Алгоритмы замены страниц виртуальной памяти
У меня есть проект, в котором меня просят разработать приложение для моделирования работы различных алгоритмов замены страниц (с различным размером рабочего набора и периодом стабильности). Мои результаты:




- Вертикальная ось: ошибки страницы
- Горизонтальная ось: размер рабочего набора
- Ось глубины: стабильный период
Являются ли мои результаты разумными? Я ожидал, что LRU будет иметь лучшие результаты, чем FIFO. Здесь они примерно одинаковы.
Для случайного периода стабильности и размера рабочего набора, кажется, не влияет на производительность вообще? Я ожидал, что подобные графики как FIFO & LRU просто худшие показатели? Если эталонная строка очень стабильна (маленькие ветви) и имеет небольшой размер рабочего набора, у нее все равно должно быть меньше ошибок страниц, чем у приложения с большим количеством ветвей и большим размером рабочего набора?
Больше информации
Мой код Python | Вопрос проекта
- Длина эталонной строки (RS): 200000
- Размер виртуальной памяти (P): 1000
- Размер основной памяти (F): 100
- количество обращений к странице времени (м): 100
- Размер рабочего набора (е): 2 - 100
- Стабильность (т): 0 - 1
Размер рабочего набора (e) и стабильный период (t) влияют на то, как генерируется ссылочная строка.
|-----------|--------|------------------------------------|
0 p p+e P-1
Итак, предположим, что выше виртуальная память размера P. Для генерации ссылочных строк используется следующий алгоритм:
- Повторяйте, пока не будет сгенерирована ссылочная строка
- выбирать
mчисла в [p, p+e].mсимулирует или ссылается на количество ссылок на страницу - выбрать случайное число, 0 <= r < 1
- если г <т
- генерировать новый р
- еще (++p)%P
- выбирать
ОБНОВЛЕНИЕ (В ответ на ответ @MrGomez)
Однако вспомните, как вы заполняли входные данные: используя random.random, что дает вам равномерное распределение данных с вашим контролируемым уровнем энтропии. Из-за этого все значения одинаково вероятны, и поскольку вы построили это в пространстве с плавающей запятой, повторения крайне маловероятны.
я использую random, но это также не является абсолютно случайным, ссылки генерируются с некоторой локализацией, хотя использование параметров рабочего размера и ссылочной страницы?
Я пытался увеличить numPageReferenced родственник с numFrames в надежде, что он будет ссылаться на страницу, находящуюся в данный момент в памяти, больше, таким образом показывая преимущество в производительности LRU по сравнению с FIFO, но это не дало мне четкого результата. Просто к вашему сведению, я попробовал то же самое приложение со следующими параметрами (соотношение страниц / фреймов осталось прежним, я уменьшил размер данных, чтобы ускорить процесс).
--numReferences 1000 --numPages 100 --numFrames 10 --numPageReferenced 20
Результат
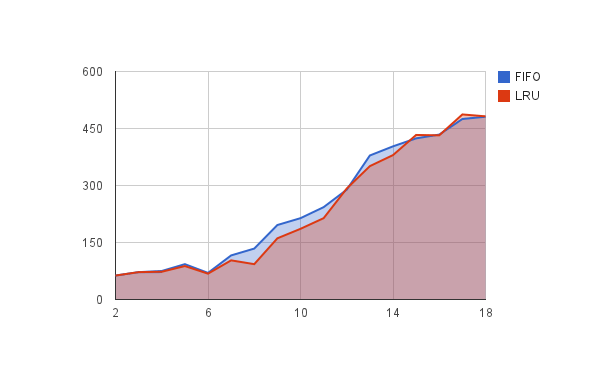
Все еще не такая большая разница. Правильно ли я сказать, если я увеличу numPageReferenced относительно numFramesУ LRU должна быть лучшая производительность, так как он больше ссылается на страницы в памяти? Или, может быть, я что-то неправильно понимаю?
Случайно, я думаю в соответствии с:
- Предположим, есть высокая стабильность и небольшой рабочий набор. Это означает, что ссылки на страницы, скорее всего, будут в памяти. Таким образом, необходимость запуска алгоритма замены страницы ниже?
