Как быстро проанализировать разделенные пробелами числа в C++?
У меня есть файл с миллионами строк, каждая строка имеет 3 числа с плавающей точкой, разделенные пробелами. Чтение файла занимает много времени, поэтому я попытался прочитать их, используя файлы с отображением в памяти, только чтобы выяснить, что проблема не в скорости ввода-вывода, а в скорости синтаксического анализа.
Мой текущий анализ состоит в том, чтобы взять поток (называемый файл) и сделать следующее
float x,y,z;
file >> x >> y >> z;
Кто-то в Stack Overflow рекомендовал использовать Boost.Spirit, но я не смог найти ни одного простого учебника, объясняющего, как его использовать.
Я пытаюсь найти простой и эффективный способ анализа строки, которая выглядит следующим образом:
"134.32 3545.87 3425"
Я буду очень признателен за помощь. Я хотел использовать strtok для его разделения, но я не знаю, как преобразовать строки в плавающие, и я не совсем уверен, что это лучший способ.
Я не против, если решение будет Повышение или нет. Я не против, если это будет самое эффективное решение, но я уверен, что можно удвоить скорость.
Заранее спасибо.
7 ответов
Если конверсия является "горлышком бутылки" (что вполне возможно), вам следует начать с использования различных возможностей в стандарте. Логично, что можно ожидать, что они будут очень близки, но практически они не всегда:
Вы уже определили, что
std::ifstreamслишком медленноПреобразование данных, отображенных в вашей памяти, в
std::istringstreamпочти наверняка не хорошее решение; сначала вам нужно будет создать строку, которая будет копировать все данные.Пишу свой
streambufчитать прямо из памяти, не копируя (или используя устаревшийstd::istrstream) может быть решением, хотя, если проблема действительно в преобразовании... при этом все равно используются те же процедуры преобразования.Вы всегда можете попробовать
fscanf, или жеscanfв вашей памяти отображается поток. В зависимости от реализации они могут быть быстрее, чем различныеistreamРеализации.Вероятно, быстрее, чем любой из них, чтобы использовать
strtod, Не нужно токенизировать для этого:strtodпропускает ведущие пробелы (в том числе'\n') и имеет выходной параметр, в который помещается адрес первого не прочитанного символа. Конечное условие немного сложнее, ваш цикл должен выглядеть примерно так:
char * begin; // Установить указатель на данные mmap...
// Вы также должны организовать '\0'
// следить за данными. Это наверное
// самый сложный вопрос.
символ * конец;
errno = 0;
double tmp = strtod(начало и конец);
while ( errno == 0 && end!= begin) {
// делать что угодно с tmp...
начало = конец;
tmp = strtod(начало и конец);
}Если ни один из них не достаточно быстрый, вам придется рассмотреть фактические данные. Возможно, у него есть какие-то дополнительные ограничения, что означает, что вы можете написать подпрограмму преобразования, которая быстрее, чем более общие; например strtod должен обрабатывать как фиксированные, так и научные данные, и он должен быть на 100% точным, даже если есть 17 значащих цифр. Это также должно быть определенным языковым стандартом. Все это добавляет сложности, что означает добавленный код для выполнения. Но будьте осторожны: написание эффективной и правильной процедуры преобразования, даже для ограниченного набора входных данных, нетривиально; Вы действительно должны знать, что вы делаете.
РЕДАКТИРОВАТЬ:
Просто из любопытства я провел несколько тестов. В дополнение к вышеупомянутым решениям я написал простой пользовательский преобразователь, который обрабатывает только фиксированную точку (не научную), не более пяти цифр после десятичной дроби, а значение перед десятичной дробью должно помещаться в int:
double
convert( char const* source, char const** endPtr )
{
char* end;
int left = strtol( source, &end, 10 );
double results = left;
if ( *end == '.' ) {
char* start = end + 1;
int right = strtol( start, &end, 10 );
static double const fracMult[]
= { 0.0, 0.1, 0.01, 0.001, 0.0001, 0.00001 };
results += right * fracMult[ end - start ];
}
if ( endPtr != nullptr ) {
*endPtr = end;
}
return results;
}
(Если вы на самом деле используете это, вам определенно следует добавить некоторую обработку ошибок. Она просто быстро запускалась для экспериментальных целей, чтобы прочитать созданный мной тестовый файл, и ничего больше.)
