Примерное совпадение строк в одном списке - r
У меня есть список в фрейме данных тысяч имен в длинном списке. Многие из имен имеют небольшие различия в них, которые делают их немного другими. Я хотел бы найти способ сопоставить эти имена. Например:
names <- c('jon smith','jon, smith','Jon Smith','jon smith et al','bob seger','bob, seger','bobby seger','bob seger jr.')
Я смотрел на amatch в stringdist функция, а также agrep, но все они требуют основного списка имен, которые используются для сопоставления другого списка имен. В моем случае у меня нет такого главного списка, поэтому я хотел бы создать его из данных, идентифицируя имена с очень похожими шаблонами, чтобы я мог посмотреть на них и решить, являются ли они одним и тем же человеком (который во многих случаи они есть). Я хотел бы получить вывод в новом столбце, который поможет мне узнать, что это вероятное совпадение и, возможно, какое-то сходство, основанное на расстоянии Левенштейна, или что-то в этом роде. Может быть, что-то вроде этого:
names match SimilarityScore
1 jon smith a 9
2 jon, smith a 8
3 Jon Smith a 9
4 jon smith et al a 5
5 bob seger b 9
6 bob, seger b 8
7 bobby seger b 7
8 bob seger jr. b 5
Возможно ли что-то подобное?
2 ответа
Опираясь на найденный здесь пост, я обнаружил, что иерархическая кластеризация текста будет делать то, что я ищу.
names <- c('jon smith','jon, smith','Jon Smith','jon smith et al','bob seger','bob, seger','bobby seger','bob seger jr.','jake','jakey','jack','jakeyfied')
# Levenshtein Distance
e <- adist(names)
rownames(e) <- names
hc <- hclust(as.dist(e))
plot(hc)
rect.hclust(hc,k=3) #the k value provides the number of clusters
df <- data.frame(names,cutree(hc,k=3))
Вывод выглядит действительно хорошо, если вы выберете правильное количество кластеров (три в данном случае):
names cutree.hc..k...3.
jon smith jon smith 1
jon, smith jon, smith 1
Jon Smith Jon Smith 1
jon smith et al jon smith et al 1
bob seger bob seger 2
bob, seger bob, seger 2
bobby seger bobby seger 2
bob seger jr. bob seger jr. 2
jake jake 3
jakey jakey 3
jack jack 3
jakeyfied jakeyfied 3
Однако имена часто бывают более сложными, и после добавления нескольких более сложных имен я обнаружил, что по умолчанию adist варианты не дали лучшую кластеризацию:
names <- c('jon smith','jon, smith','Jon Smith','jon smith et al','bob seger','bob, seger','bobby seger','bob seger jr.','jake','jakey','jack','jakeyfied','1234 ranch','5678 ranch','9983','7777')
d <- adist(names)
rownames(d) <- names
hc <- hclust(as.dist(d))
plot(hc)
rect.hclust(hc,k=6)

Я смог улучшить это, увеличив стоимость замены до 2, оставив затраты на вставку и удаление на 1, и проигнорировав регистр. Это помогло минимизировать ошибочную группировку совершенно разных четырехзначных числовых строк, которые я не хотел группировать:
d <- adist(names,ignore.case=TRUE, costs=c(i=1,d=1,s=2)) #i=insertion, d=deletion s=substitution
rownames(d) <- names
hc <- hclust(as.dist(d))
plot(hc)
rect.hclust(hc,k=6
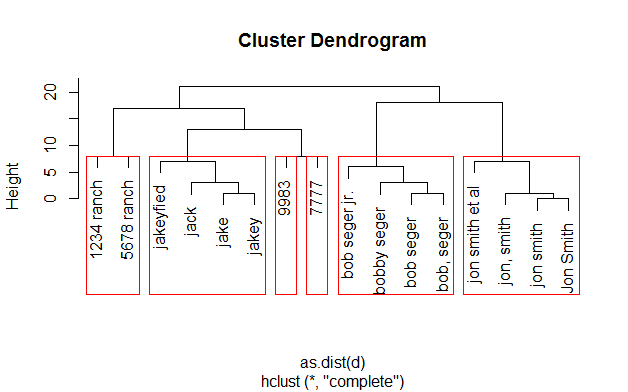
Я также настроил кластеризацию, удалив общие термины, такие как "ранчо" и "и др.", Используя gsub инструмент в grep Пакет и увеличение количества кластеров на один:
names<-gsub("ranch","",names)
names<-gsub("et al","",names)
d <- adist(names,ignore.case=TRUE, costs=c(i=1,d=1,s=2))
rownames(d) <- names
hc <- hclust(as.dist(d))
plot(hc)
rect.hclust(hc,k=7)
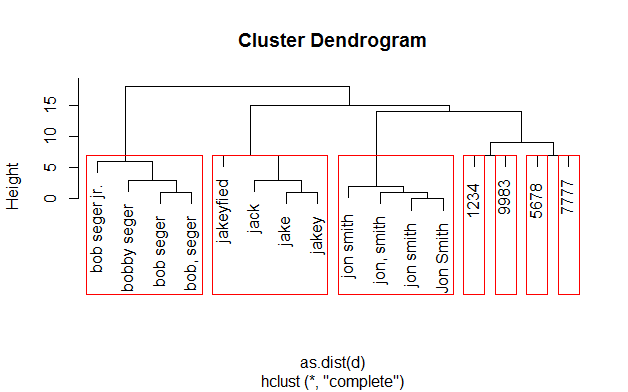
Хотя существуют методы, позволяющие данным отсортировать наилучшее количество кластеров, вместо того, чтобы пытаться вручную выбрать число, я обнаружил, что проще всего использовать метод проб и ошибок, хотя здесь есть информация об этом подходе.
Предложение Романа в комментариях по обработке естественного языка, вероятно, лучшее место для начала. Но для подхода типа "обратно за конвертом" вы можете посмотреть на расстояние с точки зрения кода ascii:
mynames = c("abcd efghijkl mn","zbcd efghijkl mn","bbcd efghijkl mn","erqe")
asc <- function(x) { strtoi(charToRaw(x),16L) }
namesToChar= sapply(mynames, asc)
maxLength= max(unlist(lapply(namesToChar,length)))
namesToChar =lapply(namesToChar, function(x) { c(x, rep(-1, times = maxLength-length(x) )) } )
namesToChar = do.call("rbind",namesToChar)
dist(namesToChar,method="euclidean")
dist(namesToChar,method="canberra")
Хотя это, кажется, дает достаточно цифр для образца,
> dist(namesToChar,method="manhattan")
abcd efghijkl mn zbcd efghijkl mn bbcd efghijkl mn
zbcd efghijkl mn 25
bbcd efghijkl mn 1 24
erqe 257 274 256
этот подход страдает от того факта, что не существует адекватного метода dist функция для того, что вы хотите сделать. Поэлементное двоичное сравнение, за которым, возможно, следует более стандартное расстояние ("Манхэттен" кажется наиболее близким к вашим потребностям)? Конечно, вы всегда можете реализовать это сами. Так же -1 заполнить здесь - это хак, вам нужно заменить его на средний код ascii вашего примера, если вы решите пойти по этому пути.
Для оценки сходства и общей численности населения вы можете взять обратное значение среднего расстояния друг против друга.