Какое влияние оказывают SFENCE и LFENCE на кэши соседних ядер?
Из выступления Херба Саттера на рисунке слайдов на странице 2: https://skydrive.live.com/view.aspx?resid=4E86B0CF20EF15AD!24884&app=WordPdf&wdo=2&authkey=!AMtj_EflYn2507c 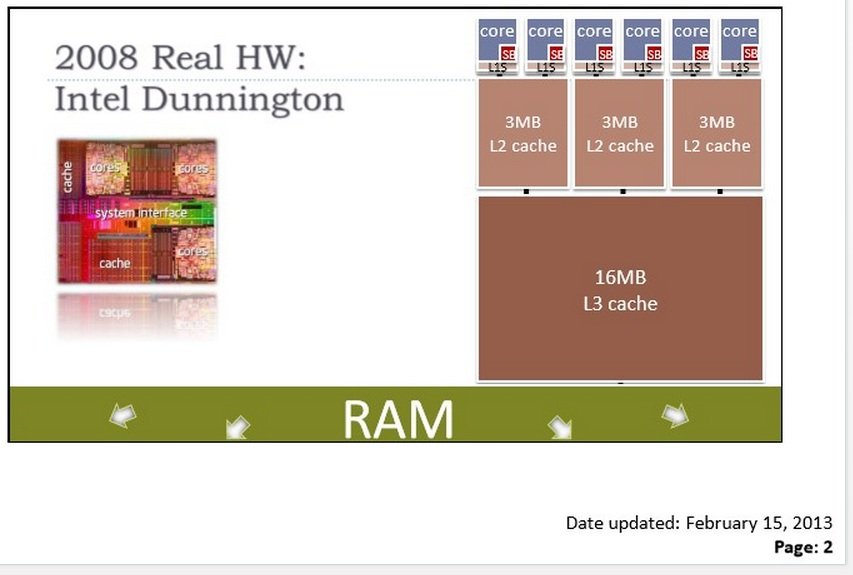
Здесь показаны отдельный кеш- L1S и Store Buffer (SB).
1. В процессорах Intel x86 cache-L1 и Store Buffer - это одно и то же?
И следующий слайд: 
Как мы видим из следующего слайда в x86, это возможно только после переупорядочения. было:
MOV eax, [memory1] / / read
MOV [memory2], edx / / write
... / / MOV, MFENCE, ADD ... any other code
стали:
MOV [memory2], edx / / write
MOV eax, [memory1] / / read
... / / MOV, MFENCE, ADD ... any other code
Это связано с неупорядоченным выполнением в конвейере процессора.
2. Но можете ли вы показать еще один пример, похожий на этот - как это влияет на переупорядочение Store Buffer?
3. И главный вопрос - как влияет LFENCE а также SFENCE на кешах соседних ядер?
Правильно сказать, что:
SFENCEделает "push", т.е. выполняет сброс для Store Buffer->L1, а затем отправляет изменения из кэшей Core0-L1/L2 на все остальные ядра Core1/2/3...-L1/L2?LFENCEделает "тянуть", то есть получает изменения от кэшей всех других Core1/2/3...-L1/L2(и Store Buffer?) в нашем ядре Core0-L1/L2?
1 ответ
Буфер хранилища - это не кеш, это очередь заказов. Он хранит ожидающие хранилища, в то время как кеш можно рассматривать как логическую часть памяти (т. Е. Все в любом из кешей видно всем другим агентам и должно правильно отвечать на отслеживание)
Хранилища не переупорядочены, что нарушило бы порядок памяти, так как они стали бы сразу видны (в отличие от нагрузок, которые влияют только на внутреннее состояние).
заборы не работают на кешах и не имеют ничего общего с другими ядрами. Кэши уже полностью видны и синхронизированы. Заборы применяются только к порядку выполнения (в случае, если это сделано внутренне не по порядку) и, следовательно, применяются только к текущему контексту.
Правильно сказать, что:
- SFENCE делает "push", то есть выполняет сброс для Store Buffer->L1, а затем отправляет изменения из кэшей Core0-L1/L2 на все остальные ядра Core1 / 2/3...- L1 / L2?
- LFENCE "тянет", то есть получает изменения от кешей всех других Core1/2/3...-L1/L2(и Store Buffer?) В нашем ядре Core0-L1/L2?
sfence / mfence будет очищать буфер хранилища, так как они не позволят сохраняться ожидающим спекулятивным хранилищам (вот почему они фехтовают). Однако, как я уже сказал - как только они внесены в L1, они уже кем-то наблюдаемы, их не нужно нигде сбрасывать.
В этом же смысле lfence ничего не "тянет", он просто останавливает выполнение всех младших нагрузок до тех пор, пока более старые (и сам забор) не будут завершены и зафиксированы. Это повлияет на производительность путем сериализации нагрузок, но в противном случае не защитит вас от каких-либо операций с другими ядрами, если только у вас не будет другого способа убедиться, что к тому времени будет выполнено любое необходимое хранилище (и в этом случае - обновить результат загрузки). во время).