Почему число мопов за итерацию увеличивается с увеличением потоковой загрузки?
Рассмотрим следующий цикл:
.loop:
add rsi, OFFSET
mov eax, dword [rsi]
dec ebp
jg .loop
где OFFSET некоторое неотрицательное целое число и rsi содержит указатель на буфер, определенный в bss раздел. Этот цикл является единственным циклом в коде. То есть он не инициализируется и не затрагивается до цикла. Предположительно, в Linux все виртуальные страницы 4K буфера будут отображаться по требованию на одну и ту же физическую страницу. Следовательно, единственным ограничением размера буфера является количество виртуальных страниц. Таким образом, мы можем легко экспериментировать с очень большими буферами.
Цикл состоит из 4 инструкций. Каждая инструкция декодируется в один моп в слитном и неиспользованном домене в Haswell. Существует также циклическая зависимость между последовательными экземплярами add rsi, OFFSET, Поэтому в условиях простоя, когда нагрузка всегда находится в L1D, цикл должен выполняться примерно за 1 цикл на итерацию. Для небольших смещений (шагов) это ожидается благодаря IP-потоковому предварительному считывателю L1 и потоковому предварительному извлечению L2. Однако оба средства предварительной выборки могут выполнять предварительную выборку только на странице 4K, и максимальный шаг, поддерживаемый средством предварительной выборки L1, составляет 2К. Таким образом, для небольших шагов, должно быть около 1 L1 промах на 4K страницы. По мере увеличения шага общее число пропусков L1 и пропусков TLB будет увеличиваться, и производительность соответственно будет ухудшаться.
На следующем графике показаны различные интересные счетчики производительности (на одну итерацию) для шагов от 0 до 128. Обратите внимание, что число итераций является постоянным для всех экспериментов. Изменяется только размер буфера для размещения указанного шага. Кроме того, учитываются только события производительности в пользовательском режиме.
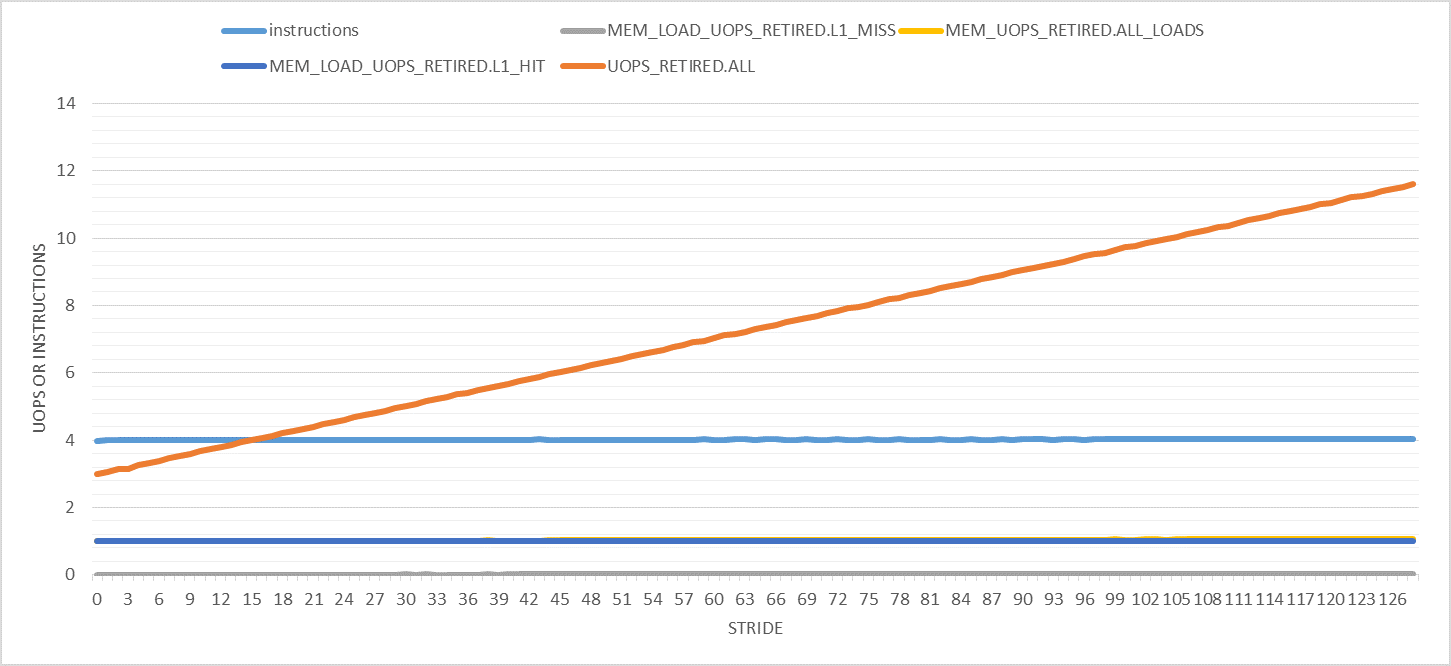
Единственное, что здесь странно, так это то, что количество отставных мопов увеличивается с ростом. Он идет от 3 мопов за итерацию (как и ожидалось) до 11 для шага 128. Почему это так?