Хм, может быть, я должен думать об этом больше:)
ОБНОВЛЕНИЕ: уничтожение менее очевидно при более низкой стабильности
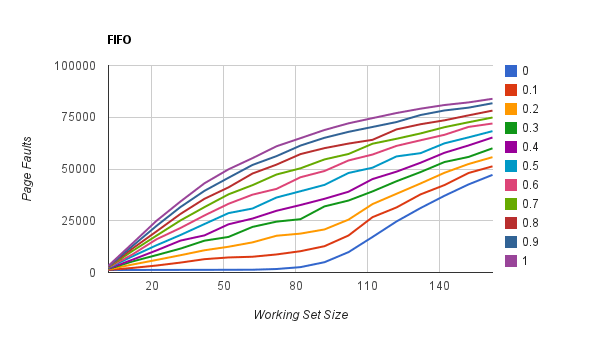
Здесь я пытаюсь показать удаление, поскольку размер рабочего набора превышает количество кадров (100) в памяти. Тем не менее, заметить, что избиение кажется менее очевидным при более низкой стабильности t) почему это может быть? Является ли это объяснением того, что по мере того, как стабильность становится низкой, количество ошибок на странице приближается к максимальному, поэтому не имеет большого значения размер рабочего набора?
1 ответ
Эти результаты являются разумными, учитывая вашу текущую реализацию. Обоснование этого, однако, требует некоторого обсуждения.
При рассмотрении алгоритмов в целом наиболее важно учитывать свойства проверяемых алгоритмов. В частности, обратите внимание на их угловые случаи и лучшие и худшие условия. Вы, вероятно, уже знакомы с этим кратким методом оценки, так что это в основном для тех, кто читает здесь, и может не иметь алгоритмического опыта.
Давайте разберем ваш вопрос по алгоритму и рассмотрим свойства их компонентов в контексте:
FIFO показывает увеличение количества ошибок на странице по мере увеличения размера вашего рабочего набора (ось длины).
Это правильное поведение, согласующееся с аномалией Белади для замены FIFO. По мере увеличения размера вашего рабочего набора страниц количество сбоев страниц также должно увеличиваться.
FIFO показывает увеличение количества ошибок страниц по мере снижения стабильности системы (1 - ось глубины).
Отмечая ваш алгоритм стабильности посева (
if random.random() < stability), ваши результаты становятся менее стабильными по мере приближения стабильности (S) 1. По мере того, как вы резко увеличиваете энтропию в ваших данных, число ошибок страниц также резко увеличивается и распространяет аномалию Белади.Все идет нормально.
LRU показывает соответствие FIFO. Зачем?
Обратите внимание на ваш алгоритм посева. Стандартный LRU наиболее оптимален, когда у вас есть запросы на пейджинг, которые структурированы в меньшие операционные кадры. Для упорядоченных, предсказуемых поисков он улучшает FIFO за счет устаревания результатов, которые больше не существуют в текущем кадре выполнения, что является очень полезным свойством для поэтапного выполнения и инкапсулированной модальной операции. Снова, пока, так хорошо.
Однако, вспомните, как вы посеяли свои входные данные: используя
random.randomТаким образом, вы получаете равномерное распределение данных с вашим контролируемым уровнем энтропии. Из-за этого все значения одинаково вероятны, и поскольку вы построили это в пространстве с плавающей запятой, повторения крайне маловероятны.В результате ваш LRU воспринимает каждый элемент, который происходит небольшое количество раз, а затем полностью отбрасывается при вычислении следующего значения. Таким образом, он корректно отображает каждое значение по мере того, как оно выпадает из окна, обеспечивая производительность, сравнимую с FIFO. Если ваша система правильно учитывает повторяемость или сжатое пространство символов, вы увидите заметно отличающиеся результаты.
В случайном порядке период стабильности и размер рабочего набора, похоже, никак не влияют на производительность. Почему мы видим этот набросок по всему графику вместо того, чтобы дать нам относительно гладкое многообразие?
В случае случайной схемы подкачки вы стохастически удаляете каждую запись. Предположительно, это должно дать нам некоторую форму многообразия, связанного с энтропией и размером нашего рабочего набора... верно?
Или это должно? Для каждого набора записей вы случайным образом назначаете подмножество для вывода на страницу как функцию времени. Это должно дать относительно равномерную производительность подкачки, независимо от стабильности и независимо от вашего рабочего набора, если ваш профиль доступа снова будет равномерно случайным.
Таким образом, исходя из условий, которые вы проверяете, это абсолютно правильное поведение, согласующееся с тем, что мы ожидаем. Вы получаете равномерную производительность подкачки, которая не ухудшается с другими факторами (но, наоборот, не улучшается ими), которая подходит для высокой нагрузки и эффективной работы. Не плохо, просто не то, что вы могли бы интуитивно ожидать.
Итак, в двух словах, это разбивка, так как ваш проект в настоящее время реализуется.
В качестве упражнения для дальнейшего изучения свойств этих алгоритмов в контексте различного расположения и распределения входных данных, я настоятельно рекомендую покопаться в scipy.stats чтобы увидеть, что, например, Гауссово или логистическое распределение может сделать для каждого графа. Затем я хотел бы вернуться к документированным ожиданиям каждого алгоритма и набросать случаи, когда каждый из них уникален наиболее и наименее уместен.
В общем, я думаю, что ваш учитель будет гордиться.:)