Что означает " 2>&1 " в оболочке?
В оболочке Unix, если я хочу объединить stderr а также stdout в stdout Поток для дальнейшей манипуляции, я могу добавить следующее в конце моей команды:
2>&1
Итак, если я хочу использовать head на выходе из g++Я могу сделать что-то вроде этого:
g++ lots_of_errors 2>&1 | head
так что я вижу только первые несколько ошибок.
У меня всегда возникают проблемы с запоминанием этого, и мне постоянно приходится искать его, и это главным образом потому, что я не полностью понимаю синтаксис этого конкретного трюка.
Может кто-то разбить это и объяснить символ за символом, что 2>&1 средства?
19 ответов
Файловый дескриптор 1 является стандартным выводом (stdout).
Файловый дескриптор 2 является стандартной ошибкой (stderr).
Вот один из способов запомнить эту конструкцию (хотя она не совсем точна): сначала 2>1 может выглядеть как хороший способ перенаправления stderr в stdout, Однако на самом деле это будет интерпретироваться как "перенаправление stderr в файл с именем 1". & указывает, что то, что следует, является дескриптором файла, а не именем файла. Таким образом, конструкция становится: 2>&1,
echo test > afile.txt
перенаправляет стандартный вывод на afile.txt, Это то же самое, что делать
echo test 1> afile.txt
Чтобы перенаправить stderr, вы делаете:
echo test 2> afile.txt
>& это синтаксис для перенаправления потока в другой дескриптор файла - 0 - это стандартный ввод, 1 - стандартный вывод, а 2 - стандартный вывод.
Вы можете перенаправить стандартный вывод на стандартный вывод, выполнив:
echo test 1>&2 # or echo test >&2
Или наоборот:
echo test 2>&1
Итак, короче... 2> перенаправляет stderr в (неопределенный) файл, добавляя &1 перенаправляет stderr на стандартный вывод.
Некоторые хитрости о перенаправлении
Некоторые особенности синтаксиса могут иметь важные особенности. Есть несколько небольших примеров о перенаправлениях, STDERR, STDOUT и аргументы упорядочения.
1 - перезаписать или добавить?
Условное обозначение > значит перенаправление.
>означает отправку как завершенный файл, перезаписывая цель, если существует (см.noclobberособенность bash на #3 позже).>>означает отправить в дополнение к добавлению к цели, если существует.
В любом случае файл будет создан, если они не существуют.
2 - командная строка оболочки зависит от порядка!!
Для проверки нам нужна простая команда, которая отправит что-то на оба вывода:
$ ls -ld /tmp /tnt
ls: cannot access /tnt: No such file or directory
drwxrwxrwt 118 root root 196608 Jan 7 11:49 /tmp
$ ls -ld /tmp /tnt >/dev/null
ls: cannot access /tnt: No such file or directory
$ ls -ld /tmp /tnt 2>/dev/null
drwxrwxrwt 118 root root 196608 Jan 7 11:49 /tmp
(Ожидая, что у вас нет каталога с именем /tnt, конечно;). Ну, у нас это есть!!
Итак, давайте посмотрим:
$ ls -ld /tmp /tnt >/dev/null
ls: cannot access /tnt: No such file or directory
$ ls -ld /tmp /tnt >/dev/null 2>&1
$ ls -ld /tmp /tnt 2>&1 >/dev/null
ls: cannot access /tnt: No such file or directory
Последние дампы командной строки STDERR на консоль, и это, кажется, не ожидаемое поведение... Но...
Если вы хотите сделать некоторую пост-фильтрацию для одного выхода, другого или обоих:
$ ls -ld /tmp /tnt | sed 's/^.*$/<-- & --->/'
ls: cannot access /tnt: No such file or directory
<-- drwxrwxrwt 118 root root 196608 Jan 7 12:02 /tmp --->
$ ls -ld /tmp /tnt 2>&1 | sed 's/^.*$/<-- & --->/'
<-- ls: cannot access /tnt: No such file or directory --->
<-- drwxrwxrwt 118 root root 196608 Jan 7 12:02 /tmp --->
$ ls -ld /tmp /tnt >/dev/null | sed 's/^.*$/<-- & --->/'
ls: cannot access /tnt: No such file or directory
$ ls -ld /tmp /tnt >/dev/null 2>&1 | sed 's/^.*$/<-- & --->/'
$ ls -ld /tmp /tnt 2>&1 >/dev/null | sed 's/^.*$/<-- & --->/'
<-- ls: cannot access /tnt: No such file or directory --->
Обратите внимание, что последняя командная строка в этом абзаце точно такая же, как и в предыдущем абзаце, где я написал , что это не ожидаемое поведение (так что это может быть даже ожидаемое поведение).