Вещи становятся только страннее с большими шагами, как показано на следующем графике. На этом графике шаги варьируются от 32 до 8192 с шагом 32 байта. Во-первых, количество удаленных инструкций линейно увеличивается с 4 до 5 на шаге 4096 байт, после чего оно остается постоянным. Количество загрузок увеличивается с 1 до 3, а количество обращений к нагрузке L1D остается равным 1 на каждую итерацию. Только количество пропущенных нагрузок L1D имеет смысл для всех этапов.
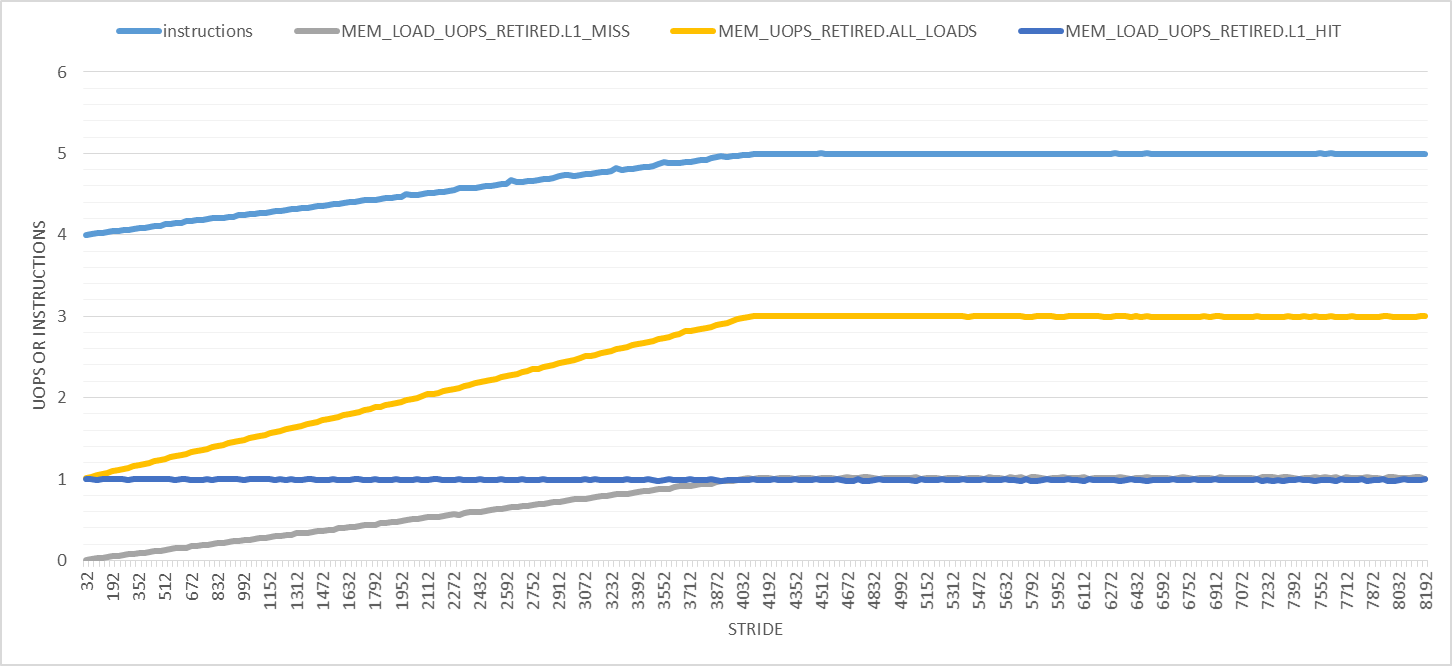
Два очевидных эффекта больших успехов:
- Время выполнения увеличивается, и поэтому будет происходить больше аппаратных прерываний. Однако я считаю события в пользовательском режиме, поэтому прерывания не должны мешать моим измерениям. Я также повторил все эксперименты с
tasksetили жеniceи получил те же результаты. - Количество просмотров страниц и ошибок страниц увеличивается. (Я проверил это, но я опущу графики для краткости.) Ошибки страницы