Общий поиск ключевых слов
Я хочу найти список всех веб-сайтов с определенными ключевыми словами. Например, если я ищу по ключевому слову "Спорт" или "Футбол", из общего сканирования необходимо извлечь только URL-адреса, заголовок, описание и изображение соответствующего веб-сайта. варк файлы. В настоящее время я могу прочитать файл warc со следующим кодом.
import warc
f = warc.open("firsttest.warc.gz")
h = warc.WARCHeader({"WARC-Type": "response",}, defaults=True)
N = 10
name="sports"
for record in f:
url = record.header.get('warc-target-uri', 'none')
date=record.header.get("WARC-Date")
IP=record.header.get('WARC-IP-Address')
payload_di=record.header.get('WARC-Payload-Digest')
search =name in record.header
print("URL :"+str(url))
#print("date :"+str(date))
#print("IP :"+str(IP))
#print("payload_digest :"+str(payload_di))
#print("search :"+str(search))
text = record.payload.read()
#print("Text :"+str(text))
#break
#print(url)
Но он получает все URL в указанном файле warc. Мне нужны только связанные URL, которые соответствуют "спорту" или "футболу". Как я могу найти это ключевое слово в файлах warc? Пожалуйста, помогите мне в этом, так как я новичок в обычном сканировании. Я также проверил много сообщений, но ни один из них не сработал.
Мне нужно захватить изображение статьи, если они есть, Как я могу взять его как обычное сканирование, сохраняя всю веб-страницу.?
0 ответов
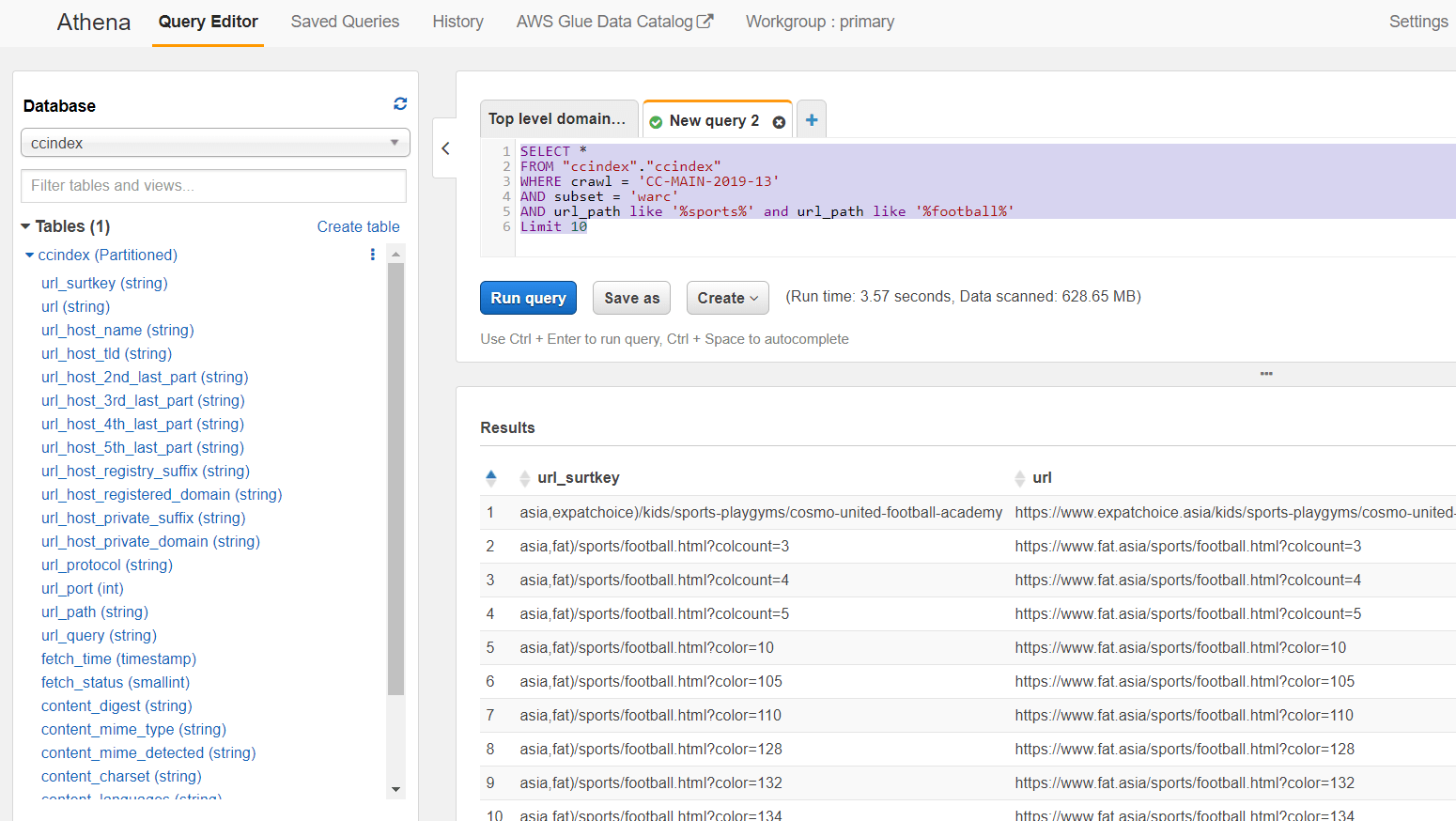
You can use the AWS Athena to query Common Crawl Index on S3. For example, here is my SQL query to find the "sports" and "football" matching URLs in July 2019 index. See this page - http://commoncrawl.org/2018/03/index-to-warc-files-and-urls-in-columnar-format/
SELECT *
FROM "ccindex"."ccindex"
WHERE crawl = 'CC-MAIN-2019-13'
AND subset = 'warc'
AND url_path like '%sports%' and url_path like '%football%'
Limit 10