Как проверить, пустой ли искровой фрейм
Прямо сейчас я должен использовать df.count > 0, чтобы проверить, пуст ли фрейм данных или нет. Но это неэффективно. Есть ли лучший способ сделать это.
Благодарю.
PS: я хочу проверить, пусто ли это, так что я сохраняю только фрейм данных, если он не пустой
18 ответов
Для Spark 2.1.0 я бы предложил использовать head(n: Int) или же take(n: Int) с isEmptyв зависимости от того, кто из вас имеет самое ясное намерение.
df.head(1).isEmpty
df.take(1).isEmpty
с эквивалентом Python:
len(df.head(1)) == 0 # or bool(df.head(1))
len(df.take(1)) == 0 # or bool(df.take(1))
С помощью df.first() а также df.head() оба вернут java.util.NoSuchElementException если DataFrame пуст. first() звонки head() напрямую, который вызывает head(1).head,
def first(): T = head()
def head(): T = head(1).head
head(1) возвращает массив, так что принимая head на этом массиве вызывает java.util.NoSuchElementException когда DataFrame пуст.
def head(n: Int): Array[T] = withAction("head", limit(n).queryExecution)(collectFromPlan)
Так что вместо звонка head()использовать head(1) непосредственно, чтобы получить массив, а затем вы можете использовать isEmpty,
take(n) также эквивалентно head(n)...
def take(n: Int): Array[T] = head(n)
А также limit(1).collect() эквивалентно head(1) (уведомление limit(n).queryExecution в head(n: Int) метод), так что все следующее эквивалентно, по крайней мере из того, что я могу сказать, и вам не придется ловить java.util.NoSuchElementException исключение, когда DataFrame пуст.
df.head(1).isEmpty
df.take(1).isEmpty
df.limit(1).collect().isEmpty
Я знаю, что это старый вопрос, поэтому, надеюсь, он поможет кому-то использовать более новую версию Spark.
Я бы сказал, чтобы просто взять основную RDD, В Скала:
df.rdd.isEmpty
в Python:
df.rdd.isEmpty()
Это, как говорится, все, что это делает, это позвонить take(1).lengthтак что он будет делать то же самое, что ответил Рохан... может быть, чуть более явно?
У меня был тот же вопрос, и я протестировал 3 основных решения:
- df!=null df.count>0
- df.head(1).isEmpty() как @hulin003 предлагает
- df.rdd.isEmpty, как предлагает @Justin Pihony
и, конечно же, эти 3 работы, однако с точки зрения перферманса, вот что я обнаружил при выполнении этих методов на одном и том же DF на моей машине во время выполнения:
- занимает ~9366 мс
- занимает ~5607 мс
- это занимает ~1921 мс
поэтому я думаю, что лучшим решением является df.rdd.isEmpty, как предлагает @Justin Pihony
Начиная с Spark 2.4.0 есть Dataset.isEmpty,
Это реализация:
def isEmpty: Boolean =
withAction("isEmpty", limit(1).groupBy().count().queryExecution) { plan =>
plan.executeCollect().head.getLong(0) == 0
}
Обратите внимание, что DataFrame больше не является классом в Scala, это просто псевдоним типа (вероятно, измененный в Spark 2.0):
type DataFrame = Dataset[Row]
Вы можете воспользоваться head() (или же first()), чтобы увидеть, если DataFrame имеет один ряд. Если так, это не пусто.
Метод isEmpty() для DataFrames представлен в Spark версии 2.4. Поэтому лучший способ проверить, пуст ли DataFrame в любой версии Spark версии 2.4 или выше, - использовать функцию isEmpty()
df.isEmpty()
Если вы делаете "df.count > 0". Он берет подсчет всех разделов всех исполнителей и добавляет их в Driver. Это займет некоторое время, когда вы имеете дело с миллионами строк.
Лучший способ сделать это - выполнить "df.take(1)" и проверить, имеет ли оно значение null. Это вернет "java.util.NoSuchElementException", так что лучше попробовать "df.take(1)".
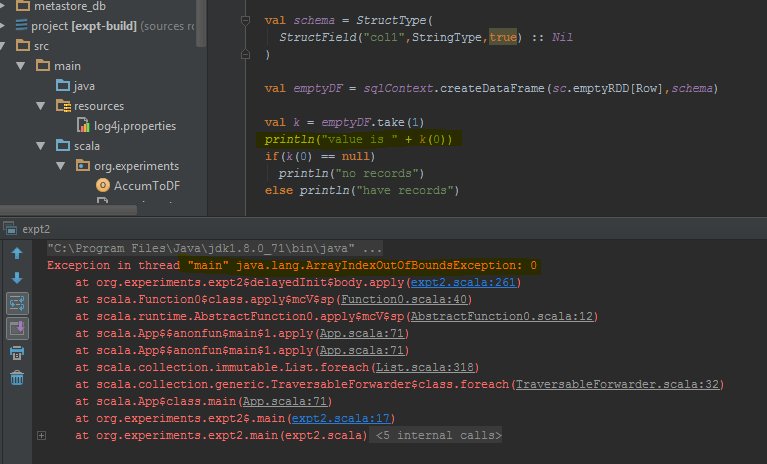
Фрейм данных возвращает ошибку при выполнении take (1) вместо пустой строки. Я выделил конкретные строки кода, где он выдает ошибку.