Ну, есть несколько хитростей по поводу перенаправлений для выполнения разных операций на обоих выходах:
$ ( ls -ld /tmp /tnt | sed 's/^/O: /' >&9 ) 9>&2 2>&1 | sed 's/^/E: /'
O: drwxrwxrwt 118 root root 196608 Jan 7 12:13 /tmp
E: ls: cannot access /tnt: No such file or directory
Nota: &9 дескриптор будет происходить спонтанно из-за ) 9>&2,
Приложение: нота! С новой версией bash (>4.0) есть новая функция и более привлекательный синтаксис для таких вещей:
$ ls -ld /tmp /tnt 2> >(sed 's/^/E: /') > >(sed 's/^/O: /')
O: drwxrwxrwt 17 root root 28672 Nov 5 23:00 /tmp
E: ls: cannot access /tnt: No such file or directory
И, наконец, для такого каскадного форматирования вывода:
$ ((ls -ld /tmp /tnt |sed 's/^/O: /' >&9 ) 2>&1 |sed 's/^/E: /') 9>&1| cat -n
1 O: drwxrwxrwt 118 root root 196608 Jan 7 12:29 /tmp
2 E: ls: cannot access /tnt: No such file or directory
Приложение: нота! Тот же новый синтаксис, в обоих направлениях:
$ cat -n <(ls -ld /tmp /tnt 2> >(sed 's/^/E: /') > >(sed 's/^/O: /'))
1 O: drwxrwxrwt 17 root root 28672 Nov 5 23:00 /tmp
2 E: ls: cannot access /tnt: No such file or directory
куда STDOUT пройти определенный фильтр, STDERR к другому и, наконец, оба слитых выхода проходят через третий фильтр команд.
3 - Слово о noclobber вариант и >| синтаксис
Это о перезаписи:
В то время как set -o noclobber дать команду bash не перезаписывать какой-либо существующий файл, >| синтаксис позволяет пройти через это ограничение:
$ testfile=$(mktemp /tmp/testNoClobberDate-XXXXXX)
$ date > $testfile ; cat $testfile
Mon Jan 7 13:18:15 CET 2013
$ date > $testfile ; cat $testfile
Mon Jan 7 13:18:19 CET 2013
$ date > $testfile ; cat $testfile
Mon Jan 7 13:18:21 CET 2013
Файл перезаписывается каждый раз, ну а теперь:
$ set -o noclobber
$ date > $testfile ; cat $testfile
bash: /tmp/testNoClobberDate-WW1xi9: cannot overwrite existing file
Mon Jan 7 13:18:21 CET 2013
$ date > $testfile ; cat $testfile
bash: /tmp/testNoClobberDate-WW1xi9: cannot overwrite existing file
Mon Jan 7 13:18:21 CET 2013
Пройти через >|:
$ date >| $testfile ; cat $testfile
Mon Jan 7 13:18:58 CET 2013
$ date >| $testfile ; cat $testfile
Mon Jan 7 13:19:01 CET 2013
Отключение этой опции и / или запрос, если он уже установлен.
$ set -o | grep noclobber
noclobber on
$ set +o noclobber
$ set -o | grep noclobber
noclobber off
$ date > $testfile ; cat $testfile
Mon Jan 7 13:24:27 CET 2013
$ rm $testfile
4 - Последний трюк и многое другое...
