Неожиданный вывод таблицы псевдонимов Walker с использованием ggplot2
Я использую R создать свою графику для таблиц псевдонимов Walker, которые я использую в своей диссертации. Мне удалось создать каждый график, используя ggplot2за исключением последнего, в котором значения псевдонимов расположены так, что вероятность в каждом столбце равна 1.
График с вероятностями, масштабированными до создания псевдонимов:
foo <- data.frame(Buscount=c(1,2,3,4,5), Rescaled.busfreq= c(5/9, 10/9, 15/9, 10/9, 5/9))
ggplot(foo, aes(x=factor(Buscount),y=Rescaled.busfreq, fill=factor(Buscount))) +
geom_bar(stat="identity", width=1) +
scale_fill_manual(values=c("cyan","magenta2","gold","gray","darkolivegreen3", "black")) +
scale_x_discrete(labels=c("a-2", "a-1", "a", "a+1", "a+2"), expand=c(0,0), name="Real count") +
scale_y_continuous(breaks=seq(0,15/9, by=3/9),labels=c("0", "3/9","6/9","9/9", "12/9", "15/9"), expand=c(0,0),
name="Adjusted probability of count") +
geom_rect(data=NULL, aes(xmin = 0.5, xmax = 5.5, ymin = 0, ymax = 9/9), color="black", fill=NA, size=1.5) +
geom_vline(xintercept=c(1.5, 2.5, 3.5, 4.5), color="gray") +
theme(panel.grid.minor.y=element_blank(),
panel.grid.major.y=element_line(color="gray"),
panel.background=element_blank(), legend.position="none",
axis.line = element_line(color="gray", size = 1))
Это дает желаемый результат: 
Я думал, что столбчатая диаграмма в ggplot2 было бы наиболее удобным способом вписать значения в плоскость 1 x 5, но я не могу заставить работать гистограмму с накоплением. Это код, с которым я столкнулся после нескольких попыток, и я создал новый data.frame, так как длины превышают те, что были в исходном data.frame. Чтобы не повторять данные Столбцы в данных Значений, данные Значений подставили A за a-2, B за a-1 и так далее. 0 являются заполнителями, поэтому ровно пять вероятностей вносят вклад в каждое значение столбца.
Final.Buscount.Alias <- data.frame(Values=rep(c("A","B", "C", "D", "E"), times=5))
Final.Buscount.Alias$Probabilities <- c(5/9,4/9,0,0,0, 0, 6/9, 0, 3/9,0, 0,0,9/9,0,0, 0,0,2/9,7/9,0, 0,0,4/9,0,5/9)
Final.Buscount.Alias$Columns <- rep(c("a-2","a-1", "a", "a+1", "a+2"), each=5)
ggplot(Final.Buscount.Alias, aes(x=factor(Columns),y=Probabilities, fill=factor(Values))) +
geom_bar(stat="identity", width=1) +
scale_fill_manual(values=c("cyan","magenta2","gold","gray","darkolivegreen3", "black")) +
scale_x_discrete(labels=c("a-2", "a-1", "a", "a+1", "a+2"), expand=c(0,0), name="Real count") +
scale_y_continuous(breaks=seq(0,15/9, by=3/9),labels=c("0", "3/9","6/9","9/9", "12/9", "15/9"), expand=c(0,0),
name="Probabilities including alias") +
geom_rect(data=NULL, aes(xmin = 0.5, xmax = 5.5, ymin = 0, ymax = 9/9), color="black", fill=NA, size=1.5) +
geom_vline(xintercept=c(1.5, 2.5, 3.5, 4.5), color="gray") +
theme(panel.grid.minor.y=element_blank(),
panel.grid.major.y=element_line(color="gray"),
panel.background=element_blank(), legend.position="none",
axis.line = element_line(color="gray", size = 1))
Это производит график 
Но цвета кажутся правильными, но есть некоторые проблемы. Бар для a-1 единственный правильный. Бар в a-2 должен быть в aБар в a должен быть в a-2, a+1 а также a+2 являются почти правильными, хотя, строго говоря, порядок столбцов внутри столбцов должен быть обратным. График, который я пытаюсь создать, - это график, который я создал вручную в Excel:

Там, кажется, порядок внутри ggplot2 что я не понимаю
Я читал некоторые решения для гистограмм с накоплением здесь, здесь, здесь, здесь и здесь, но я не могу понять, что я делаю неправильно.