Если вы используете Pypsark, вы также можете сделать:
len(df.head(1)) > 0
Для пользователей Java вы можете использовать это в наборе данных:
public boolean isDatasetEmpty(Dataset<Row> ds) {
boolean isEmpty;
try {
isEmpty = ((Row[]) ds.head(1)).length == 0;
} catch (Exception e) {
return true;
}
return isEmpty;
}
Это проверка всех возможных сценариев (пусто, ноль).
В Scala вы можете использовать имплициты для добавления методов isEmpty() а также nonEmpty() к API DataFrame, который сделает код более приятным для чтения.
object DataFrameExtensions {
implicit def extendedDataFrame(dataFrame: DataFrame): ExtendedDataFrame =
new ExtendedDataFrame(dataFrame: DataFrame)
class ExtendedDataFrame(dataFrame: DataFrame) {
def isEmpty(): Boolean = {
Try{dataFrame.first.length != 0} match {
case Success(_) => false
case Failure(_) => true
}
}
def nonEmpty(): Boolean = !isEmpty
}
}
Здесь могут быть добавлены и другие методы. Чтобы использовать неявное преобразование, используйте import DataFrameExtensions._ в файле вы хотите использовать расширенный функционал. Впоследствии методы могут быть использованы напрямую, так что:
val df: DataFrame = ...
if (df.isEmpty) {
// Do something
}
На PySpark вы также можете использовать это bool(df.head(1)) чтобы получить True из False стоимость
Возвращается False если датафрейм не содержит строк
Я обнаружил, что в некоторых случаях:
>>>print(type(df))
<class 'pyspark.sql.dataframe.DataFrame'>
>>>df.take(1).isEmpty
'list' object has no attribute 'isEmpty'
это то же самое для "длины" или замените take() на head ()
[Решение] для проблемы, которую мы можем использовать.
>>>df.limit(2).count() > 1
False
Если вы хотите только узнать, пусто ли, тоdf.isEmpty,df.head(1).isEmpty()илиdf.rdd.isEmpty()должно работать, они занимаютlimit(1)если выexamineих:
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[count(1)], output=[count#52L])
+- *(2) HashAggregate(keys=[], functions=[partial_count(1)], output=[count#60L])
+- *(2) GlobalLimit 1
+- Exchange SinglePartition
+- *(1) LocalLimit 1
... // the rest of the plan related to your computation
Но если вы выполняете какие-то другие вычисления, требующие много памяти, и вы не хотите кэшировать своиDataFrameпросто чтобы проверить, пуст ли он, вы можете использовать аккумулятор:
def accumulateRows(acc: LongAccumulator)(df: DataFrame): DataFrame =
df.map { row => // we map to the same row, count during this map
acc.add(1)
row
}(RowEncoder(df.schema))
val rowAccumulator = spark.sparkContext.longAccumulator("Row Accumulator")
val countedDF = df.transform(accumulateRows(rowAccumulator))
countedDF.write.saveAsTable(...) // main action
val isEmpty = rowAccumulator.isZero
Обратите внимание, что для просмотра количества строк необходимо сначала выполнить действие. Если мы изменим порядок последних двух строк,isEmptyбудетtrueвне зависимости от расчета.
Мой случай был немного другим, и я хочу поделиться им со всеми вами. Мой Dataframe был доставлен пустым, однако там была запись с нулевым значением. Кадр данных считается пустым, но на самом деле это не так. Поэтому я написал приведенный ниже код как решение моей проблемы.
Моя проблема: когда я выпускаюdf.count()я не понимаю0но одна запись с нулевыми значениями. Если я выпущуdf.rdd.isEmpty()я получилFalse.
Решение:
from pyspark.sql.functions import col,when
def isDfEmpty(df):
if df.count() == 1: #When df has only one record
_df_ = df.select([when(col(c)=="",None).otherwise(col(c)).alias(c) for c in df.columns]).na.drop('all')
return(_df_.rdd.isEmpty())
else:
return False
isDfEmpty(df) #Replace df with your respective dataframe variable
Примечание. В моем случае я получил только одну запись в пустом кадре данных. Если это не так, пожалуйста, пересмотритеifсостояние.
Вы можете сделать это как:
val df = sqlContext.emptyDataFrame
if( df.eq(sqlContext.emptyDataFrame) )
println("empty df ")
else
println("normal df")
Предположим, у нас есть следующий пустой фрейм данных:
df = spark.sql("show tables").limit(0)
Если вы используете Spark 2.1 для pyspark, чтобы проверить, пуст ли этот фрейм данных, вы можете использовать:
df.count() > 0
Или же
bool(df.head(1))
df1.take(1).length>0
take Метод возвращает массив строк, поэтому, если размер массива равен нулю, записей в df,
dataframe.limit(1).count > 0
Это также запускает задание, но поскольку мы выбираем одну запись, даже в случае записи в миллиард масштабов затраты времени могут быть намного ниже.