Создание MDP // Искусственный интеллект для 2D игры с несколькими терминалами
Так что я уверен, что все слышали о вызове Беркли Pac-Man AI в тот или иной момент. Некоторое время назад я создал 2D-платформер (без прокрутки) и подумал, что было бы неплохо черпать вдохновение из этого проекта, но создать AI для моей игры (вместо PacMan). При этом, я обнаружил, что очень застрял. Я рассмотрел несколько решений GitHub для PacMan, а также множество статей, касающихся реализации обучения MDP / Reinforced в Python. Мне трудно связать их с моей игрой.
В моей игре у меня 10 уровней. У каждого уровня есть фрукты, и как только агент захватывает все фрукты, он завершает уровень, и начинается следующий уровень. Вот пример этапа:
Как вы можете видеть на этой фотографии, мой агент - маленькая белка, и он должен схватить все вишни. На земле также есть шипы, по которым он не может ходить (или вы теряете жизнь). Вы можете избежать шипов, прыгнув. Таким образом, прыжок технически перемещает агента на 2 области влево или вправо (в зависимости от того, как он смотрит). Кроме этого вы можете двигаться влево, вправо, вверх и вниз по лестнице. Вы не можете прыгнуть больше, чем на 1 пробел, поэтому "2+ gappers" наверху, которые вы видите, вам придется спуститься по лестнице и обойти. Кроме того, не изображенные выше, есть враги, которые идут влево и вправо только на полу, который вы должны уклоняться (вы можете перепрыгнуть через них или просто избежать их). Они отслеживаются в сетке, о которой я расскажу ниже. Так что это немного об игре, если вам нужны дополнительные разъяснения, не стесняйтесь спрашивать, и я могу помочь, позвольте мне немного углубиться в то, что я сейчас попробовал, и посмотреть, может ли кто-нибудь помочь мне собрать что-то вместе.
В моем коде у меня есть сетка, в которой есть все места на карте и то, что они есть (платформа, обычное место, шип, награда / фрукты, лестница и т. Д.). Используя это, я создал сетку действий (код ниже), которая в основном хранит в словаре все точки, которые агент может перемещать из каждого места.
for r in range(len(state_grid)):
for c in range(len(state_grid[r])):
if(r == 9 or r == 6 or r == 3 or r == 0):
if (move_grid[r][c] != 6):
actions.update({state_grid[r][c] : 'None'})
else:
actions.update({state_grid[r][c] : [('Down', 'Up')]})
elif move_grid[r][c] == 4 or move_grid[r][c] == 0 or move_grid[r][c] == 2 or move_grid[r][c] == 3 or move_grid[r][c] == 5:
actions.update({state_grid[r][c] : 'None'})
elif move_grid[r][c] == 6:
if move_grid[r+1][c] == 4 or move_grid[r+1][c] == 2 or move_grid[r+1][c] == 3 or move_grid[r+1][c] == 5:
if c > 0 and c < 18:
actions.update({state_grid[r][c] : [('Left', 'Right', 'Up', 'Jump Left', 'Jump Right')]})
elif c == 0:
actions.update({state_grid[r][c] : [('Right', 'Up', 'Jump Right')]})
elif c == 18:
actions.update({state_grid[r][c] : [('Left', 'Up', 'Jump Left')]})
elif move_grid[r+1][c] == 6:
actions.update({state_grid[r][c] : [('Down', 'Up')]})
elif move_grid[r][c] == 1 or move_grid[r][c] == 8 or move_grid[r][c] == 9 or move_grid[r][c] == 10:
if c > 0 and c < 18:
if move_grid[r+1][c] == 6:
actions.update({state_grid[r][c] : [('Down', 'Left', 'Right', 'Jump Left', 'Jump Right')]})
else:
actions.update({state_grid[r][c] : [('Left', 'Right', 'Jump Left', 'Jump Right')]})
elif c == 0:
if move_grid[r+1][c] == 6:
actions.update({state_grid[r][c] : [('Down', 'Right', 'Jump Right')]})
else:
actions.update({state_grid[r][c] : [('Right', 'Jump Right')]})
elif c == 18:
if move_grid[r+1][c] == 6:
actions.update({state_grid[r][c] : [('Down', 'Left', 'Jump Left')]})
else:
actions.update({state_grid[r][c] : [('Left', 'Jump Left')]})
elif move_grid[r][c] == 7:
actions.update({state_grid[r][c] : 'Spike'})
else:
actions.update({state_grid[r][c] : 'WTF'})
На данный момент я просто застрял на том, как / что необходимо отправить в MDP. Я использую Беркли MDP, и я просто застрял в том, как начать вовлекать и реализовывать его. У меня есть куча точек данных и того, где они находятся, но я не знаю, как на самом деле добиться успеха.
