Ускоряет ли использование ASCII/Latin Charset базу данных?
Казалось бы, использование кодировки ASCII для большинства полей, а затем указание utf8 только для тех полей, которые в этом нуждаются, уменьшит количество операций ввода-вывода, которые база данных должна выполнить на 100%.
Кто-нибудь знает, правда ли это?
Обновление: выше не был мой вопрос. Я должен был сказать: используйте латиницу для набора символов по умолчанию, а затем указывайте только utf8mb4 только для полей, которые нуждаются в этом. Мысль такова: использование 1 байта против 2 байтов должно улучшить ввод / вывод на 100%. Извините за путаницу.
2 ответа
@RickJames прав, вам не нужно беспокоиться об экономии места, выбрав ASCII или utf8 вместо utf8mb4.
utf8 и utf8mb4 - это кодировки символов переменной длины. Эта таблица из википедии иллюстрирует, как символы автоматически получают 1, 2, 3 или 4 байта каждый, в зависимости от закодированного значения. Если установлен старший бит байта, то символ использует дополнительный байт, до 4 байтов.
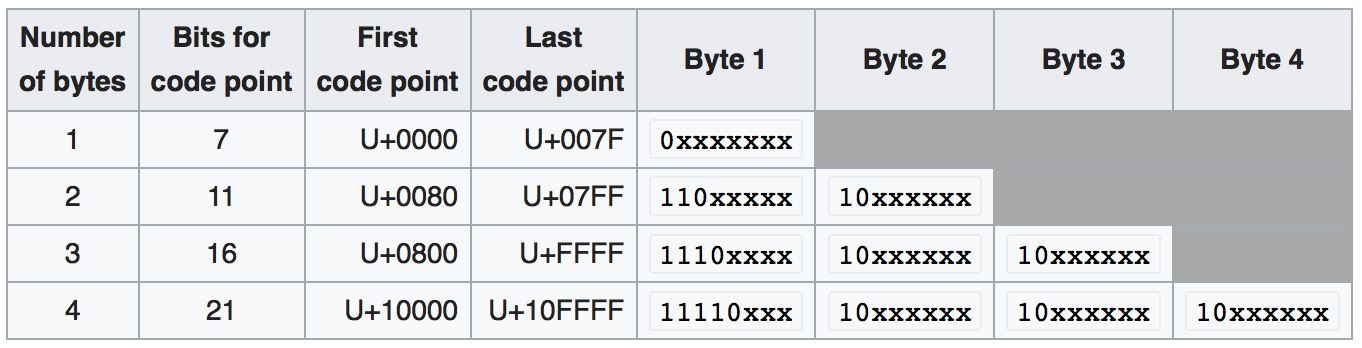 Статья в Википедии объясняет это ясно:
Статья в Википедии объясняет это ясно:
Первые 128 символов (US-ASCII) требуют один байт. Следующим 1920 символам требуется два байта для кодирования, что охватывает оставшуюся часть почти всех алфавитов латинского алфавита, а также алфавитов греческого, кириллического, коптского, армянского, иврита, арабского, сирийского, тхана и н'ко, а также сочетания диакритических знаков Метки. Три символа необходимы для символов в остальной части базовой многоязычной плоскости, которая содержит практически все символы общего пользования, включая большинство китайских, японских и корейских символов. Четыре символа необходимы для символов в других плоскостях Unicode, которые включают в себя менее распространенные символы CJK, различные исторические сценарии, математические символы и эмодзи (пиктографические символы).
Вам не нужно ничего делать, чтобы выбрать однобайтовый или многобайтовый режим. Именно так работает кодировка. Каждый символ автоматически использует необходимое ему количество байтов, и не более.
Таким образом, нет никакого преимущества в использовании utf8 по сравнению с utf8mb4, и в этом нет никакого преимущества в использовании ASCII, если только вам не нужно ограничивать символы, разрешенные в строке.
Что бы ни стоило, набор символов, который MySQL называет "utf8", является псевдонимом для utf8mb3, реализацией только первых трех байтов кодировки UTF8. В блоге команды сервера MySQL ( https://mysqlserverteam.com/mysql-8-0-when-to-use-utf8mb3-over-utf8mb4/) говорится, что utf8mb4 работает быстрее, по крайней мере, с учетом повышения производительности в MySQL 8.0 и utf8mb3. следует считать устаревшим. В примечаниях к выпуску MySQL 8.0.11 говорится, что utf8 будет переопределен как псевдоним для utf8mb4 в некоторых будущих версиях MySQL.
Короткий ответ: не стоит беспокоиться.
Длинный ответ:
Два вопроса:
- Скорость:
Сравнение двух кодировок с соответствующим _bin (ascii_bin или utf8_bin) COLLATION это так же просто, как сравнение байтов - так что никакой существенной разницы. Другие параметры сортировки могут отличаться, поскольку ASCII быстрее. Но разница незначительна по сравнению с усилиями по извлечению строк и т. Д.
- Космос:
Ascii является подмножеством utf8. utf8 хранит только 1 байт для каждого символа ascii, как это делает ascii. Таким образом, нет разницы в пространстве. (Буквы с ударением в Западной Европе нуждаются в 1-байтовом латинском 1 или 2-байтовом utf8; следовательно, несовместимы и различаются по размеру.) Пробел приводит к кешированию, что приводит к небольшой разнице в производительности.
Для английского текста экономия 0%. Для европейца латиница 1 сэкономила бы всего несколько процентов; Для большинства остального мира utf8 - единственное жизнеспособное решение. Для китайцев и эмодзи utf8mb4 является обязательным.
- Временные таблицы
В определенных ситуациях пространство, занимаемое строкой, увеличивается до максимального значения. country_code CHAR(2) CHARACTER SET ... займет 2 байта для ASCII; 6 байт для utf8.
Нижняя линия:
Используйте ascii для кодов стран, шестнадцатеричных кодов, почтовых индексов, uuids, md5s и т. Д. Если вы собираетесь выйти на международный уровень и / или нуждаетесь в смайликах, сделайте свои "строки" utf8mb4. Но делайте это потому, что это "правильно", а не потому, что вы волшебным образом получите намного большую скорость; ты не будешь. И делайте это всякий раз, когда вы создаете таблицу; это ямы, чтобы изменить это позже.