Для перенаправления обоих выходных данных из данной команды мы видим, что правильный синтаксис может быть:
$ ls -ld /tmp /tnt >/dev/null 2>&1
для этого особого случая есть сокращенный синтаксис: &>... или же >&
$ ls -ld /tmp /tnt &>/dev/null
$ ls -ld /tmp /tnt >&/dev/null
Примечание: если 2>&1 существовать, 1>&2 правильный синтаксис тоже:
$ ls -ld /tmp /tnt 2>/dev/null 1>&2
4b- Теперь я дам вам подумать о:
$ ls -ld /tmp /tnt 2>&1 1>&2 | sed -e s/^/++/
++/bin/ls: cannot access /tnt: No such file or directory
++drwxrwxrwt 193 root root 196608 Feb 9 11:08 /tmp/
$ ls -ld /tmp /tnt 1>&2 2>&1 | sed -e s/^/++/
/bin/ls: cannot access /tnt: No such file or directory
drwxrwxrwt 193 root root 196608 Feb 9 11:08 /tmp/
4c- Если вы заинтересованы в дополнительной информации
Вы можете прочитать прекрасное руководство, нажав:
man -Len -Pless\ +/^REDIRECTION bash
в консоли bash;-)
Я нашел этот блестящий пост о перенаправлении: Все о перенаправлениях
Перенаправить как стандартный вывод, так и стандартную ошибку в файл
$ command &>file
Этот однострочник использует &> оператор для перенаправления обоих потоков вывода - stdout и stderr - из команды в файл. Это ярлык Bash для быстрого перенаправления обоих потоков в одно и то же место.
Вот как выглядит таблица файловых дескрипторов после того, как Bash перенаправил оба потока:
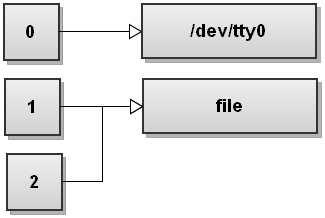
Как вы можете видеть, и stdout, и stderr теперь указывают на file, Таким образом, все, что написано в stdout и stderr, записывается в file,
Есть несколько способов перенаправить оба потока в один и тот же пункт назначения. Вы можете перенаправить каждый поток один за другим:
$ command> file 2>&1
Это гораздо более распространенный способ перенаправления обоих потоков в файл. Сначала stdout перенаправляется в файл, а затем stderr дублируется, чтобы быть таким же, как stdout. Таким образом, оба потока в конечном итоге указывают на file,
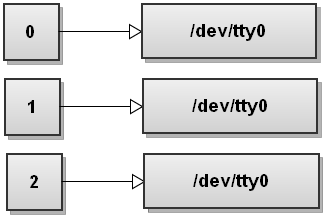
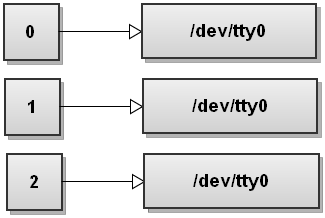
Когда Bash видит несколько перенаправлений, он обрабатывает их слева направо. Давайте пройдемся по шагам и посмотрим, как это происходит. Перед выполнением каких-либо команд таблица дескрипторов файлов Bash выглядит следующим образом:
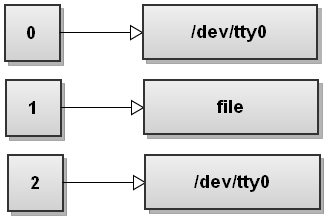
Теперь Bash обрабатывает первый файл перенаправления>. Мы видели это раньше, и это превращает стандартный вывод в файл:
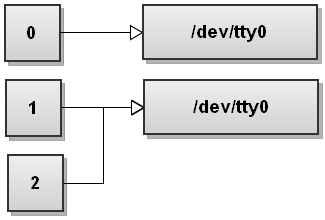
Далее Bash видит второе перенаправление 2>&1. Мы не видели этого перенаправления раньше. Этот дубликат файлового дескриптора 2 является копией файлового дескриптора 1, и мы получаем:
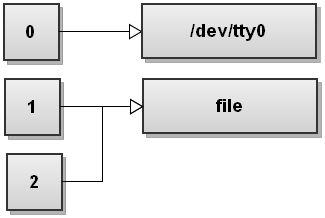
Оба потока были перенаправлены в файл.