Интерфейс точно такой strtod, чтобы упростить кодирование.
Я провел тесты в двух средах (на разных машинах, поэтому абсолютные значения для любого времени не имеют значения). Я получил следующие результаты:
Под Windows 7, скомпилированный с VC 11 (/O2):
Testing Using fstream directly (5 iterations)...
6.3528e+006 microseconds per iteration
Testing Using fscan directly (5 iterations)...
685800 microseconds per iteration
Testing Using strtod (5 iterations)...
597000 microseconds per iteration
Testing Using manual (5 iterations)...
269600 microseconds per iteration
Под Linux 2.6.18, скомпилированный с g++ 4.4.2 (-O2, IIRC):
Testing Using fstream directly (5 iterations)...
784000 microseconds per iteration
Testing Using fscanf directly (5 iterations)...
526000 microseconds per iteration
Testing Using strtod (5 iterations)...
382000 microseconds per iteration
Testing Using strtof (5 iterations)...
360000 microseconds per iteration
Testing Using manual (5 iterations)...
186000 microseconds per iteration
Во всех случаях я читаю 554000 строк, каждая с 3 случайными числами с плавающей запятой в диапазоне [0...10000),
Самое поразительное - это огромная разница междуfstream а также fscan под Windows (и относительно небольшая разница между fscan а также strtod). Во-вторых, насколько выигрывает простая пользовательская функция преобразования на обеих платформах. Необходимая обработка ошибок немного замедлила бы это, но разница все еще значительна. Я ожидал некоторого улучшения, так как он не обрабатывает много вещей, которые делают стандартные процедуры преобразования (например, научный формат, очень, очень маленькие числа, Inf и NaN, i18n и т. Д.), Но не так много.
ОБНОВИТЬ
Поскольку Spirit X3 доступен для тестирования, я обновил тесты. Тем временем я использовал Nonius для получения статистически достоверных результатов.
Все графики ниже доступны интерактивно онлайн
Тестовый проект CMake + используемые тестовые данные находятся на github: https://github.com/sehe/bench_float_parsing
Резюме:
Духовные парсеры самые быстрые. Если вы можете использовать C++14, рассмотрите экспериментальную версию Spirit X3:
Выше приведены измерения с использованием отображенных в память файлов. Используя IOstreams, это будет медленнее по всем направлениям,
но не так медленно, как scanf используя C/POSIX FILE* вызовы функций:
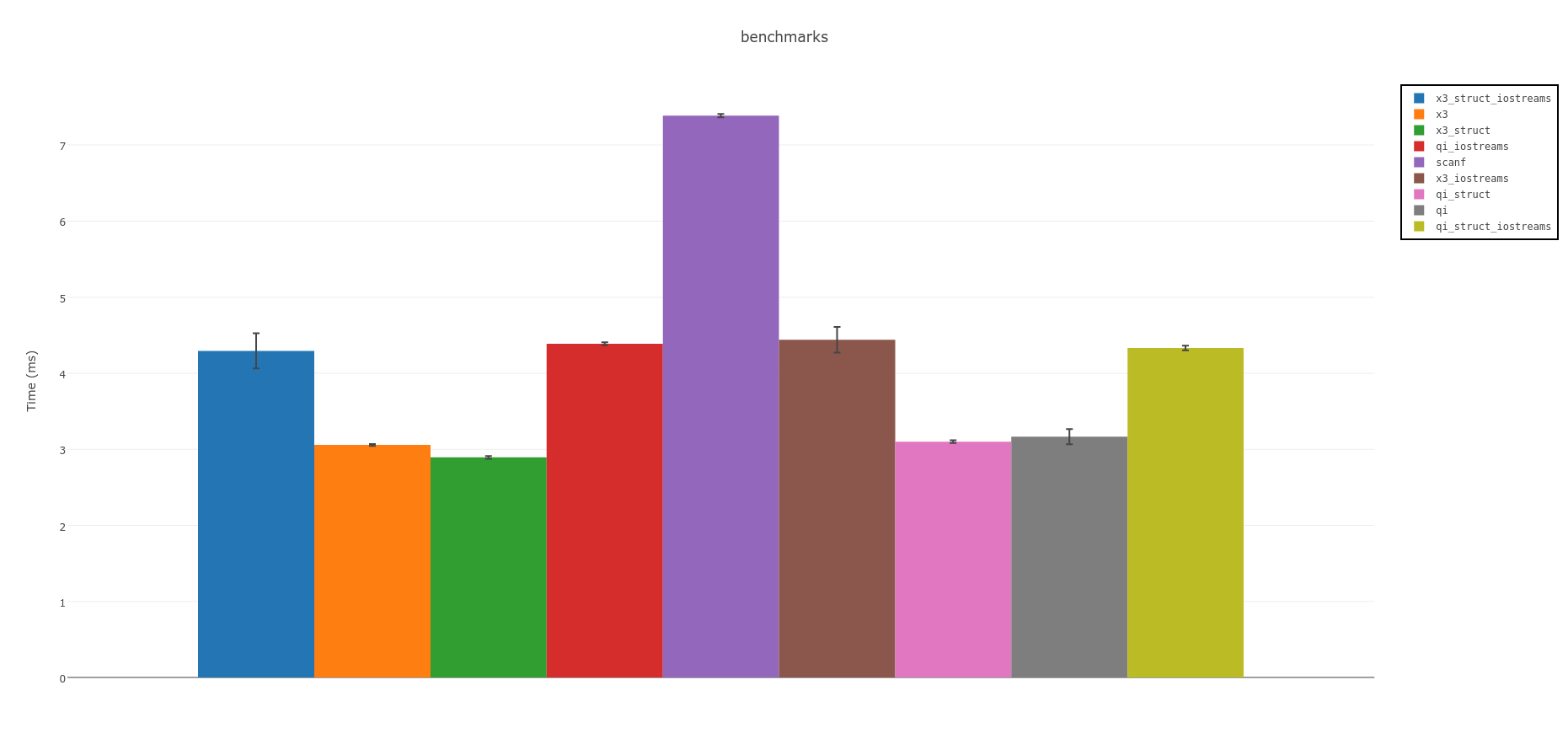
Далее следует части из старого ответа
Я реализовал версию Spirit и провел тест по сравнению с другими предлагаемыми ответами.
Вот мои результаты, все тесты выполняются на одном и том же теле ввода (515Mb
input.txt). Смотрите ниже точные спецификации.
(время настенных часов в секундах, в среднем 2+ пробега)К моему собственному удивлению, Boost Spirit оказывается самым быстрым и самым элегантным:
- обрабатывает / сообщает об ошибках
- поддерживает +/-Inf и NaN и переменные пробелы
- нет проблем с определением конца ввода (в отличие от другого ответа mmap)
выглядит хорошо:
bool ok = phrase_parse(f,l, // source iterators (double_ > double_ > double_) % eol, // grammar blank, // skipper data); // output attributeОбратите внимание, что
boost::spirit::istreambuf_iteratorбыло невыразимо намного медленнее (15 с +). Надеюсь, это поможет!Контрольные данные
Все разбор сделано в
vectorизstruct float3 { float x,y,z; },Создать входной файл, используя
od -f -A none --width=12 /dev/urandom | head -n 11000000В результате получается файл размером 515 Мб, содержащий данные, подобные
-2627.0056 -1.967235e-12 -2.2784738e+33 -1.0664798e-27 -4.6421956e-23 -6.917859e+20 -1.1080849e+36 2.8909405e-33 1.7888695e-12 -7.1663235e+33 -1.0840628e+36 1.5343362e-12 -3.1773715e-17 -6.3655537e-22 -8.797282e+31 9.781095e+19 1.7378472e-37 63825084 -1.2139188e+09 -5.2464635e-05 -2.1235992e-38 3.0109424e+08 5.3939846e+30 -6.6146894e-20Скомпилируйте программу, используя:
g++ -std=c++0x -g -O3 -isystem -march=native test.cpp -o test -lboost_filesystem -lboost_iostreamsИзмерьте время настенных часов, используя
time ./test < input.txt

Среда:
- Рабочий стол Linux 4.2.0-42-generiC#49-Ubuntu SMP x86_64
- Процессор Intel(R) Core(TM) i7-3770K @ 3,50 ГГц
- 32 ГБ ОЗУ
Полный код
Полный код старого теста находится в истории редактирования этого поста, последняя версия на github.