обрабатываются ядром в режиме ядра. Согласно этому ответу, обход страниц осуществляется с использованием специального оборудования (на Haswell?). Хотя ссылка, на которой основан ответ, мертва.
Для дальнейших исследований на следующем графике показано количество мопов с помощью микрокодов. Число вспомогательных операций микрокода на одну итерацию увеличивается, пока не достигнет максимального значения на шаге 4096, как и в случае других событий производительности. Число операций ввода микрокода на виртуальную страницу 4K составляет 506 для всех шагов. В строке "Extra UOPS" отображается количество выбывших мопов минус 3 (ожидаемое количество мопов за итерацию).
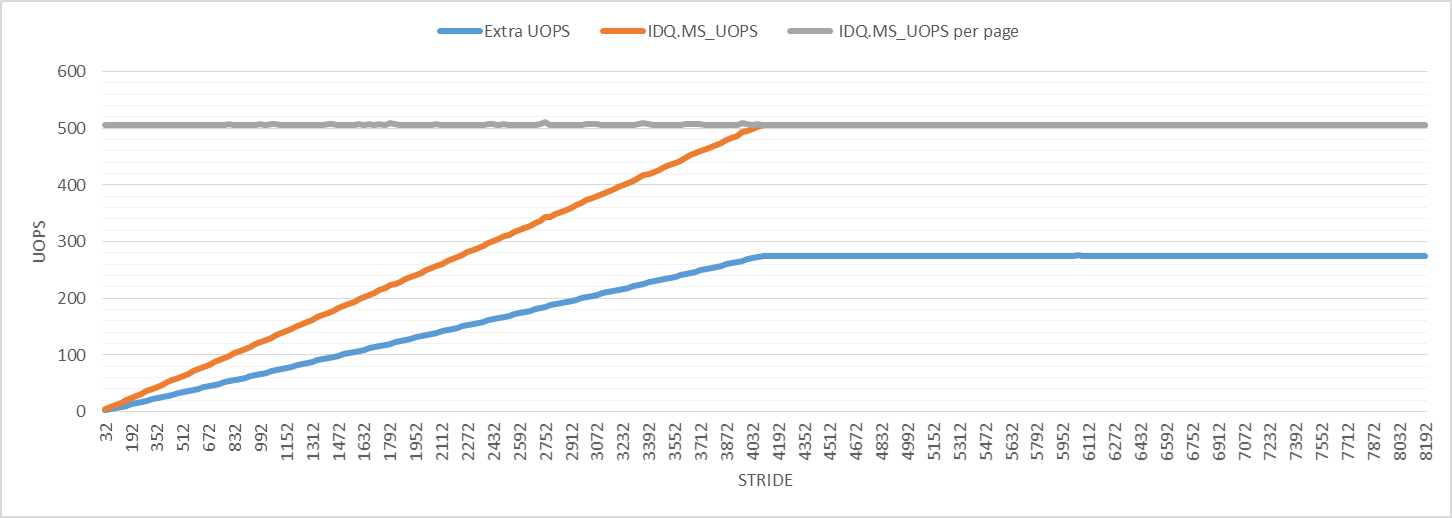
График показывает, что число дополнительных мопов немного больше половины числа мопов, помогающих микрокодам, для всех шагов. Я не знаю, что это значит, но это может быть связано с просмотром страниц и может быть причиной наблюдаемого возмущения.