1 ответ
Я думаю, что ключевой вопрос, который у вас возник, связан с тем, как установить порядок для факторных переменных в R. factor(Columns) или же factor(Values) преобразует эти столбцы в коэффициенты, но порядок по умолчанию в алфавитном порядке. (Чтобы получить другой порядок, вам нужно явно установить порядок с помощью levels аргумент, как описано ниже.) Это означает, что factor(Columns) устанавливает порядок a, a-1, a-2, a+1, a+2. scale_x_discrete просто перемаркирует ось х, но не меняет базовые данные. Вот почему самый левый столбец выглядел как столбец a (потому что это все еще были данные в a) но был помечен как a-2,
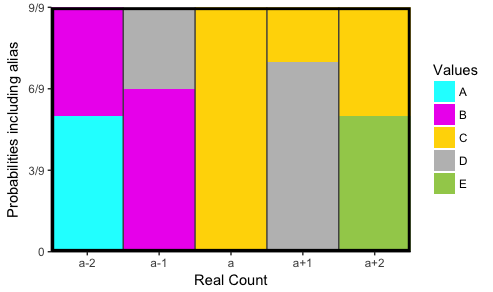
Способ получить заказ вы хотите использовать factor функция, но явно указать порядок с помощью levels аргумент. В этом случае мы хотим порядок Columns идти от a-2 в a+2, Чтобы получить сложенные бары в правильном порядке, нам нужно B прийти раньше A, а также D прийти раньше B, Но тогда мы также должны двигаться C так что он продолжает приходить раньше D, Итак, окончательный заказ на Values это C,D,B,A,E, которые мы можем ввести непосредственно c("C","D","B","A","E") или код со встроенным LETTERS вектор: LETTERS[c(3,4,2,1,5)], Я настроил ваши данные с правильными порядками ниже.
Я не знаю, хотите ли вы легенду, но если вы это сделаете: по умолчанию легенда будет упорядочена в соответствии с порядком факторов. Но потому что Values буквы, вы можете их упорядочить в алфавитном порядке. Если так, установите breaks=LETTERS[1:5] в scale_fill_manual (что я сделал ниже). Это меняет порядок в легенде, без изменения порядка факторов на графике.
Кроме того, я пометил цветовой вектор в scale_fill_manual чтобы убедиться, что желаемые цвета назначены для каждого уровня Values (Я оставил там "черный", но он не используется на графике, как указано). Я сделал несколько других изменений в кодировке: Например, geom_col вместо geom_bar чтобы избежать необходимости stat="identity"; удален geom_rect и вместо этого используется theme установить шире panel.border,
library(ggplot2)
Final.Buscount.Alias <- data.frame(Values=rep(c("A","B", "C", "D", "E"), times=5))
Final.Buscount.Alias$Values = factor(Final.Buscount.Alias$Values,
levels=LETTERS[c(3,4,2,1,5)])
Final.Buscount.Alias$Probabilities <- c(5/9,4/9,0,0,0, 0, 6/9, 0, 3/9,0, 0,0,9/9,0,0, 0,0,2/9,7/9,0, 0,0,4/9,0,5/9)
Final.Buscount.Alias$Columns <- rep(c("a-2","a-1", "a", "a+1", "a+2"), each=5)
Final.Buscount.Alias$Columns = factor(Final.Buscount.Alias$Columns,
levels=unique(Final.Buscount.Alias$Columns))
ggplot(Final.Buscount.Alias, aes(x=Columns, y=Probabilities, fill=Values)) +
geom_col(width=1) +
scale_fill_manual(values=c(A="cyan",B="magenta2",C="gold",D="gray",E="darkolivegreen3", "black"), breaks=LETTERS[1:5]) +
scale_x_discrete(expand=c(0,0)) +
scale_y_continuous(breaks=seq(0, 15/9, by=3/9),
labels=c("0", paste0(seq(3,15,3),"/9")),
expand=c(0,0)) +
geom_vline(xintercept=c(1.5, 2.5, 3.5, 4.5), color="gray30") + # Darkened this to make it obvious where the lines are. Remove this line of code if you want the colors to abut each other.
labs(x="Real Count", y="Probabilities including alias") +
theme(panel.border=element_rect(size=2, fill=NA))