Перед тем, как начать, убедитесь, что это медленная часть вашего приложения, и проведите тестовую привязку, чтобы можно было измерить улучшения.
boost::spirit было бы излишним для этого, по моему мнению. Пытаться fscanf
FILE* f = fopen("yourfile");
if (NULL == f) {
printf("Failed to open 'yourfile'");
return;
}
float x,y,z;
int nItemsRead = fscanf(f,"%f %f %f\n", &x, &y, &z);
if (3 != nItemsRead) {
printf("Oh dear, items aren't in the right format.\n");
return;
}
Я бы проверил эту связанную статью Использование ifstream для чтения чисел с плавающей запятой или Как токенизировать строку в C++, особенно сообщения, связанные с C++ String Toolkit Library. Я использовал C strtok, C++ потоки, токенайзер Boost, и лучшим из них для простоты использования является C++ String Toolkit Library.
РЕДАКТИРОВАТЬ: Для тех, кто беспокоится о том, что crack_atof никоим образом не проверяется, см. Комментарии о Рю внизу.
Вот более полная (хотя и не "официальная" по любым стандартам) высокоскоростная строка для двойной подпрограммы, поскольку красивый C++17 from_chars() решение работает только на MSVC (не clang или gcc).
Встретить crack_atof
https://gist.github.com/oschonrock/a410d4bec6ec1ccc5a3009f0907b3d15
Не моя работа, просто немного переделал. И поменял подпись. Код очень прост для понимания, и очевидно, почему он быстрый. И это очень-очень быстро, см. Тесты здесь:
https://www.codeproject.com/Articles/1130262/Cplusplus-string-view-Conversion-to-Integral-Types
Я запустил его с 11 000 000 строк по 3 числа с плавающей запятой (точность 15 разрядов в CSV, что важно!). На моем старом Core i7 2600 2-го поколения он работал 1,327 с. Компилятор clang V8.0.0 -O2 на Kubuntu 19.04.
Полный код ниже. Я использую mmap, потому что str->float больше не единственное узкое место благодаря crack_atof. Я обернул материал mmap в класс, чтобы обеспечить выпуск карты RAII.
