath)
{
OutputDebugStringA(pDllFullPath);
//OutputDebugStringA("loadDll...................\r\n");
return 0;
//return test(pDllFullPath);
}
#pragma runtime_checks("", restore)
DWORD __stdcall getFuncSize_loadDll()
{
DWORD maxSize=(PBYTE)getFuncSize_loadDll-(PBYTE)loadDll;
PBYTE pTail=(PBYTE)getFuncSize_loadDll-1;
while(*pTail != 0xC2 && *pTail != 0xC3) --pTail;
if (*pTail==0xC2)
{ //0xC3 : ret
//0xC2 04 00 : ret 4
pTail +=3;
}
return pTail-(PBYTE)loadDll;
};
int GetFuncSizeX86(unsigned char* Func)
{
if (!Func)
{
printf("x86Helper : Function Ptr NULL\n");
return 0;
}
for (int count = 0; ; count++)
{
if (Func[count] == 0xC3)
{
unsigned char prevInstruc = *(Func - 1);
if (Func[1] == 0xCC // int3
|| prevInstruc == 0x5D// pop ebp
|| prevInstruc == 0x5B// pop ebx
|| prevInstruc == 0x5E// pop esi
|| prevInstruc == 0x5F// pop edi
|| prevInstruc == 0xCC// int3
|| prevInstruc == 0xC9)// leave
return count++;
}
}
}
вы можете использовать это, предполагая, что вы находитесь в x86 или x86_64
Непереносимый, но основанный на API и правильно работающий подход заключается в использовании программ чтения программных баз данных - таких как dbghelp.dll в Windows или readelf в Linux. Их использование возможно только в том случае, если отладочная информация включена / присутствует вместе с программой. Вот пример того, как это работает в Windows:
SYMBOL_INFO symbol = { };
symbol.SizeOfStruct = sizeof(SYMBOL_INFO);
// Implies, that the module is loaded into _dbg_session_handle, see ::SymInitialize & ::SymLoadModule64
::SymFromAddr(_dbg_session_handle, address, 0, &symbol);
Вы получите размер функции в symbol.Size, но вам также может понадобиться дополнительная логика, определяющая, является ли данный адрес на самом деле функцией, прокладкой, размещенной там инкрементным компоновщиком, или обработчиком вызова DLL (тоже самое).
Я полагаю, что нечто подобное можно сделать через readelf в Linux, но, возможно, вам придется придумать библиотеку поверх ее исходного кода...
Вы должны иметь в виду, что, хотя подход, основанный на разборке, возможен, вам, в основном, придется анализировать ориентированный граф с конечными точками в ret, halt, jmp (ДОКАЗАНО, что включено инкрементное связывание, и вы можете читать jmp-таблицу для определить, является ли jmp, с которым вы сталкиваетесь в функции, внутренним по отношению к этой функции (отсутствует в jmp-таблице изображения) или внешним (присутствует в этой таблице; такие jmp часто встречаются как часть оптимизации хвостового вызова на x64, как я знаю)) любые вызовы, которые должны быть nonret (например, помощник, генерирующий исключение) и т. д.
Это старый вопрос, но все же...
В Windows x64 все функции имеют таблицу функций, которая содержит смещение и размер функции. https://docs.microsoft.com/en-us/windows/win32/debug/pe-format. Эта таблица функций используется для раскрутки при возникновении исключения.
Тем не менее, это не содержит такой информации, как встраивание, и всех других проблем, которые люди уже отметили...
Использование GCC не так уж и сложно.
void do_something(void) {
printf("%s!", "Hello your name is Cemetech");
do_something_END:
}
...
printf("size of function do_something: %i", (int)(&&do_something_END - (int)do_something));