Почему количество удаленных инструкций и мопов за итерацию увеличивается для больших шагов, даже если количество статических инструкций за итерацию одинаково? Откуда исходит помеха?
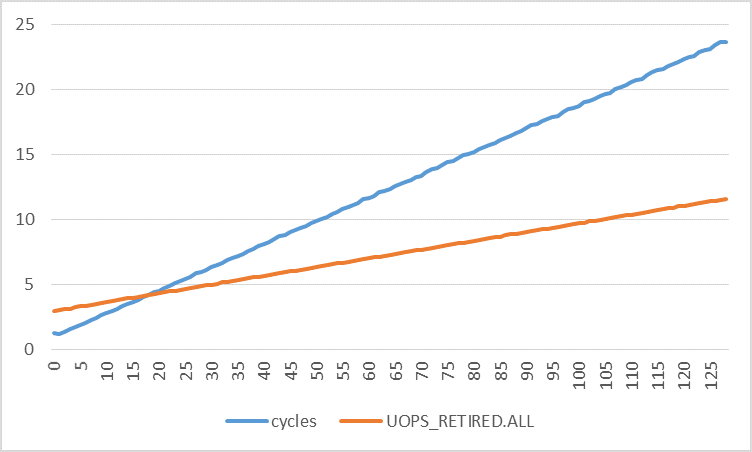
На следующих графиках показано количество циклов на одну итерацию в зависимости от количества удаленных мопов на одну итерацию для разных шагов. Количество циклов увеличивается гораздо быстрее, чем количество выбывших мопов. Используя линейную регрессию, я нашел:
cycles = 0.1773 * stride + 0.8521
uops = 0.0672 * stride + 2.9277
Взяв производные обеих функций:
d(cycles)/d(stride) = 0.1773
d(uops)/d(stride) = 0.0672
Это означает, что число циклов увеличивается на 0,1773, а число удаленных мопов увеличивается на 0,0672 с каждым шагом в 1 байт. Если прерывания и сбои страниц действительно были (единственной) причиной возмущения, не должны ли оба показателя быть очень близкими?

2 ответа
Эффект, который вы неоднократно видите на многих счетчиках производительности, где значение увеличивается линейно до шага 4096, после которого оно остается постоянным, имеет смысл, если вы предполагаете, что эффект вызван исключительно увеличением количества ошибок страниц с увеличением шага. Ошибки страницы влияют на наблюдаемые значения, потому что многие счетчики не являются точными при наличии прерываний, ошибок страниц и так далее.
Например, возьмите instructions счетчик, который увеличивается с 4 до 5 по мере продвижения от шага 0 к 4096. Мы знаем из других источников, что каждая ошибка страницы в Haswell будет считать одну дополнительную инструкцию в пользовательском режиме (и одну дополнительную в режиме ядра).
Таким образом, количество инструкций, которые мы ожидаем, является базой из 4 инструкций в цикле, плюс некоторая часть инструкции, основанная на том, сколько ошибок страниц мы принимаем за цикл. Если мы предположим, что каждая новая страница размером 4 КиБ вызывает ошибку страницы, то число ошибок страницы за итерацию составляет:
MIN(OFFSET / 4096, 1)
Поскольку каждый сбой страницы учитывает дополнительную инструкцию, мы получаем ожидаемое количество команд:
4 + 1 * MIN(OFFSET / 4096, 1)
что находится в полном соответствии с вашим графиком.