#include <iomanip>
#include <iostream>
// for mmap:
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
class MemoryMappedFile {
public:
MemoryMappedFile(const char* filename) {
int fd = open(filename, O_RDONLY);
if (fd == -1) throw std::logic_error("MemoryMappedFile: couldn't open file.");
// obtain file size
struct stat sb;
if (fstat(fd, &sb) == -1) throw std::logic_error("MemoryMappedFile: cannot stat file size");
m_filesize = sb.st_size;
m_map = static_cast<const char*>(mmap(NULL, m_filesize, PROT_READ, MAP_PRIVATE, fd, 0u));
if (m_map == MAP_FAILED) throw std::logic_error("MemoryMappedFile: cannot map file");
}
~MemoryMappedFile() {
if (munmap(static_cast<void*>(const_cast<char*>(m_map)), m_filesize) == -1)
std::cerr << "Warnng: MemoryMappedFile: error in destructor during `munmap()`\n";
}
const char* start() const { return m_map; }
const char* end() const { return m_map + m_filesize; }
private:
size_t m_filesize = 0;
const char* m_map = nullptr;
};
// high speed str -> double parser
double pow10(int n) {
double ret = 1.0;
double r = 10.0;
if (n < 0) {
n = -n;
r = 0.1;
}
while (n) {
if (n & 1) {
ret *= r;
}
r *= r;
n >>= 1;
}
return ret;
}
double crack_atof(const char* start, const char* const end) {
if (!start || !end || end <= start) {
return 0;
}
int sign = 1;
double int_part = 0.0;
double frac_part = 0.0;
bool has_frac = false;
bool has_exp = false;
// +/- sign
if (*start == '-') {
++start;
sign = -1;
} else if (*start == '+') {
++start;
}
while (start != end) {
if (*start >= '0' && *start <= '9') {
int_part = int_part * 10 + (*start - '0');
} else if (*start == '.') {
has_frac = true;
++start;
break;
} else if (*start == 'e') {
has_exp = true;
++start;
break;
} else {
return sign * int_part;
}
++start;
}
if (has_frac) {
double frac_exp = 0.1;
while (start != end) {
if (*start >= '0' && *start <= '9') {
frac_part += frac_exp * (*start - '0');
frac_exp *= 0.1;
} else if (*start == 'e') {
has_exp = true;
++start;
break;
} else {
return sign * (int_part + frac_part);
}
++start;
}
}
// parsing exponent part
double exp_part = 1.0;
if (start != end && has_exp) {
int exp_sign = 1;
if (*start == '-') {
exp_sign = -1;
++start;
} else if (*start == '+') {
++start;
}
int e = 0;
while (start != end && *start >= '0' && *start <= '9') {
e = e * 10 + *start - '0';
++start;
}
exp_part = pow10(exp_sign * e);
}
return sign * (int_part + frac_part) * exp_part;
}
int main() {
MemoryMappedFile map = MemoryMappedFile("FloatDataset.csv");
const char* curr = map.start();
const char* start = map.start();
const char* const end = map.end();
uintmax_t lines_n = 0;
int cnt = 0;
double sum = 0.0;
while (curr && curr != end) {
if (*curr == ',' || *curr == '\n') {
// std::string fieldstr(start, curr);
// double field = std::stod(fieldstr);
// m_numLines = 11000000 cnt=33000000 sum=16498294753551.9
// real 5.998s
double field = crack_atof(start, curr);
// m_numLines = 11000000 cnt=33000000 sum=16498294753551.9
// real 1.327s
sum += field;
++cnt;
if (*curr == '\n') lines_n++;
curr++;
start = curr;
} else {
++curr;
}
}
std::cout << std::setprecision(15) << "m_numLines = " << lines_n << " cnt=" << cnt
<< " sum=" << sum << "\n";
}
Код также включен в github gist:
https://gist.github.com/oschonrock/67fc870ba067ebf0f369897a9d52c2dd
Использование C будет самым быстрым решением. Разделить на токены, используя strtok а затем преобразовать в плавающее сstrtof, Или если вы знаете точный формат использования fscanf,
Нежно-песчаным решением было бы добавить больше ядер к проблеме, порождая множество потоков. Если узким местом является только процессор, вы можете сократить время работы вдвое, создав два потока (на многоядерных процессорах).
некоторые другие советы:
старайтесь избегать парсинга функций из библиотеки, таких как boost и / или std. Они раздуты с условиями проверки ошибок, и большая часть времени обработки тратится на эти проверки. Всего за пару преобразований они хороши, но с треском проваливаются, когда дело доходит до обработки миллионов значений. Если вы уже знаете, что ваши данные хорошо отформатированы, вы можете написать (или найти) настраиваемую оптимизированную функцию C, которая выполняет только преобразование данных.
используйте большой буфер памяти (скажем, 10 Мбайт), в который вы загружаете порции своего файла и выполняете там преобразование
Поделись с другими: разбей свою проблему на более мелкие: предварительно обработай свой файл, сделай его одной строкой с одним плавающим знаком, разделив каждую строку на "." символ и преобразовать целые числа вместо числа с плавающей точкой, затем объединить два целых числа, чтобы создать число с плавающей точкой
Я считаю, что одно из самых важных правил в обработке строк - "читать только один раз, по одному символу за раз". Думаю, это всегда проще, быстрее и надежнее.
