Linux AIO: плохое масштабирование
Я пишу библиотеку, которая использует системные вызовы асинхронного ввода / вывода Linux, и хотела бы знать, почему io_submit функция показывает плохое масштабирование в файловой системе ext4. Если возможно, что я могу сделать, чтобы получить io_submit не блокировать при больших размерах ввода-вывода? Я уже делаю следующее (как описано здесь):
- использование
O_DIRECT, - Выровняйте буфер ввода-вывода по границе 512 байт.
- Установите размер буфера, кратный размеру страницы.
Чтобы наблюдать, как долго ядро тратит io_submit, Я запустил тест, в котором я создал тестовый файл 1 Гб, используя dd а также /dev/urandomи неоднократно сбрасывал системный кеш (sync; echo 1 > /proc/sys/vm/drop_caches) и читайте все более крупные части файла. На каждой итерации я печатал время io_submit и время, потраченное на ожидание завершения запроса на чтение. Я провел следующий эксперимент на системе x86-64 под управлением Arch Linux с версией ядра 3.11. У машины есть SSD и процессор Core i7. На первом графике показано количество прочитанных страниц и время, потраченное на ожидание. io_submit заканчивать. На втором графике показано время, потраченное на ожидание завершения запроса на чтение. Время измеряется в секундах.

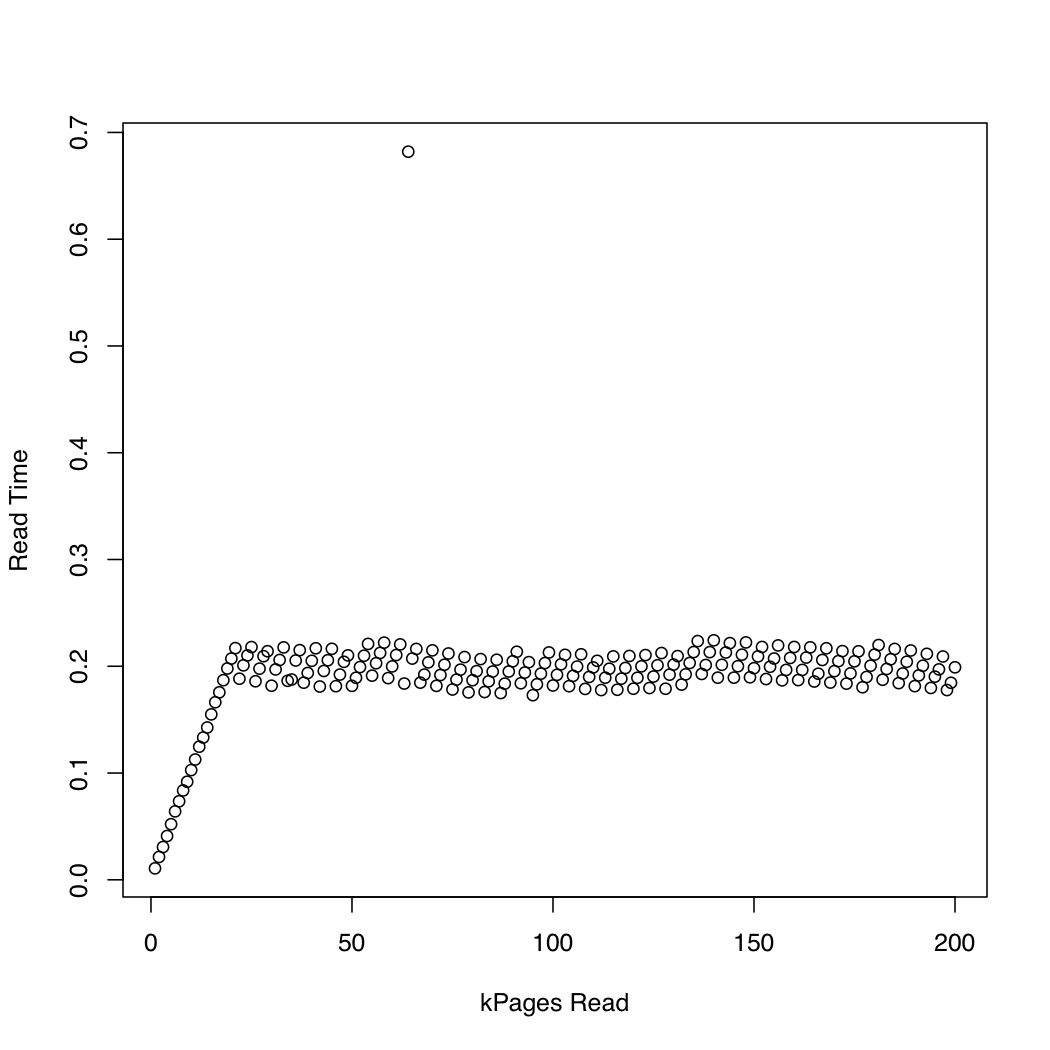
Для сравнения я создал аналогичный тест, который использует синхронный ввод-вывод с помощью pread, Вот результаты:
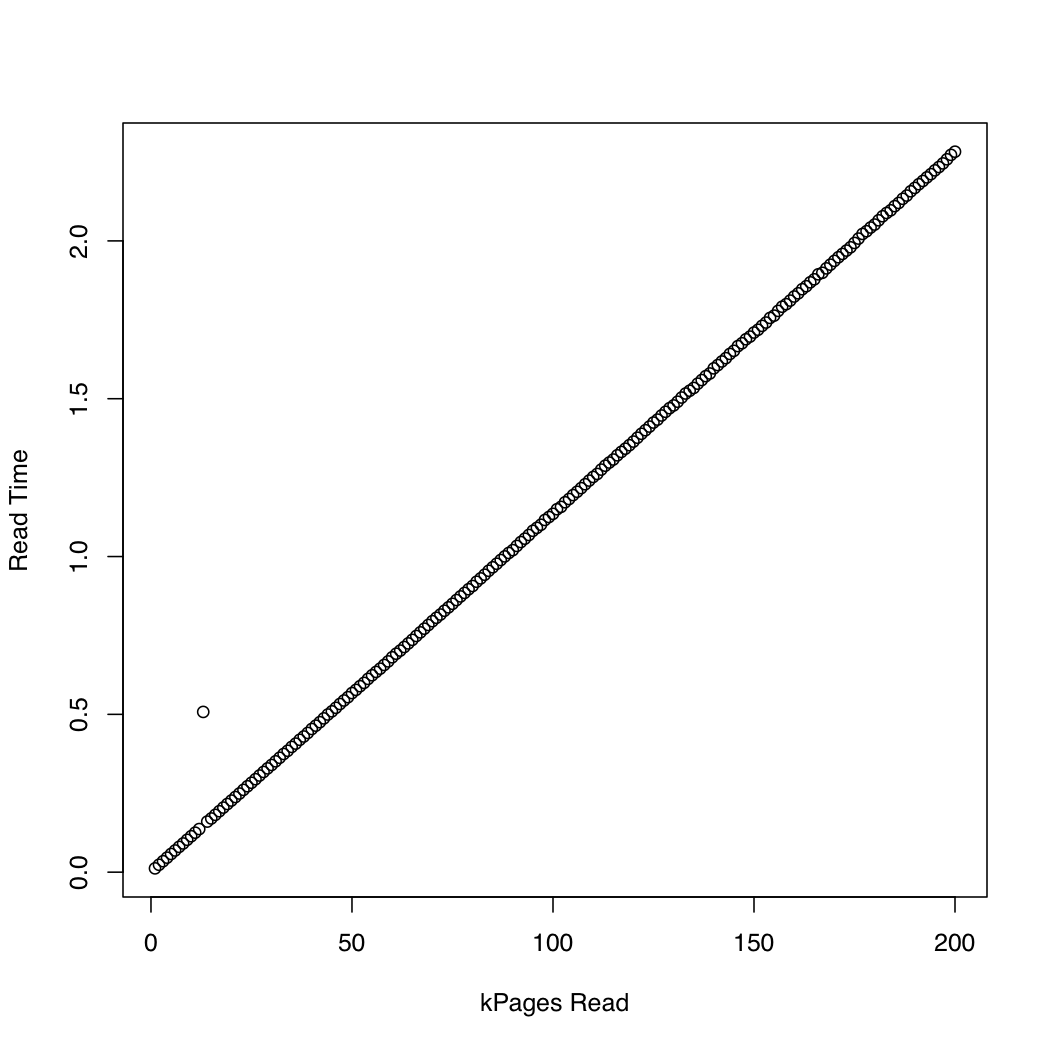
Кажется, что асинхронный ввод-вывод работает, как и ожидалось, до размеров запросов около 20000 страниц. После этого, io_submit блоки. Эти наблюдения приводят к следующим вопросам:
- Почему не время выполнения
io_submitпостоянная? - Что вызывает это плохое масштабирование?
- Нужно ли разбивать все запросы на чтение в файловых системах ext4 на несколько запросов, каждый размером менее 20000 страниц?
- Откуда эта "волшебная" ценность в 20000? Если я запускаю свою программу в другой системе Linux, как я могу определить наибольший размер запроса ввода-вывода, чтобы не испытывать плохого поведения при масштабировании?