Таким образом, грубая форма наклонного графика объясняется для всех счетчиков одновременно: наклон зависит только от количества перерасчетов на страницу ошибки. Тогда остается только один вопрос: почему сбой страницы влияет на каждый счетчик так, как вы определили? Мы покрыли instructions уже, но давайте посмотрим на другие:
MEM_LOAD_UOPS.L1_MISS
Вы получаете только 1 промах на страницу, потому что только загрузка, которая касается следующей страницы, пропускает что-либо (это принимает ошибку). На самом деле я не согласен с тем, что это предварительный выборщик L1, который не приводит ни к каким другим промахам: я думаю, вы получите тот же результат, если отключите предварительные выборки. Я думаю, что вы больше не пропускаете L1, поскольку одна и та же физическая страница поддерживает каждую виртуальную страницу, и как только вы добавили запись TLB, все строки уже находятся в L1 (самая первая итерация будет пропущена - но я предполагаю, что вы делаете много итераций).
MEM_UOPS_RETIRED.ALL_LOADS
Это показывает 3 мопа (2 дополнительных) за ошибку страницы.
Я не уверен на 100%, как это событие работает при наличии повторного воспроизведения. Всегда ли учитывается фиксированное количество мопов на основе инструкции, например, числа, которое вы видите в инструкции Агнера -> таблицы мопов? Или это подсчитывает фактическое количество мопов, отправленных от имени инструкции? Обычно это то же самое, но загружает повторы своих мопов, когда они пропускают на разных уровнях кеша.
Например, я обнаружил, что в Haswell и Skylake2, когда загрузка пропускается в L1, но попадает в L2, вы видите всего 2 мопа между портами нагрузки (порт 2 и порт 3). Предположительно, происходит то, что моп отправляется с предположением, что он попадет в L1, а когда этого не происходит (результат не готов, когда планировщик этого ожидал), он воспроизводится с новым временем, ожидающим попадание L2. Это "облегченно" в том смысле, что не требует какой-либо конвейерной очистки, так как не выполнялось никаких инструкций по неверному пути.
Точно так же для промаха L3 я наблюдал 3 мопа за загрузку.
Учитывая это, кажется разумным предположить, что промах на новой странице приводит к повторному воспроизведению load uop (как я наблюдал), и эти uops отображаются в MEM_UOPS_RETIRED счетчик. Можно разумно утверждать, что переигранные мопы не удаляются, но в некотором смысле отставка больше связана с инструкциями, чем мопами. Возможно, этот счетчик лучше описать как "отправленные мопы, связанные с инструкциями по загрузке на пенсию".
UOPS_RETIRED.ALL а также IDQ.MS_UOPS
Остальной странностью является большое количество мопов, связанных с каждой страницей. Кажется вполне вероятным, что это связано с механизмом сбоя страницы. Вы можете попробовать аналогичный тест, который отсутствует в TLB, но не принимает ошибку страницы (убедитесь, что страницы уже заполнены, например, используя mmap с MAP_POPULATE).
Разница между MS_UOPS а также UOPS_RETIRED не кажется странным, так как некоторые мопы не могут выйти на пенсию. Может быть, они также учитываются в разных доменах (я забыл, если UOPS_RETIRED слитый или неиспользованный домен).
Возможно, в этом случае также имеется утечка между счетчиками режима пользователя и режима ядра.
Циклы против производной UOP
В последней части вашего вопроса вы показываете, что "крутизна" циклов по сравнению со смещением примерно в 2,6 раза больше, чем уклон вышедших мопов по сравнению со смещением.
Как и выше, эффект здесь останавливается на 4096, и мы ожидаем, что этот эффект полностью связан с ошибками страниц. Таким образом, разница в уклоне просто означает, что сбой страницы стоит в 2,6 раза больше циклов, чем мопс.
Ты говоришь:
Если прерывания и сбои страниц действительно были (единственной) причиной возмущения, не должны ли оба показателя быть очень близкими?
Я не понимаю почему. Соотношение между мопами и циклами может варьироваться в широких пределах, возможно, на три порядка: ЦП может выполнять четыре мопа за такт, или может потребоваться 100 секунд циклов для выполнения одного мопа (например, из-за отсутствия кэша).
Значение 2,6 цикла на моп находится прямо в середине этого большого диапазона и не кажется мне странным: оно немного велико ("неэффективно", если вы говорили об оптимизированном коде приложения), но здесь мы говорим о странице обработка ошибок, которая является совершенно другой вещью, поэтому мы ожидаем длительных задержек.