Однако будьте осторожны здесь! Пишу
команда> файл 2>&1
это не то же самое, что писать:
$ command 2>&1> file
Порядок переадресации имеет значение в Bash! Эта команда перенаправляет только стандартный вывод в файл. Stderr все еще будет печатать на терминал. Чтобы понять, почему это происходит, давайте снова пройдемся по шагам. Поэтому перед запуском команды таблица дескрипторов файлов выглядит следующим образом:
Теперь Bash обрабатывает перенаправления слева направо. Сначала он видит 2>&1, поэтому дублирует stderr в stdout. Таблица дескрипторов файлов становится:
Теперь Bash видит второе перенаправление, >fileи перенаправляет стандартный вывод в файл:
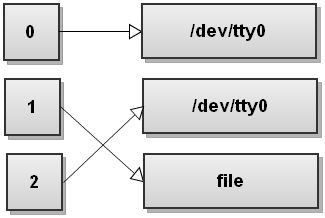
Вы видите, что здесь происходит? Stdout теперь указывает на файл, но stderr по-прежнему указывает на терминал! Все, что записывается в stderr, все равно выводится на экран! Так что будьте очень, очень осторожны с порядком перенаправлений!
Также обратите внимание, что в Bash пишется
$ command &>file
точно так же, как:
$ command> & file
Числа относятся к дескрипторам файлов (fd).
- Ноль
stdin - Один
stdout - Два это
stderr
2>&1 перенаправляет FD 2 на 1.
Это работает для любого числа файловых дескрипторов, если программа использует их.
Вы можете посмотреть на /usr/include/unistd.h если вы забудете их:
/* Standard file descriptors. */
#define STDIN_FILENO 0 /* Standard input. */
#define STDOUT_FILENO 1 /* Standard output. */
#define STDERR_FILENO 2 /* Standard error output. */
Тем не менее, я написал инструменты C, которые используют нестандартные файловые дескрипторы для пользовательской регистрации, поэтому вы не увидите его, если не перенаправите его в файл или что-то еще.
Я нашел это очень полезным, если вы новичок, прочтите это
Обновление:
в системе Linux или Unix есть два места, куда программы отправляют вывод: стандартный вывод (stdout) и стандартная ошибка (stderr). Вы можете перенаправить этот вывод в любой файл.
Как, если ты это сделаешьls -a > output.txt
Ничего не будет напечатано в консоли, весь вывод (stdout) перенаправляется в выходной файл.
И если вы попытаетесь распечатать содержимое любого файла, который не выходит, это означает, что вывод будет ошибкой, как если бы вы распечатали test.txt, которого нет в текущем каталоге.
cat test.txt > error.txt
Выход будет
cat: test.txt :No such file or directory
Но файл error.txt будет пустым, потому что мы перенаправляем stdout в файл, а не в stderr.
поэтому нам нужен дескриптор файла (дескриптор файла - это не что иное, как положительное целое число, представляющее открытый файл. Вы можете сказать, что дескриптор - это уникальный идентификатор файла), чтобы сообщить оболочке, какой тип вывода мы отправляем в файл. В системе Unix /Linux 1 для стандартного вывода и 2 для стандартного вывода.
так что теперь, если вы сделаете это
ls -a 1> output.txtозначает, что вы отправляете стандартный вывод (stdout) в output.txt.
и если вы сделаете этоcat test.txt 2> error.txt означает, что вы отправляете стандартную ошибку (stderr) в error.txt .
&1используется для ссылки на значение дескриптора файла 1 (stdout).
Теперь к делу2>&1означает "Перенаправить stderr в то же место, где мы перенаправляем stdout".
Теперь вы можете сделать это
cat maybefile.txt > output.txt 2>&1
как стандартный вывод (stdout), так и стандартная ошибка (stderr) будут перенаправлены на output.txt.
Спасибо Ondrej K.. за указание
Эта конструкция отправляет стандартный поток ошибок (stderr) к текущему местоположению стандартного выхода (stdout) - эта проблема с валютой, похоже, игнорировалась другими ответами.
С помощью этого метода вы можете перенаправить любой выходной дескриптор на другой, но чаще всего он используется для канала stdout а также stderr потоки в единый поток для обработки.
Вот некоторые примеры:
# Look for ERROR string in both stdout and stderr.
foo 2>&1 | grep ERROR
# Run the less pager without stderr screwing up the output.
foo 2>&1 | less
# Send stdout/err to file (with append) and terminal.
foo 2>&1 |tee /dev/tty >>outfile
# Send stderr to normal location and stdout to file.
foo >outfile1 2>&1 >outfile2
Обратите внимание, что последний не будет прямым stderr в outfile2 - это перенаправляет на что stdout был когда аргумент был встречен (outfile1), а затем перенаправляет stdout в outfile2,
Это допускает некоторые довольно сложные хитрости.