Код, используемый для проверки асинхронного ввода-вывода, приведен ниже. Я могу добавить другие списки источников, если вы считаете, что они актуальны, но я постарался опубликовать только те детали, которые, по моему мнению, могут быть релевантными.
#include <cstddef>
#include <cstdint>
#include <cstring>
#include <chrono>
#include <iostream>
#include <memory>
#include <fcntl.h>
#include <stdio.h>
#include <time.h>
#include <unistd.h>
// For `__NR_*` system call definitions.
#include <sys/syscall.h>
#include <linux/aio_abi.h>
static int
io_setup(unsigned n, aio_context_t* c)
{
return syscall(__NR_io_setup, n, c);
}
static int
io_destroy(aio_context_t c)
{
return syscall(__NR_io_destroy, c);
}
static int
io_submit(aio_context_t c, long n, iocb** b)
{
return syscall(__NR_io_submit, c, n, b);
}
static int
io_getevents(aio_context_t c, long min, long max, io_event* e, timespec* t)
{
return syscall(__NR_io_getevents, c, min, max, e, t);
}
int main(int argc, char** argv)
{
using namespace std::chrono;
const auto n = 4096 * size_t(std::atoi(argv[1]));
// Initialize the file descriptor. If O_DIRECT is not used, the kernel
// will block on `io_submit` until the job finishes, because non-direct
// IO via the `aio` interface is not implemented (to my knowledge).
auto fd = ::open("dat/test.dat", O_RDONLY | O_DIRECT | O_NOATIME);
if (fd < 0) {
::perror("Error opening file");
return EXIT_FAILURE;
}
char* p;
auto r = ::posix_memalign((void**)&p, 512, n);
if (r != 0) {
std::cerr << "posix_memalign failed." << std::endl;
return EXIT_FAILURE;
}
auto del = [](char* p) { std::free(p); };
std::unique_ptr<char[], decltype(del)> buf{p, del};
// Initialize the IO context.
aio_context_t c{0};
r = io_setup(4, &c);
if (r < 0) {
::perror("Error invoking io_setup");
return EXIT_FAILURE;
}
// Setup I/O control block.
iocb b;
std::memset(&b, 0, sizeof(b));
b.aio_fildes = fd;
b.aio_lio_opcode = IOCB_CMD_PREAD;
// Command-specific options for `pread`.
b.aio_buf = (uint64_t)buf.get();
b.aio_offset = 0;
b.aio_nbytes = n;
iocb* bs[1] = {&b};
auto t1 = high_resolution_clock::now();
auto r = io_submit(c, 1, bs);
if (r != 1) {
if (r == -1) {
::perror("Error invoking io_submit");
}
else {
std::cerr << "Could not submit request." << std::endl;
}
return EXIT_FAILURE;
}
auto t2 = high_resolution_clock::now();
auto count = duration_cast<duration<double>>(t2 - t1).count();
// Print the wait time.
std::cout << count << " ";
io_event e[1];
t1 = high_resolution_clock::now();
r = io_getevents(c, 1, 1, e, NULL);
t2 = high_resolution_clock::now();
count = duration_cast<duration<double>>(t2 - t1).count();
// Print the read time.
std::cout << count << std::endl;
r = io_destroy(c);
if (r < 0) {
::perror("Error invoking io_destroy");
return EXIT_FAILURE;
}
}
2 ответа
Насколько я понимаю, очень немногие (если таковые имеются) файловые системы в Linux полностью поддерживают AIO. Некоторые операции с файловой системой все еще блокируются, а иногда io_submit() косвенно через операции файловой системы будет вызывать такие вызовы блокировки.
Кроме того, я понимаю, что основные пользователи ядра AIO в первую очередь заботятся о том, чтобы AIO был действительно асинхронным на необработанных блочных устройствах (т.е. без файловой системы). по существу, поставщики баз данных.
Вот соответствующий пост из списка рассылки linux-aio. ( глава потока)
Возможно полезная рекомендация:
Добавьте больше запросов через /sys/block/xxx/queue/nr_requests, и проблема станет лучше.
Почему время выполнения io_submit не является постоянным?
Поскольку вы отправляете очень большие операции ввода-вывода, блочный уровень должен разделить их, а затем поставить в очередь полученные запросы. Это может привести к ограничению ресурсов...
Что вызывает такое плохое масштабирование?
