Построить массив на основе добавления и удаления строк событий в BigQuery
У меня есть таблица в BigQuery со следующей структурой:
datetime | event | value
==========================
1 | add | 1
---------+--------+-------
2 | remove | 1
---------+--------+-------
6 | add | 2
---------+--------+-------
8 | add | 3
---------+--------+-------
11 | add | 4
---------+--------+-------
23 | remove | 3
---------+--------+-------
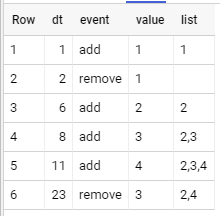
Я пытаюсь построить представление, которое добавляет list столбец для каждой строки, содержащей текущее состояние массива. Массив никогда не будет содержать повторяющиеся элементы. Это должно быть результатом:
datetime | event | value | list
===================================
1 | add | 1 | [1]
---------+--------+-------+--------
2 | remove | 1 | []
---------+--------+-------+--------
6 | add | 2 | [2]
---------+--------+-------+--------
8 | add | 3 | [2,3]
---------+--------+-------+--------
11 | add | 4 | [2,3,4]
---------+--------+-------+--------
23 | remove | 3 | [2,4]
---------+--------+-------+--------
Я пытался использовать аналитические функции, но это не сработало. API для работы с массивами довольно ограничен. Я думаю, я бы преуспел, если бы я мог использовать рекурсивный WITH пункты, к сожалению, это невозможно в BigQuery.
Я использую BigQuery с включенным стандартным SQL.
3 ответа
Ниже приведена версия для BigQuery Standard SQL и используется только чистый SQL (без JS UDF)
#standardSQL
WITH `project.dataset.events` AS (
SELECT 1 dt,'add' event,'1' value UNION ALL
SELECT 2, 'remove', '1' UNION ALL
SELECT 6, 'add', '2' UNION ALL
SELECT 8, 'add', '3' UNION ALL
SELECT 11, 'add', '4' UNION ALL
SELECT 23, 'remove', '3'
), cum AS (
SELECT dt, event, value,
SUM(IF(event = 'add', 1, -1)) OVER(PARTITION BY value ORDER BY dt) state
FROM `project.dataset.events`
), pre AS (
SELECT
a.dt, a.event, a.value, a.state, b.value AS b_value,
ARRAY_AGG(b.state ORDER BY b.dt DESC)[SAFE_OFFSET(0)] b_state,
MAX(b.dt) b_dt
FROM cum a
JOIN cum b ON b.dt <= a.dt
GROUP BY a.dt, a.event, a.value, a.state, b.value
)
SELECT dt, event, value,
SPLIT(IFNULL(STRING_AGG(IF(b_state = 1, b_value, NULL) ORDER BY b_dt), '')) list_as_array,
CONCAT('[', IFNULL(STRING_AGG(IF(b_state = 1, b_value, NULL) ORDER BY b_dt), ''), ']') list_as_string
FROM pre
GROUP BY dt, event, value
ORDER BY dt
результат "удивительно": о) точно такой же, как в версии для JS UDF, на которую я отвечал / выкладывал ранее
Row dt event value list_as_arr list_as_string
1 1 add 1 1 [1]
2 2 remove 1 []
3 6 add 2 2 [2]
4 8 add 3 2 [2,3]
3
5 11 add 4 2 [2,3,4]
3
4
6 23 remove 3 2 [2,4]
4
Примечание: я думаю, что выше может быть немного чрезмерно спроектировано - но у меня просто не было времени, чтобы потенциально отшлифовать / оптимизировать его - должно быть выполнимо - оставив это на усмотрение владельца вопроса
Ниже для BigQuery SQL (только один из потенциально многих вариантов)
#standardSQL
CREATE TEMP FUNCTION CUST_ARRAY_AGG(arr ARRAY<STRUCT<event STRING, value STRING>>)
RETURNS ARRAY<STRING>
LANGUAGE js AS """
var result = [];
for (i = 0; i < arr.length; i++) {
if (arr[i].event == 'add') {
result.push(arr[i].value);
} else {
var index = result.indexOf(arr[i].value);
if (index > -1) {
result.splice(index, 1);
}
}
}
return result;
""";
WITH `project.dataset.events` AS (
SELECT 1 dt, 'add' event, '1' value UNION ALL
SELECT 2, 'remove', '1' UNION ALL
SELECT 6, 'add', '2' UNION ALL
