Почему я не могу сопоставить несколько строк с этим регулярным выражением на Rubular?
Я работаю со следующим регулярным выражением (взято из devise.rb файл, который разрабатывает устройство):
\A[^@\s]+@[^@\s]+\z
Обычно, когда я узнаю о регулярном выражении, я использую Rubular. Например, если бы я хотел узнать о регулярном выражении /.a./ Я бы настроил свою рабочую область, как показано здесь:
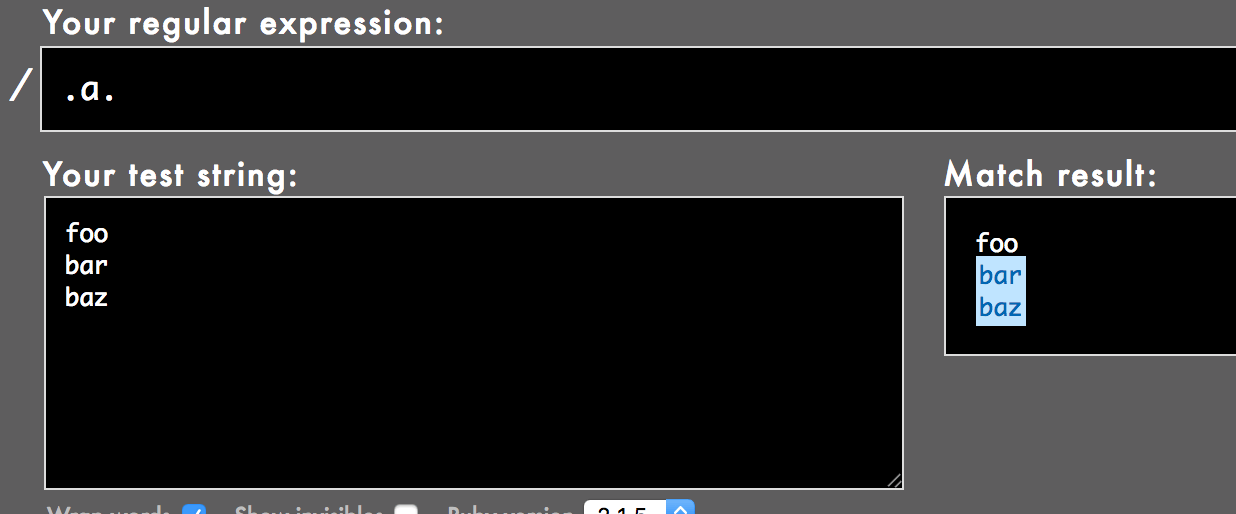
Обратите внимание, как я использую несколько примеров:
foo
bar
baz
И Rubular дает мне обратную связь, что оба bar а также baz матч.
Теперь я хотел бы узнать о регулярном выражении, которое генерирует devise: /\A[^@\s]+@[^@\s]+\z/, Поэтому я настроил свое рабочее пространство как показано здесь:
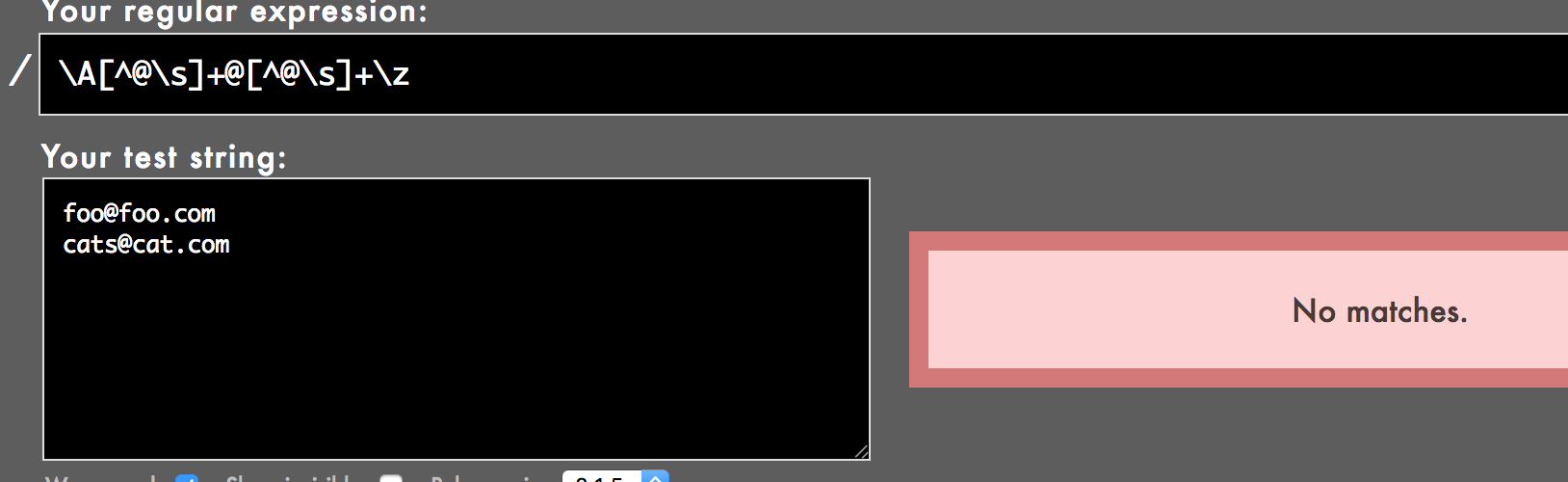
Там нет матча. Это потому, что у меня есть два примера:
foo@foo.com
cats@cat.com
Но я ожидал, что они оба совпадут. Почему не совпадают обе тестовые строки?
1 ответ
Это потому, что регулярное выражение /\A[^@\s]+@[^@\s]+\z/ соответствует началу строки с \A и конец строки с \z,
Если вы удалите оба \A а также \z и вместо этого попытаться сопоставить /[^@\s]+@[^@\s]+/ тогда он будет соответствовать обоим адресам электронной почты, как показано здесь:

Также стоит отметить, что начало и конец строки отличается от начала и конца строки. Каждый из них представлен четырьмя различными шаблонами, показанными ниже, а также в виде рубля в кратком справочнике по Regex:
^ - Start of line
$ - End of line
\A - Start of string
\z - End of string
В строке может быть несколько строк; тем не менее, одна строка идет от \A в \z, Итак, чтобы продолжить с этим примером несколько электронной почты. Заменить начало и конец шаблонов строки на шаблоны начала и конца строки, чтобы получить: /^[^@\s]+@[^@\s]+$/ также будет соответствовать, показано ниже и на рублевой:
