Функция для демпфирования значения
У меня есть список документов, каждый из которых имеет оценку релевантности для поискового запроса. Мне нужны более старые документы, чтобы уменьшить их релевантность, чтобы попытаться ввести их дату в процесс ранжирования. Я уже пытался поиграться с такими функциями, как 1/(1+date_difference), но обратная функция слишком разборчива для близких недавних дат.
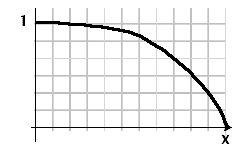
Я подумал, может быть, математическая функция с диапазоном (0..1) и доменом (0..x), чтобы усилить их оценку, где ось X - это возраст документа. Лучше всего объяснить, что мне еще нужно от функции с помощью изображения:
4 ответа
Распадающееся поведение часто хорошо моделируется экспоненциальной функцией (за ней следуют многие распадающиеся процессы в природе). Вы бы использовали 2 положительных параметра A а также B и получить
y(x) = A exp(-B x)
Так как вы хотите y-диапазон [0,1] A=1, больше B дают более медленные распады.
log((x+1)-age_of_document)
Где основание логарифма (х +1). Обратите внимание, что х соответствует вашей диаграмме и является "порогом". Если возраст документа превышает x, оценка становится отрицательной. Умножьте на максимально возможную оценку, чтобы ввести масштабирование.
Например, домен = (0,10) с максимальным счетом 10: 10 * (log (11-x)) / log (11)
Если простая 1/(1+x) слишком быстро уменьшается слишком рано, сигмоидальная функция, такая как 1/(1+e^-x) или функция ошибок, может лучше подходить для вашей цели. Пусть текущая дата находится где-то в отрицательных числах для такой функции, и вы можете получить значение, которое является текущим в течение некоторого настраиваемого времени, а затем уменьшается к базовому значению.
Немного поздно, но, как говорит Титон, вы можете вместо этого использовать сигмовидную функцию, так как она имеет значение "floor" для ваших длинных точек данных. Например:
0,8/(1+5^(x-3)) + 0,2 - можно отрегулировать константы 5 и 3 для управления наклоном кривой. 0,2 - это то место, где будет пол.