Исследования по пересчету
Любой, кто заинтересован в перерасчете из-за сбоев страниц и других событий, может быть заинтересован в этом репозитории github, в котором есть исчерпывающие тесты на "детерминизм" различных событий PMU, и где было отмечено много результатов такого рода, в том числе на Haswell. Однако он не охватывает все счетчики, упомянутые здесь Хади (в противном случае у нас уже был бы наш ответ). Вот соответствующий документ и некоторые более простые в использовании связанные слайды - в них, в частности, упоминается, что для каждой ошибки страницы возникает одна дополнительная инструкция.
Вот цитата для результатов от Intel:
Conclusions on the event determinism:
1. BR_INST_RETIRED.ALL (0x04C4)
a. Near branch (no code segment change): Vince tested
BR_INST_RETIRED.CONDITIONAL and concluded it as deterministic.
We verified that this applies to the near branch event by using
BR_INST_RETIRED.ALL - BR_INST_RETIRED.FAR_BRANCHES.
b. Far branch (with code segment change): BR_INST_RETIRED.FAR_BRANCHES
counts interrupts and page-faults. In particular, for all ring
(OS and user) levels the event counts 2 for each interrupt or
page-fault, which occurs on interrupt/fault entry and exit (IRET).
For Ring 3 (user) level, the counter counts 1 for the interrupt/fault
exit. Subtracting the interrupts and faults (PerfMon event 0x01cb and
Linux Perf event - faults), BR_INST_RETIRED.FAR_BRANCHES remains a
constant of 2 for all the 17 tests by Perf (the 2 count appears coming
from the Linux Perf for counter enabling and disabling).
Consequently, BR_INST_RETIRED.FAR_BRANCHES is deterministic.
Таким образом, вы ожидаете одну дополнительную инструкцию (в частности, инструкцию перехода) для каждой ошибки страницы.
1 Во многих случаях эта "неточность" все еще является детерминированной - в том случае, если при наличии внешнего события избыточный или недостаточный подсчет всегда ведет себя одинаково, поэтому вы можете исправить его, если вы также отследите, сколько из соответствующих событий произошло.
2 Я не хочу ограничивать это этими двумя микроархитектурами: это просто те, которые я тестировал.
Я думаю, что ответ @BeeOnRope полностью отвечает на мой вопрос. Я хотел бы добавить некоторые дополнительные детали, основанные на ответе @BeeOnRope и комментариях под ним. В частности, я покажу, как определить, происходит ли событие производительности фиксированное число раз за итерацию для всех шагов загрузки или нет.
Из кода видно, что для выполнения одной итерации требуется 3 мопа. Первые несколько загрузок могут отсутствовать в кэше L1, но затем все последующие загрузки будут попадать в кэш, поскольку все виртуальные страницы отображаются на одну и ту же физическую страницу, а L1 в процессорах Intel физически помечены и проиндексированы. Итак, 3 мопса. Теперь рассмотрим UOPS_RETIRED.ALL событие производительности, которое происходит, когда моп выходит на пенсию. Мы ожидаем увидеть около 3 * number of iterations такие события. Аппаратные прерывания и сбои страниц, возникающие во время выполнения, требуют помощи микрокода для обработки, что, вероятно, нарушит производительность. Следовательно, для конкретного измерения события X производительности источником каждого подсчитанного события может быть:
- Инструкции по профилируемому коду. Давайте назовем это X1.
- Uops используется для вызова ошибки страницы, которая произошла из-за доступа к памяти, предпринятого профилируемым кодом. Давайте назовем это X2.
- Uops используется для вызова обработчика прерываний из-за асинхронного аппаратного прерывания или из-за программного исключения. Давайте назовем это X3.
Следовательно, X = X1 + X2 + X3.