2 - стандартная ошибка консоли.
1 - стандартный вывод консоли.
Это стандартный Unix, и Windows также следует POSIX.
Например, когда вы бежите
perl test.pl 2>&1
стандартная ошибка перенаправляется на стандартный вывод, поэтому вы можете видеть оба выхода вместе:
perl test.pl > debug.log 2>&1
После выполнения вы можете увидеть все выходные данные, включая ошибки, в файле debug.log.
perl test.pl 1>out.log 2>err.log
Затем стандартный вывод идет в out.log, а стандартная ошибка в err.log.
Я предлагаю вам попытаться понять это.
2>&1 является оболочкой POSIX Вот разбивка, токен по токену:
2: Дескриптор выходного файла " Стандартная ошибка ".
>&: Дублирование оператора дескриптора выходного файла (вариант оператора перенаправления вывода >). Дано [x]>&[y] дескриптор файла обозначен x сделано, чтобы быть копией дескриптора выходного файла y,
1 Дескриптор выходного файла " Стандартный вывод ".
Выражение 2>&1 копирует дескриптор файла 1 к месту 2 поэтому любой вывод записывается в 2 ("стандартная ошибка") в среде выполнения переходит к тому же файлу, который первоначально описывался 1 ("стандартный вывод").
Дальнейшее объяснение:
Дескриптор файла: "Уникальное неотрицательное целое число для каждого процесса, используемое для идентификации открытого файла с целью доступа к файлу".
Стандартный вывод / ошибка: см. Следующее примечание в разделе " Перенаправление " документации оболочки:
Открытые файлы представлены десятичными числами, начинающимися с нуля. Максимально возможное значение определяется реализацией; однако, все реализации должны поддерживать по крайней мере от 0 до 9 включительно для использования приложением. Эти числа называются "файловыми дескрипторами". Значения 0, 1 и 2 имеют особое значение и обычное использование и подразумеваются определенными операциями перенаправления; они называются стандартным вводом, стандартным выводом и стандартной ошибкой соответственно. Программы обычно берут свой ввод из стандартного ввода и записывают вывод в стандартный вывод. Сообщения об ошибках обычно пишутся со стандартной ошибкой. Операторам перенаправления может предшествовать одна или несколько цифр (не допускается использование промежуточных символов) для обозначения номера дескриптора файла.
Чтобы ответить на ваш вопрос: он принимает любой вывод ошибок (обычно отправляется в stderr) и записывает его в стандартный вывод (stdout).
Это полезно, например, для "more", когда вам требуется подкачка для всего вывода. Некоторым программам нравится печатать информацию об использовании в stderr.
Чтобы помочь вам вспомнить
- 1 = стандартный вывод (где программы печатают нормальный вывод)
- 2 = стандартная ошибка (где программы печатают ошибки)
"2> & 1" просто указывает все, что отправлено на stderr, вместо этого на stdout.
Я также рекомендую прочитать этот пост о перенаправлении ошибок, где эта тема рассматривается полностью.
С точки зрения программиста, это означает именно это:
dup2(1, 2);
Смотрите справочную страницу.
Понимание того, что 2>&1 это копия также объясняет, почему...
command >file 2>&1
... это не то же самое, что...
command 2>&1 >file
Первый отправит оба потока на fileв то время как второй будет отправлять ошибки stdoutи обычный вывод в file,
Перенаправление ввода
Перенаправление ввода приводит к тому, что файл, имя которого является результатом раскрытия слова, открывается для чтения по дескриптору файла n или стандартному вводу (дескриптору файла 0), если n не указано.
Общий формат для перенаправления ввода:
[n]<wordПеренаправление вывода
Перенаправление вывода приводит к тому, что файл, имя которого является результатом раскрытия слова, открывается для записи в файловый дескриптор n или стандартный вывод (файловый дескриптор 1), если n не указано. Если файл не существует, он создается; если он существует, он усекается до нулевого размера.