У меня есть логическая сетка, которая отслеживает все вредные объекты (шипы и враги) и постоянно обновляется, поскольку враги двигаются каждую секунду.
Я создал сетку наград, которая устанавливает:
- Шипы "-5" награда
- Спадающая с карты "-5" награда
- Фрукт - награда "5"
- Все остальное - награда "-0.2" (так как вы хотите оптимизировать шаги, не пытаясь быть на уровне 1 весь день).
Другая часть моей проблемы во время исследования решений или способов их реализации заключается в том, что большинство решений - это автомобили, которые едут на определенную позицию. Таким образом, у них есть только 1 награда, в то время как у меня есть несколько фруктов за этап. Да, я просто супер застрял и разочаровался в этом. Хотел попробовать себя сам, но если я не смогу сделать это, я мог бы просто сделать Pac-Man, так как есть несколько онлайн-решений. Я ценю ваше время и помощь в этом!
Изменить: Итак, вот я пытаюсь сделать пример вызова вернуть сетку движения, хотя из моего понимания (и, очевидно,) он будет динамически меняться после каждого шага, который делает агент, так как враг будет угрожать определенным точкам и всем.
Это результат, вы можете видеть, что это близко, но, очевидно, немного застрял на том факте, что есть несколько наград. Я чувствую, что могу быть рядом, но я не совсем уверен. Я немного расстроен в этот момент. 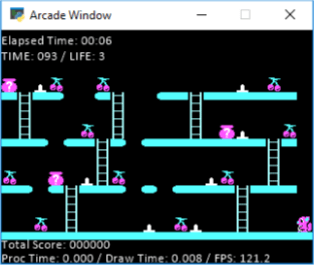
1 ответ
Создание искусственного интеллекта связано с управлением пространством состояний. В 2d платформерной игре пространство состояний управлялось таблицей карт. Это означает, что робот может находиться в положении x/y, и эта позиция связана с вознаграждением, которое дает таблица. Идея q-learning заключается в том, чтобы создать пространство действия состояния с нуля с помощью алгоритма проб и ошибок. Это означает, что с точки зрения обучения усилению задача была решена, поздравляем. Если программное обеспечение содержит q-таблицу, в которой хранятся награды, и если награды определяются автоматически, это робот обучения подкреплению.
Получит ли игра 2d платформер пользу от этого подхода? Возможно, нет, и это причина, по которой возможно небольшое разочарование. Проблема в том, что идея связать положение игрока на карте с вознаграждением слишком механична. Это не приведет к человеческой политике, но к неработающему контроллеру. Это означает, что прогноз состоит в том, что робот провалится на уровне. Он не может ни избежать шипов, ни собрать фрукты.
Улучшить алгоритм ИИ легко: все, что нужно сделать разработчику, это изобрести новое пространство состояний. Это означает, что он должен отобразить потенциальные действия робота в матрице q-таблицы, которую можно изучить. Опишем потенциальные состояния робота: робот может находиться рядом с лестницей, рядом с фруктом, рядом с шипами и перед тем, как упасть куда-нибудь. Состояния могут быть объединены, это означает, что две ситуации могут быть там одновременно. Этот вид качественного описания состояния должен быть сопоставлен с q-таблицей. В чем отличие от предыдущего описания пространства состояний? В первом примере состояние робота было задано простым значением x/y. В лучшем подходе состояние задается лингвистическими переменными ("около лестницы", "около фруктов"). Такое лингвистическое обоснование позволяет отлаживать алгоритм, если что-то не так с роботом. Это означает, что связь между разработчиками и его программным обеспечением улучшилась.