Поскольку код прост, мы смогли определить с помощью статического анализа, что X1 = 3. Но мы ничего не знаем о X2 и X3, которые могут не быть постоянными на одну итерацию. Мы можем измерить X, используя UOPS_RETIRED.ALL, К счастью, для нашего кода количество сбоев страниц соответствует регулярному шаблону: ровно по одному на каждую страницу (что можно проверить, используя perf). Разумно предположить, что для устранения каждой ошибки на странице требуется одинаковый объем работы, поэтому каждый раз он будет оказывать одинаковое влияние на X. Обратите внимание, что это отличается от количества сбоев страниц за итерацию, которое отличается для разных шагов загрузки. Число мопов, удаленных как прямой результат выполнения цикла для каждой страницы, является постоянным. Наш код не вызывает никаких программных исключений, поэтому нам не нужно о них беспокоиться. Как насчет аппаратных прерываний? Что ж, в Linux, пока мы запускаем код на ядре, которое не назначено для обработки прерываний мыши / клавиатуры, единственное прерывание, которое действительно имеет значение, это локальный таймер APIC. К счастью, это прерывание также происходит регулярно. Пока количество времени, затрачиваемое на страницу, одинаково, влияние прерывания таймера на X будет постоянным для каждой страницы.
Мы можем упростить предыдущее уравнение до:
Х = Х1 + Х4.
Таким образом, для всех нагрузок,
(X на страницу) - (X1 на страницу) = (X4 на страницу) = постоянная.
Теперь я расскажу, почему это полезно, и приведу примеры с использованием различных событий производительности. Нам понадобятся следующие обозначения:
ec = total number of performance events (measured)
np = total number of virtual memory mappings used = minor page faults + major page faults (measured)
exp = expected number of performance events per iteration *on average* (unknown)
iter = total number of iterations. (statically known)
Обратите внимание, что в общем случае мы не знаем или не уверены в интересующем нас событии производительности, поэтому нам необходимо его измерять. Случай с отставными мопами был легким. Но в целом это то, что нам нужно выяснить или проверить экспериментально. По существу, exp это количество событий производительности ec но исключая тех, которые поднимают ошибки страницы и прерывания.
Основываясь на аргументах и предположениях, изложенных выше, мы можем вывести следующее уравнение:
C = (ec/np) - (exp*iter/np) = (ec - exp*iter)/np
Здесь есть два неизвестных: постоянная C и значение, которое нас интересует exp, Итак, нам нужно два уравнения, чтобы можно было вычислить неизвестные. Поскольку это уравнение выполняется для всех шагов, мы можем использовать измерения для двух разных шагов:
C = (ec1 - exp * iter) / np1
C = (ec2 - exp * iter) / np2
Мы можем найти exp:
(ec1 - exp * iter) / np1 = (ec2 - exp * iter) / np2
ec1* np2 - exp * iter * np2 = ec2* np1 - exp * iter * np1
ec1* np2 - ec2* np1 = exp * iter * np2 - exp * iter * np1
ec1* np2 - ec2* np1 = exp * iter * (np2 - np1)
Таким образом,
exp = (ec1* np2 - ec2* np1) / (iter * (np2 - np1))
Давайте применим это уравнение к UOPS_RETIRED.ALL,
шаг1 = 32
iter = 10 миллионов
NP1 = 10 миллионов * 32 / 4096 = 78125
EC1 = 51410801
шаг2 = 64
iter = 10 миллионов
NP2 = 10 миллионов * 64 / 4096 = 156250
ec2 = 72883662
exp = (51410801 *156250 - 72883662 * 78125) / (10 м * (156250 - 78125))
= 2,99
Ницца! Очень близко к ожидаемым 3 ментам на пенсии за одну итерацию.
C = (51410801-2,99*10 м)/78125 = 275,3
Я рассчитал C для всех шагов. Это не совсем константа, но это 275+-1 для всех шагов.