Общий формат для перенаправления вывода:
[n]>wordПеремещение файловых дескрипторов
Оператор перенаправления,
[n]<&digit-перемещает цифру дескриптора файла в дескриптор файла n или стандартный ввод (дескриптор файла 0), если n не указано. цифра закрывается после дублирования на n.
Аналогично, оператор перенаправления
[n]>&digit-перемещает цифру дескриптора файла в дескриптор файла n или стандартный вывод (дескриптор файла 1), если n не указано.
Ref:
man bash
Тип /^REDIRECT найти к redirection раздел, и узнать больше...
Онлайн версия здесь: 3.6 Перенаправления
PS:
Много времени, man был мощным инструментом для изучения Linux.
Люди, всегда помните подсказку Паксдиабло о текущем местоположении цели перенаправления... Это важно.
Моя личная мнемоника для 2>&1 оператор это:
- Думать о
&как смысл'and'или же'add'(персонаж амперс - и не так ли?) - Так и получается: перенаправить
2(stderr) куда1(stdout) уже / в настоящее время есть и добавить оба потока.
Та же самая мнемоника работает и для других часто используемых перенаправлений, 1>&2:
- Думать о
&имея в видуandили жеadd... (вы получили представление об амперсанде, да?) - Так и получается: перенаправить
1(стандартный) куда2(stderr) уже / в настоящее время есть и добавить оба потока '.
И всегда помните: вы должны читать цепочки перенаправлений "с конца", справа налево (не слева направо).
unix_commands 2>&1
Это используется для вывода ошибок на терминал.
Следующее иллюстрирует процесс
- Когда возникают ошибки, они записываются в стандартный адрес памяти ошибок.
&2"буфер", из которого стандартный поток ошибок2Ссылки. - Когда производится вывод, он записывается в стандартный адрес памяти вывода.
&1"буфер", из которого стандартный выходной поток1Ссылки.
Так что возьми unix_commands стандартный поток ошибок 2, и перенаправить > поток (ошибок) на стандартный адрес памяти вывода &1, чтобы они передавались на терминал и распечатывались.
При условии, что /foo не существует в вашей системе и /tmp делает...
$ ls -l /tmp /foo
распечатает содержимое /tmp и распечатать сообщение об ошибке для /foo
$ ls -l /tmp /foo > /dev/null
отправит содержимое /tmp в /dev/null и распечатать сообщение об ошибке для /foo
$ ls -l /tmp /foo 1> /dev/null
будет делать то же самое (обратите внимание на 1)
$ ls -l /tmp /foo 2> /dev/null
распечатает содержимое /tmp и отправьте сообщение об ошибке /dev/null
$ ls -l /tmp /foo 1> /dev/null 2> /dev/null
отправит как список, так и сообщение об ошибке /dev/null
$ ls -l /tmp /foo > /dev/null 2> &1
это стенография
Это похоже на передачу ошибки на стандартный вывод или в терминал.
То есть, cmd это не команда:
$cmd 2>filename
cat filename
command not found
Ошибка отправляется в файл следующим образом:
2>&1
Стандартная ошибка отправляется на терминал.
0 для ввода, 1 для стандартного вывода и 2 для стандартного ввода.
Один совет:somecmd >1.txt 2>&1 правильно, пока somecmd 2>&1 >1.txt совершенно неправильно без эффекта!
Вы должны понимать это с точки зрения трубы.
$ (whoami;ZZZ) 2>&1 | cat
logan
ZZZ: command not found
Как вы можете видеть, и stdout, и stderr из LHS of pipe передаются в RHS (из pipe).
Это то же самое, что
$ (whoami;ZZZ) |& cat
logan
ZZZ: command not found
Обратите внимание, что 1>&2 не может использоваться взаимозаменяемо с 2>&1.
Представьте, что ваша команда зависит от трубопроводов, например:docker logs 1b3e97c49e39 2>&1 | grep "some log"
grepping произойдет в обоих stderr а также stdout поскольку stderr в основном сливается с stdout.
Однако, если вы попробуете:docker logs 1b3e97c49e39 1>&2 | grep "some log",
grepping вообще не будет искать нигде, потому что конвейер Unix соединяет процессы через соединениеstdout | stdin, а также stdout во втором случае был перенаправлен на stderr в котором Unix pipe не заинтересован.