По мере того, как ввод-вывод становится больше (см. Ниже), количество разделений, выполняемых для ввода-вывода, чтобы превратить его в запросы подходящего размера, будет увеличиваться (предположительно, выполнение разделений также потребует небольшого количества времени). С прямым вводом / выводомio_submit()не возвращается, пока все его запросы не будут распределены на уровне блочного уровня. Кроме того, количество запросов, которые могут быть поставлены в очередь блочным уровнем для данного диска, ограничено до/sys/block/[disk_device]/queue/nr_requests. Превышение этого лимита приводит кio_submit()блокирование до тех пор, пока не будет освобождено достаточное количество слотов запросов, чтобы все его распределения были удовлетворены (это связано с рекомендациями Arvid).
Нужно ли мне разбивать все запросы чтения в файловых системах ext4 на несколько запросов, каждый размером менее 20000 страниц?
В идеале вы должны разделить свои запросы на гораздо меньшие количества, чем это - 20000 страниц (при условии, что страница размером 4096 байт, которая используется на платформах x86) составляет примерно 78 мегабайт! Это относится не только к тому, когда вы используете ext4 - делая такие большиеio_submit() Размеры ввода-вывода для других файловых систем или даже напрямую для блочных устройств вряд ли будут хорошо работать.
Если вы выясните, на каком диске находится ваша файловая система, и посмотрите на /sys/block/[disk_device]/queue/max_sectors_kb это даст вам верхнюю границу, но граница, с которой начинается разделение, может быть еще меньше, поэтому вы можете ограничить размер каждого ввода-вывода до /sys/block/[disk_device]/queue/max_segments * PAGE_SIZE вместо.
Откуда взялось это "волшебное" значение 20000?
Вероятно, это связано с некоторой комбинацией:
- Максимальный размер каждого ввода / вывода может быть до того, как блочный уровень разделит его (самое большее, это будет
/sys/block/[disk_device]/queue/max_sectors_kbно наблюдаемый предел разделения может быть еще ниже) - Максимальное количество операций ввода-вывода, которые могут быть поставлены в очередь до возникновения блокировки (
/sys/block/[disk_device]/queue/nr_requests) - Глубина очереди команд вашего оборудования (
/sys/block/[disk_device]/device/queue_depth) - Как быстро ваш диск выполняет запросы. Когда ядро не может поставить в очередь больше операций ввода-вывода, пока не будет достигнута глубина очереди реального устройства, оно блокирует новые запросы до тех пор, пока не будут выполнены текущие, отправленные на оборудование.
Если я запускаю свою программу в другой системе Linux, как я могу определить самый большой размер запроса ввода-вывода для использования, не испытывая плохого масштабирования?
Ограничьте каждый ввод-вывод запроса на меньшее из /sys/block/[disk_device]/queue/max_sectors_kb или /sys/block/[disk_device]/queue/max_segments * PAGE_SIZE. Я бы предположил, что операции ввода-вывода размером не более 524288 байт должны быть безопасными, но ваше оборудование может справиться с большим размером и, таким образом, получить более высокую пропускную способность, но, возможно, за счет задержки завершения (в отличие от отправки).
Если возможно, что я могу сделать, чтобы io_submit не блокировал большие размеры запросов ввода-вывода?
Будет верхний "хороший" предел, и если вы его превзойдете, будут последствия, которых вы не сможете избежать.
Связанные вопросы
Вам не хватает цели использования AIO в первую очередь. Приведенный пример показывает последовательность операций [fill-buffer], [write], [write], [write], ... [read], [read], [read], ... операций. По сути, вы вводите данные в трубу. В конце концов, канал заполняется, когда вы достигаете предела пропускной способности ввода-вывода для вашего хранилища. Теперь вы заняты ожиданием, которое показывает ваше линейное снижение производительности.
Прирост производительности для записи AIO заключается в том, что приложение заполняет буфер и затем сообщает ядру, что нужно начать операцию записи; управление немедленно возвращается в приложение, пока ядру все еще принадлежит буфер данных и его содержимое; пока ядро не сообщит о завершении ввода-вывода, приложение не должно касаться буфера данных, потому что вы еще не знаете, какая часть (если таковая имеется) буфера фактически попала на носитель: измените буфер до того, как ввод-вывод завершится. завершено, и вы повредили данные, поступающие на носитель.
И наоборот, выигрыш от чтения AIO происходит, когда приложение выделяет буфер ввода-вывода, а затем сообщает ядру, что нужно начинать заполнять буфер. Управление немедленно возвращается в приложение, и приложение должно оставить буфер в покое, пока ядро не сообщит, что оно завершило работу с буфером, отправив событие завершения ввода / вывода.
Таким образом, поведение, которое вы видите, является примером быстрого заполнения конвейера в хранилище. В конечном итоге данные генерируются быстрее, чем хранилище может поглотить данные, и производительность падает до линейности, а конвейер пополняется так же быстро, как и опустошается: линейное поведение.
Программа-пример использует вызовы AIO, но это все еще линейная программа остановки и ожидания.