Как реализовать Deep Q-Learning градиентный спуск
Поэтому я пытаюсь реализовать алгоритм Deep Q-learning, созданный Google DeepMind, и думаю, что теперь у меня есть довольно хорошие навыки. И все же есть одна (довольно важная) вещь, которую я не очень понимаю, и я надеюсь, что вы могли бы помочь.
Не приводит ли yj к двойному (Java), а последняя - к матрице, содержащей Q-значения для каждого действия в текущем состоянии в следующей строке (4-ая последняя строка в алгоритме):

Так как я могу вычесть их друг от друга.
Должен ли я сделать YJ матрицу, содержащую все данные отсюда  за исключением замены текущего выбранного действия на
за исключением замены текущего выбранного действия на
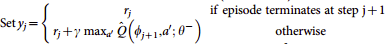
Это не похоже на правильный ответ, и я немного потерян здесь, как вы можете видеть.

1 ответ
Решение
На самом деле нашел это сам. (Понял с самого начала:D)
- Выполните прямую передачу для текущего состояния s, чтобы получить прогнозируемые значения Q для всех действий.
- Выполните передачу с прямой связью для следующего состояния s 'и рассчитайте максимальный общий выход сети max a' Q(s ', a').
- Установите целевое значение Q для действия r + γmax a 'Q(s', a ') (используйте максимум, рассчитанный на шаге 2). Для всех других действий установите целевое значение Q на то же, что первоначально возвращалось с шага 1, с ошибкой 0 для этих выходов.
- Обновите веса, используя обратное распространение.