Я сделал простую тестовую программу, чтобы показать, насколько она проста. Мой тест говорит, что этот код работает на 40% быстрее, чем strtod версия.
#include <iostream>
#include <sstream>
#include <iomanip>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <sys/time.h>
using namespace std;
string test_generate(size_t n)
{
srand((unsigned)time(0));
double sum = 0.0;
ostringstream os;
os << std::fixed;
for (size_t i=0; i<n; ++i)
{
unsigned u = rand();
int w = 0;
if (u > UINT_MAX/2)
w = - (u - UINT_MAX/2);
else
w = + (u - UINT_MAX/2);
double f = w / 1000.0;
sum += f;
os << f;
os << " ";
}
printf("generated %f\n", sum);
return os.str();
}
void read_float_ss(const string& in)
{
double sum = 0.0;
const char* begin = in.c_str();
char* end = NULL;
errno = 0;
double f = strtod( begin, &end );
sum += f;
while ( errno == 0 && end != begin )
{
begin = end;
f = strtod( begin, &end );
sum += f;
}
printf("scanned %f\n", sum);
}
double scan_float(const char* str, size_t& off, size_t len)
{
static const double bases[13] = {
0.0, 10.0, 100.0, 1000.0, 10000.0,
100000.0, 1000000.0, 10000000.0, 100000000.0,
1000000000.0, 10000000000.0, 100000000000.0, 1000000000000.0,
};
bool begin = false;
bool fail = false;
bool minus = false;
int pfrac = 0;
double dec = 0.0;
double frac = 0.0;
for (; !fail && off<len; ++off)
{
char c = str[off];
if (c == '+')
{
if (!begin)
begin = true;
else
fail = true;
}
else if (c == '-')
{
if (!begin)
begin = true;
else
fail = true;
minus = true;
}
else if (c == '.')
{
if (!begin)
begin = true;
else if (pfrac)
fail = true;
pfrac = 1;
}
else if (c >= '0' && c <= '9')
{
if (!begin)
begin = true;
if (pfrac == 0)
{
dec *= 10;
dec += c - '0';
}
else if (pfrac < 13)
{
frac += (c - '0') / bases[pfrac];
++pfrac;
}
}
else
{
break;
}
}
if (!fail)
{
double f = dec + frac;
if (minus)
f = -f;
return f;
}
return 0.0;
}
void read_float_direct(const string& in)
{
double sum = 0.0;
size_t len = in.length();
const char* str = in.c_str();
for (size_t i=0; i<len; ++i)
{
double f = scan_float(str, i, len);
sum += f;
}
printf("scanned %f\n", sum);
}
int main()
{
const int n = 1000000;
printf("count = %d\n", n);
string in = test_generate(n);
{
struct timeval t1;
gettimeofday(&t1, 0);
printf("scan start\n");
read_float_ss(in);
struct timeval t2;
gettimeofday(&t2, 0);
double elapsed = (t2.tv_sec - t1.tv_sec) * 1000000.0;
elapsed += (t2.tv_usec - t1.tv_usec) / 1000.0;
printf("elapsed %.2fms\n", elapsed);
}
{
struct timeval t1;
gettimeofday(&t1, 0);
printf("scan start\n");
read_float_direct(in);
struct timeval t2;
gettimeofday(&t2, 0);
double elapsed = (t2.tv_sec - t1.tv_sec) * 1000000.0;
elapsed += (t2.tv_usec - t1.tv_usec) / 1000.0;
printf("elapsed %.2fms\n", elapsed);
}
return 0;
}
Ниже представлен вывод консоли i7 Mac Book Pro (скомпилирован в XCode 4.6).
count = 1000000
generated -1073202156466.638184
scan start
scanned -1073202156466.638184
elapsed 83.34ms
scan start
scanned -1073202156466.638184
elapsed 53.50ms