exp для других событий производительности можно вывести аналогично:
MEM_LOAD_UOPS_RETIRED.L1_MISS: exp = 0MEM_LOAD_UOPS_RETIRED.L1_HIT: exp = 1MEM_UOPS_RETIRED.ALL_LOADS: exp = 1UOPS_RETIRED.RETIRE_SLOTS: exp = 3
Так это работает для всех событий производительности? Что ж, давайте попробуем что-то менее очевидное. Рассмотрим для примера RESOURCE_STALLS.ANY, который измеряет циклы задержки распределителя по любой причине. Сложно сказать, сколько exp должно быть, просто глядя на код. Обратите внимание, что для нашего кода, RESOURCE_STALLS.ROB а также RESOURCE_STALLS.RS ноль. Только RESOURCE_STALLS.ANY здесь важно Вооружившись уравнением для exp и экспериментальные результаты для разных шагов, мы можем рассчитать exp,
шаг1 = 32
iter = 10 миллионов
NP1 = 10 миллионов * 32 / 4096 = 78125
EC1 = 9207261
шаг2 = 64
iter = 10 миллионов
NP2 = 10 миллионов * 64 / 4096 = 156250
EC2 = 16111308
exp = (9207261 *156250 - 16111308 * 78125) / (10 м * (156250 - 78125))
= 0,23
C = (9207261 - 0,23*10 м)/78125 = 88,4
Я рассчитал C для всех шагов. Ну, это не выглядит постоянным. Возможно, мы должны использовать разные шаги? Нет вреда в попытках.
шаг1 = 32
Итэр1 = 10 миллионов
NP1 = 10 миллионов * 32 / 4096 = 78125
EC1 = 9207261
шаг2 = 4096
Итэр2 = 1 миллион
NP2 = 1 миллион * 4096 / 4096 = 1 м
EC2 = 102563371
exp = (9207261 *1 м - 102563371*78125)/(1 м *1 м - 10 м * 78125))
= 0,01
C = (9207261 - 0,23*10 м)/78125 = 88,4
(Обратите внимание, что на этот раз я использовал разное количество итераций, чтобы показать, что вы можете это сделать.)
Мы получили другое значение для exp, Я рассчитал C для всех шагов, и он все еще не выглядит постоянным, как показано на следующем графике. Он значительно варьируется для небольших шагов, а затем немного после 2048 года. Это означает, что одно или несколько предположений о наличии фиксированного количества циклов задержки распределителя на страницу не так уж достоверны. Другими словами, стандартное отклонение циклов задержки распределителя для разных шагов является значительным.

Для UOPS_RETIRED.STALL_CYCLES событие производительности, exp = -0,32 и стандартное отклонение также значимо. Это означает, что одно или несколько предположений о наличии фиксированного количества циклов отставания на одной странице недействительны.

Я разработал простой способ исправить измеренное количество вышедших на пенсию инструкций. Каждая ошибка сработавшей страницы добавит ровно одно дополнительное событие к счетчику удаленных команд. Например, предположим, что сбой страницы происходит регулярно после некоторого фиксированного числа итераций, скажем, 2. То есть, каждые две итерации происходит сбой. Это происходит для кода в вопросе, когда шаг равен 2048. Поскольку мы ожидаем, что 4 инструкции будут отменены за одну итерацию, общее число ожидаемых удаленных инструкций до появления ошибки страницы будет равно 4*2 = 8. Поскольку ошибка страницы добавляет одну дополнительное событие для счетчика удаленных команд, оно будет измеряться как 9 для двух итераций вместо 8. То есть 4,5 за итерацию. Когда я на самом деле измеряю количество выбывших инструкций для случая с шагом 2048, оно очень близко к 4,5. Во всех случаях, когда я применяю этот метод для статического прогнозирования значения измеренной удаленной инструкции за одну итерацию, ошибка всегда составляет менее 1%. Это очень точно, несмотря на аппаратные прерывания. Я думаю, что пока общее время выполнения составляет менее 5 миллиардов циклов ядра, аппаратные прерывания не будут оказывать существенного влияния на счетчик удаленных команд. (Каждый из моих экспериментов занимал не более 5 миллиардов циклов, вот почему.) Но, как объяснялось выше, всегда следует обращать внимание на количество возникших неисправностей.
Как я уже говорил выше, существует множество счетчиков производительности, которые можно исправить, рассчитав значения для каждой страницы. С другой стороны, счетчик удаленных команд можно исправить, учитывая количество итераций, чтобы получить ошибку страницы. RESOURCE_STALLS.ANY а также UOPS_RETIRED.STALL_CYCLES возможно, это можно исправить аналогично счетчику удаленных команд, но я не исследовал эти два.