SELECT 8, 'add', '3' UNION ALL
SELECT 11, 'add', '4' UNION ALL
SELECT 23, 'remove', '3'
)
SELECT dt, event, value,
CUST_ARRAY_AGG(arr) list_as_arr,
(SELECT CONCAT('[', IFNULL(STRING_AGG(item), ''), ']') FROM UNNEST(CUST_ARRAY_AGG(arr)) item) list_as_string
FROM (
SELECT dt, event, value,
ARRAY_AGG(STRUCT<event STRING, value STRING>(event, value)) OVER(ORDER BY dt) arr
FROM `project.dataset.events`
)
с результатом, как показано ниже
Row dt event value list_as_arr list_as_string
1 1 add 1 1 [1]
2 2 remove 1 []
3 6 add 2 2 [2]
4 8 add 3 2 [2,3]
3
5 11 add 4 2 [2,3,4]
3
4
6 23 remove 3 2 [2,4]
4
Хотя уже решил, мне нравится проблема. Идея в этом решении состоит в том, чтобы сначала получить полную историю, используя управление окнами, принимая во внимание все предыдущие строки - и после этого удаляя remove-items:
#standardSQL
-- stolen test table ;)
WITH test AS (
SELECT 1 dt,'add' event,'1' value UNION ALL
SELECT 2, 'remove', '1' UNION ALL
SELECT 6, 'add', '2' UNION ALL
SELECT 8, 'add', '3' UNION ALL
SELECT 11, 'add', '4' UNION ALL
SELECT 23, 'remove', '3'
)
, windowing as (
SELECT *,
-- add history using window function
ARRAY_AGG(STRUCT(event, value)) OVER ( ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as history
FROM test)
SELECT
dt,
event,
value,
--history, -- for testing
-- Get all added items that are not removed items
-- This sub-select runs within the row only, treating history-array as (sub-)table
(SELECT ARRAY_AGG(value) value FROM unnest(t.history) l
WHERE l.event = 'add'
AND l.value NOT IN
(SELECT l.value FROM unnest(t.history) l WHERE l.event = 'remove')
) AS list
FROM windowing t
Я не сравнивал выступления, но мне было бы интересно!
Все оригинальные ответы великолепны (особенно мой - смеется) и в основном основаны на обработке на основе наборов (лучший способ справиться с большими данными), которая в таких случаях может стать достаточно сложной для пользователей, не являющихся sql!
К счастью, поддержка сценариев и хранимых процедур сейчас находится в стадии бета-тестирования (по состоянию на октябрь 2019 г.)
Вы можете отправить несколько операторов, разделенных точкой с запятой, и BigQuery теперь может их запускать. И гораздо проще выразить необходимую логику (очевидно, по крайней мере, по цене производительности) процедурным способом, а не на основе наборов, так что больше пользователей могут получить выгоду
Ниже скрипт реализует логику, выраженную в вопросе
DECLARE arr ARRAY<STRUCT<dt INT64, event STRING, value STRING>>;
DECLARE result ARRAY<STRUCT<dt INT64, event STRING, value STRING, list STRING>> DEFAULT [STRUCT(NULL, '', '', '')];
DECLARE list ARRAY<STRING> DEFAULT [];
DECLARE i, m INT64 DEFAULT -1;
SET arr = (
WITH t AS (
SELECT 1 dt,'add' event,'1' value UNION ALL
SELECT 2, 'remove', '1' UNION ALL
SELECT 6, 'add', '2' UNION ALL
SELECT 8, 'add', '3' UNION ALL
SELECT 11, 'add', '4' UNION ALL
SELECT 23, 'remove', '3'
)
SELECT ARRAY_AGG(t) FROM t
);
SET m = ARRAY_LENGTH(arr);
LOOP
SET i = i + 1;
IF i >= m THEN LEAVE;
ELSE
IF arr[OFFSET(i)].event = 'add' THEN
SET list = (
SELECT ARRAY_CONCAT(list, [arr[OFFSET(i)].value])
);
ELSE
SET list = ARRAY(
SELECT item
FROM UNNEST(list) item
WHERE item != arr[OFFSET(i)].value
);
END IF;
SET result = (
SELECT ARRAY_CONCAT(
result,
[(arr[OFFSET(i)].dt, arr[OFFSET(i)].event, arr[OFFSET(i)].value, ARRAY_TO_STRING(list, ','))]
)
);
END IF;
END LOOP;
SELECT * FROM UNNEST(result) WHERE NOT dt IS NULL;
с результатом